Since Delta 2.3, deletion vectors have been available, but only recently have we been able to take full advantage of them to improve the performance of write operations. As of Delta 3.1, all operations support deletion vector optimizations. Fabric customers using Runtime 1.3 (Delta 3.2) can now benefit from much faster writes with very little impact on reads.
What Are Deletion Vectors?
Deletion vectors are an optimization within the Delta format that shifts data changes from a copy-on-write strategy to merge-on-read, aimed at greatly reducing the time to process changes or deletions in Delta tables.
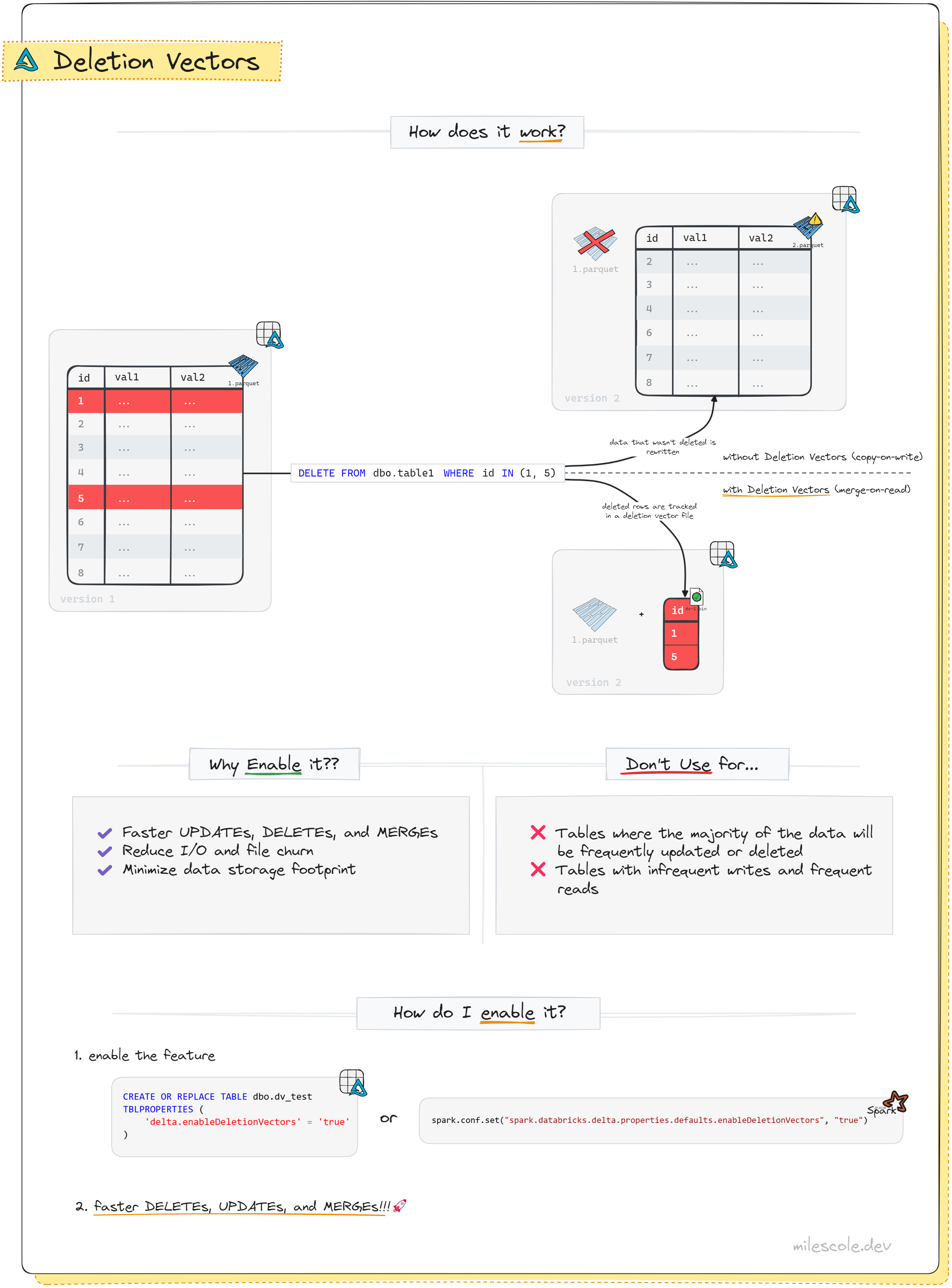
Before I dive into some benchmarks to illustrate why nearly every Fabric customer should be enabling deletion vectors, let’s start by reviewing these core concepts and how the feature works.
