Proper use of table distributions in Synapse Dedicated SQL Pools is easily the #1 shortcoming in Synapse implementations.
I regularly see large queries that take hours to run (and potentially never even finish) and can almost always get them down to under a few minutes. Table distributions are the #1 thing I look at when tuning Synapse SQL.
Synapse Dedicated SQL Pool Architecture
Dedicated SQL Pools (formerly Azure SQL Data Warehouse) are a massively parallel processing (MPP) implementation of Microsoft SQL built exclusively for analytical workloads (i.e. data warehousing). Under the hood, Dedicated SQL Pools have many separate CPUs that can operate on their distribution of data in parallel. This is what makes Synapse Dedicated SQL Pools so fast and optimized for data warehousing workloads: potentially large operations are broken into many different parallel jobs, orchestrated by a central control node.