Copy-on-Write vs. Merge-on-Read
Copy-on-Write
Copy-on-write is the default write behavior in Delta Lake and has the following behavior: any change to an existing record, whether that is an update or a delete, results in the existing file that contained the record being invalidated, with a new file (or files) being written.
Consider the following scenario where we have a user_data table with a boolean column to signify that an EU user has requested that their data be deleted. The table would have the following structure after creating it via a CTAS operation:
user_data/
├── _delta_log/
│ ├── 00000000000000000000.json
│ └── _commits/
├── _metadata/
│ └── table.json.gz/
└── part-00000-486c5435-19f6-4a1a-be00-ebbac3258b0c-c000.snappy.parquet
Notice that we have one parquet file and one commit in the _delta_log/ folder.
DELETE FROM user_data WHERE gdpr_requested_deletion is True
After running the above code to delete the required user data, the Delta table folder contents would change to the following:
user_data/
├── _delta_log/
│ ├── 00000000000000000000.json
│ ├── 00000000000000000001.json
│ └── _commits/
├── _metadata/
│ └── table.json.gz
├── part-00000-486c5435-19f6-4a1a-be00-ebbac3258b0c-c000.snappy.parquet
└── part-00001-613f4bca-4626-4c16-8498-d9a6ede96af8-c000.snappy.parquet
We now have two files, and if we inspect the latest commit in the _delta_log/ folder, 00000000000000000001.json, we’d find JSON similar to the below, indicating that the first Parquet file has been removed, and another has been added:
{
"remove": {
"path": "part-00000-486c5435-19f6-4a1a-be00-ebbac3258b0c-c000.snappy.parquet",
...
}
}
{
"add": {
"path": "part-00001-613f4bca-4626-4c16-8498-d9a6ede96af8-c000.snappy.parquet",
...
}
}
If we were to inspect the newly added Parquet file, we’d find that it contains all records in the table minus the records that were deleted.
With the copy-on-write behavior, any time that we are changing data within a Parquet file, the existing file must be invalidated, with unchanged data being rewritten into a new file that includes the changed data.
To illustrate the significance: if we had a Delta table with one massive Parquet file containing 1,000,000,000 rows and we delete or update one row, copy-on-write would result in 999,999,999 rows of data being written to a new Parquet file, even though only 1 row is being updated or deleted. While in real-world scenarios, files aren’t usually this large, the example shows that unchanged data in files with changes must be copied, which can have a massive performance impact.
Merge-on-Read
Merge-on-read, implemented as deletion vectors in Delta Lake, avoids rewriting or copying unchanged data and instead delays data merging until read time. Rather than creating a new Parquet file to rewrite unchanged data when data is deleted, the merge-on-read strategy logs the positions of records that have been deleted and filters them out at query time.
Revisiting our case of deleting user data, by using deletion vectors, we would see the following folder contents:
user_data/
├── _delta_log/
│ ├── 00000000000000000000.json
│ ├── 00000000000000000001.json
│ └── _commits/
├── _metadata/
│ └── table.json.gz
├── deletion_vector_7dca5871-aa93-423d-bd1f-490d4263536a.bin
└── part-00000-486c5435-19f6-4a1a-be00-ebbac3258b0c-c000.snappy.parquet
Instead of having a new Parquet file with all data being rewritten, we have a new deletion_vector_....bin file that contains the position of the rows that have been invalidated.
Our new commit would contain the following, where the existing Parquet file reference is removed, and a pointer is added to the same Parquet file with a deletion vector:
{
"add": {
"path": "part-00000-486c5435-19f6-4a1a-be00-ebbac3258b0c-c000.snappy.parquet",
...
"deletionVector": {
"storageType": "u",
"pathOrInlineDv": "ePU0RB8B-wZc{D*N?lcL",
"offset": 1,
"sizeInBytes": 1254624,
"cardinality": 3333334
}
}
}
{
"remove": {
"path": "part-00000-486c5435-19f6-4a1a-be00-ebbac3258b0c-c000.snappy.parquet",
...
}
}
In the example of deleting 1 row from a table with a single Parquet file containing 1,000,000,000 rows, with deletion vectors, we now only record the position of the single row that has been soft-deleted (one very small
.binfile) instead of rewriting a new Parquet file with 999,999,999 rows.
For a more detailed explanation of the Delta Lake consistency model, see Jack Vanlightly’s blog post. Jack’s series of posts compares all major open-source table formats, making it easy to see how similar they are. While this blog post is specific to Delta Lake, Apache Hudi and Iceberg have very similar models for managing writes with a merge-on-read strategy.
What About Updates?
With update operations, the changed record is soft-deleted in the existing Parquet files via a new deletion vector, and then the new version of the changed records is written to a new Parquet file added to the Delta log.
What if I Need to Hard Delete Records?
In both copy-on-write and merge-on-read strategies, the PII data that we were supposed to delete is still technically there, if we were to use Delta’s time travel feature, we could read the data as of the prior commit and be sued for up to €20 million by the EU!
SELECT pii_data FROM user_data VERSION AS OF 0
To hard delete records that have been soft-deleted, we can either wait 7 days and then run VACUUM, or we can change a Spark config to ignore the retention period check and then run a VACUUM operation to clean up the invalidated files.
spark.conf.set("spark.databricks.delta.retentionDurationCheck.enabled", "false")
VACUUM user_data RETAIN 0 HOURS
⚠️ The retention period check should normally be left enabled; this is in place to prevent potential corruption to Delta tables that can occur if VACUUM is run while another writer is writing to the same table.
Perforance Impact of Deletion Vectors
Now that we understand how deletion vectors conceptually work, let’s look at the actual performance impact.
To test the impact, I wrote an identical 100M-row synthetic dataset to two different Delta tables—one with deletion vectors enabled.
import pyspark.sql.functions as sf
data = spark.range(100_000_000) \
.withColumn("id", sf.monotonically_increasing_id()) \
.withColumn("category", sf.concat(sf.lit("category_"), (sf.col("id") % 10))) \
.withColumn("value1", sf.round(sf.rand() * (sf.rand() * 1000), 2)) \
.withColumn("value2", sf.round(sf.rand() * (sf.rand() * 10000), 2)) \
.withColumn("value3", sf.round(sf.rand() * (sf.rand() * 100000), 2)) \
.withColumn("date1", sf.date_add(sf.lit("2022-01-01"), sf.round(sf.rand() * 1000, 0).cast("int"))) \
.withColumn("date2", sf.date_add(sf.lit("2020-01-01"), sf.round(sf.rand() * 2000, 0).cast("int"))) \
.withColumn("is_cancelled", (sf.col("id") % 3 != 0)) \
display(data)
I then ran the following tests to measure the relative and cumulative performance impact:
DELETEto a single rowDELETEto 33% of rowsUPDATEto 8% of rowsMERGEof new dataset containing 5M rows (5%) into the existing tableSELECTstatements (loosely filteredCOUNT(1)andSUM())OPTIMIZEVACUUMwith 0 hours of history retained
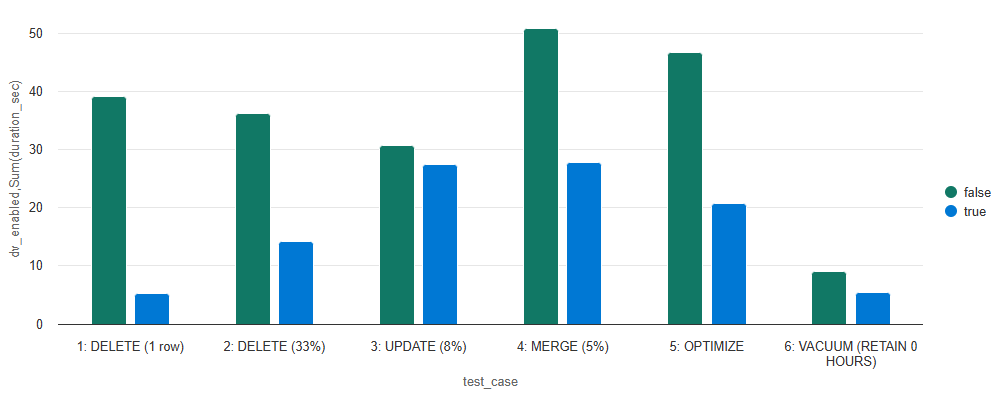
Write Results
Cumulatively, for write and maintenance operations, the table with deletion vectors finished the test 2x faster (212 vs. 101 seconds). Here’s a breakdown of each test case:
- Single Row Delete: Deleting a single row from a 100M-row table was almost 8x faster with deletion vectors enabled.
- As the percentage of total data deleted increases, the performance benefit decreases. However, even when deleting 33% of records, deletion vectors still resulted in a 2.5x performance improvement.
-
Updates: While
UPDATEoperations were faster with deletion vectors, the benefit was less pronounced than with deletes. This is because updates involve not only marking rows as deleted but also writing new versions of the modified records. -
Optimize: The
OPTIMIZEoperation was over 2x faster with deletion vectors enabled due to fewer data files and less data to process. - Vacuum: The
VACUUMoperation was 1.7x faster with deletion vectors enabled for similar reasons—fewer files and smaller data sizes.
Why were OPTIMIZE and VACUUM faster?
To understand why these maintenance operations were faster, I gathered pre-maintenance statistics on the Delta tables. Using the functions below, I calculated the file count and cumulative size of all Parquet files in each table:
def get_path_contents(path: str, recursive: bool = False):
"""
DESCRIPTION:
Retrieves the contents of the selected path either one level or recursively
PARAMETERS:
- path: Path of folder whose contents are being retrieved
- recursive: Flag to select the contents coming from one level or pulling the subfolder contents recursively
RETURNS:
Returns contents of the selected path either recursively or not
"""
files = mssparkutils.fs.ls(path)
for dir_path in files:
if dir_path.isFile:
if recursive:
yield {'path': dir_path.path, 'size': dir_path.size}
else:
return {'path': dir_path.path, 'size': dir_path.size}
elif dir_path.isDir and path != dir_path.path:
if recursive:
yield from get_path_contents(dir_path.path, recursive)
def get_parquet_metrics(path: str) -> dict:
"""
DESCRIPTION:
Retrieves the metrics for any parquet files in the given path
PARAMETERS:
- path: Path in which to look for parquet files to return the metrics for
RETURNS:
Returns dict of the metrics for the parequet files located in the path
"""
try:
files = get_path_contents(path, True)
parquet_files = [file for file in files if file['path'].endswith('.parquet')]
total_size = sum([file['size'] for file in parquet_files])
mega_bytes = round(total_size / (1024 * 1024), 2)
file_count = len([file for file in parquet_files])
return {'bytes': total_size, 'megabytes': mega_bytes, 'file_count': file_count}
except Exception as e:
return {'bytes': None, 'megabytes': None, 'file_count': None}
The results were:
DV Disabled: {'bytes': 8078929924, 'megabytes': 7704.67, 'file_count': 34}
DV Enabled: {'bytes': 2464981802, 'megabytes': 2350.79, 'file_count': 22}
With deletion vectors enabled, the table had 3x less data (in GB) and 1.5x fewer Parquet files. This reduction makes sense: without deletion vectors, every data change required rewriting entire files, whereas with deletion vectors, only the changed data was written. Consequently, both OPTIMIZE and VACUUM operations were faster with deletion vectors, as they processed fewer files and less data overall.
Read Results
Reads are typically expected to be slightly slower with deletion vectors due to the merge-on-read overhead, which requires scanning both the data and the deletion vector files. I found that, after multiple deletes and updates, deletion vectors resulted in cumulative SELECT statements that were 2.3x slower than on tables without deletion vectors.
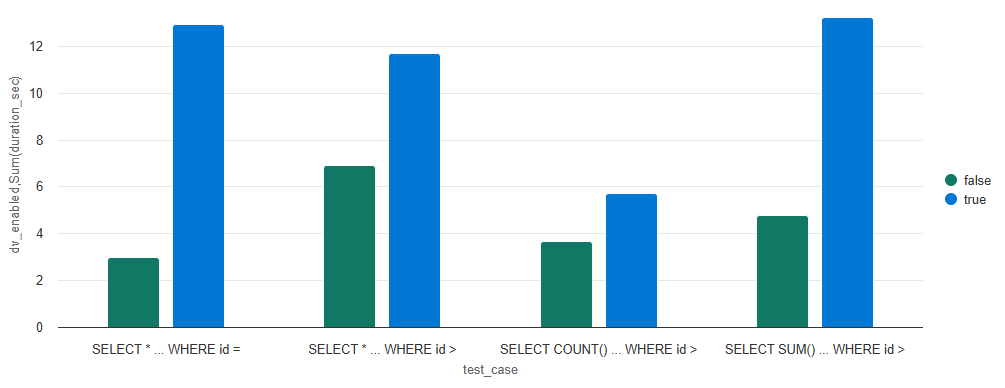
The increased read time occurred because a high percentage of non-append changes (53% of the 100M-row table) were processed without an OPTIMIZE operation to compact data. This scenario is a strong indicator that compaction (OPTIMIZE) should be part of a regular maintenance strategy when deletion vectors are enabled. Without compaction, readers (and writers) must read up to 53% more data, including deleted records, which significantly impacts query time.
In a scenario where only a MERGE of 5M new records was processed, deletion vectors introduced less overhead. Reads were only 1.5x slower compared to the table without deletion vectors.
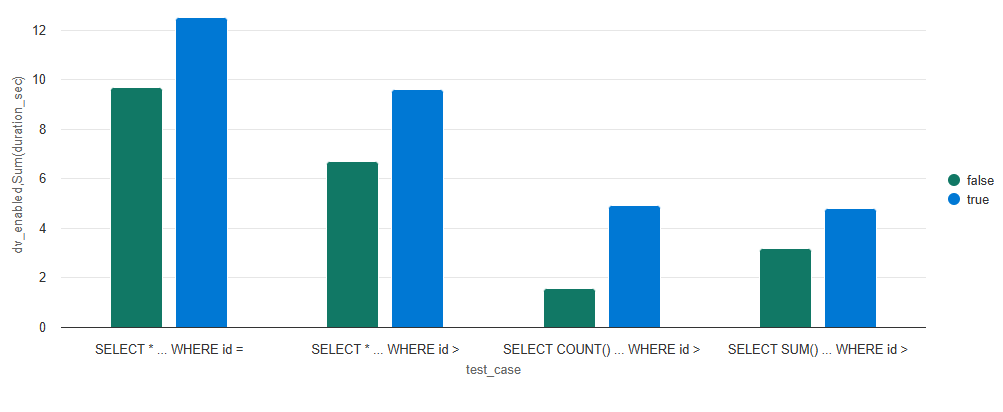
Lastly, let’s consider what would happen if we ran our SELECT statements after performing an OPTIMIZE operation to compact the table following our four merge-on-read write operations. By doing so, the SELECT statements would run in identical time as commpared to the table where deletion vectors were disabled (using copy-on-write) since readers wouldn’t have any deletion vectors to reconcile.
Therefore, if we compare the cumulative processing time—including all write and maintenance operations—the table with deletion vectors enabled would still have the lowest overall processing time.
- With Deletion Vectors: 101 seconds for writes and maintenance + query duration (i.e. 20 seconds)
- Without Deletion Vectors: 212 seconds for writes and mainteance + query duration (i.e. 20 seconds)
This highlights how deletion vectors, combined with strategic use of OPTIMIZE, can reduce the net processing time for workloads with frequent updates and deletes.
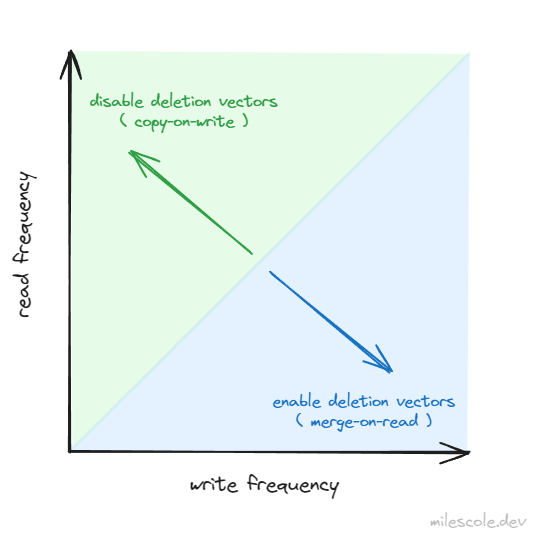
Should I Enable Deletion Vectors?
Deletion vectors are an excellent default configuration for Delta tables provided that a table maintenance strategy is in place. Without a regular strategy for OPTIMIZE and VACUUM, both write and read performance can suffer as deletion vectors accumulate and must be reconciled at read time.
That said, there’s a couple scenarios where you will not want to enable deletion vectors:
-
Infrequent Writes, Frequent Reads: If a table has infrequent writes but frequent reads, deletion vectors may introduce unnecessary read overhead. For example, if you only modify data monthly but run ad-hoc queries daily, it may make more sense to use copy-on-write to avoid merging data on read for every query.
- External Delta Compatibility Requirements: Deletion vectors require Delta Lake version 2.3 or newer, with reader version 3 and writer version 7. This means older readers or tools not yet supporting deletion vectors will encounter compatibility issues.
- Fabric Pipeline COPY Activity: Currently, the COPY activity in Fabric does not support deletion vectors. It will return all active Parquet files without filtering out records included in deletion vectors, meaning deleted or updated data will reappear unless an
OPTIMIZEoperation is run before each COPY activity. Full support for deletion vectors in COPY activities is expected in the next 3-4 months.
How Can I Enable Deletion Vectors?
If you want to enable deletion vectors for all newly created tables within a Spark session or context you can set the below Spark config:
spark.conf.set("spark.databricks.delta.properties.defaults.enableDeletionVectors", "true")
If you want to enable on a table by table basis, you can use the table option when creating tables:
df.write \
.option("delta.enableDeletionVectors", "false") \
.saveAsTable("dbo.dv_enabled_table")
If you want to enable deletion vectors on an existing table, you can do the following:
ALTER TABLE your_table SET TBLPROPERTIES ('delta.enableDeletionVectors' = 'true')
⚠️ Enabling deletion vectors will permanently increase the
minReaderVersionto 3 and theminWriterVersionto 7.
Closing Thoughts
Merge-on-read, implemented through deletion vectors in Delta Lake, is a crucial feature for optimizing write-heavy workloads that involve deletions and updates. While deletion vectors can significantly reduce write times, they require a thoughtful approach to table maintenance. Regular OPTIMIZE and VACUUM operations are essential to ensure a balanced approach to performance across reads and writes.
If you prioritize write performance and can manage regular maintenance, deletion vectors offer substantial benefits.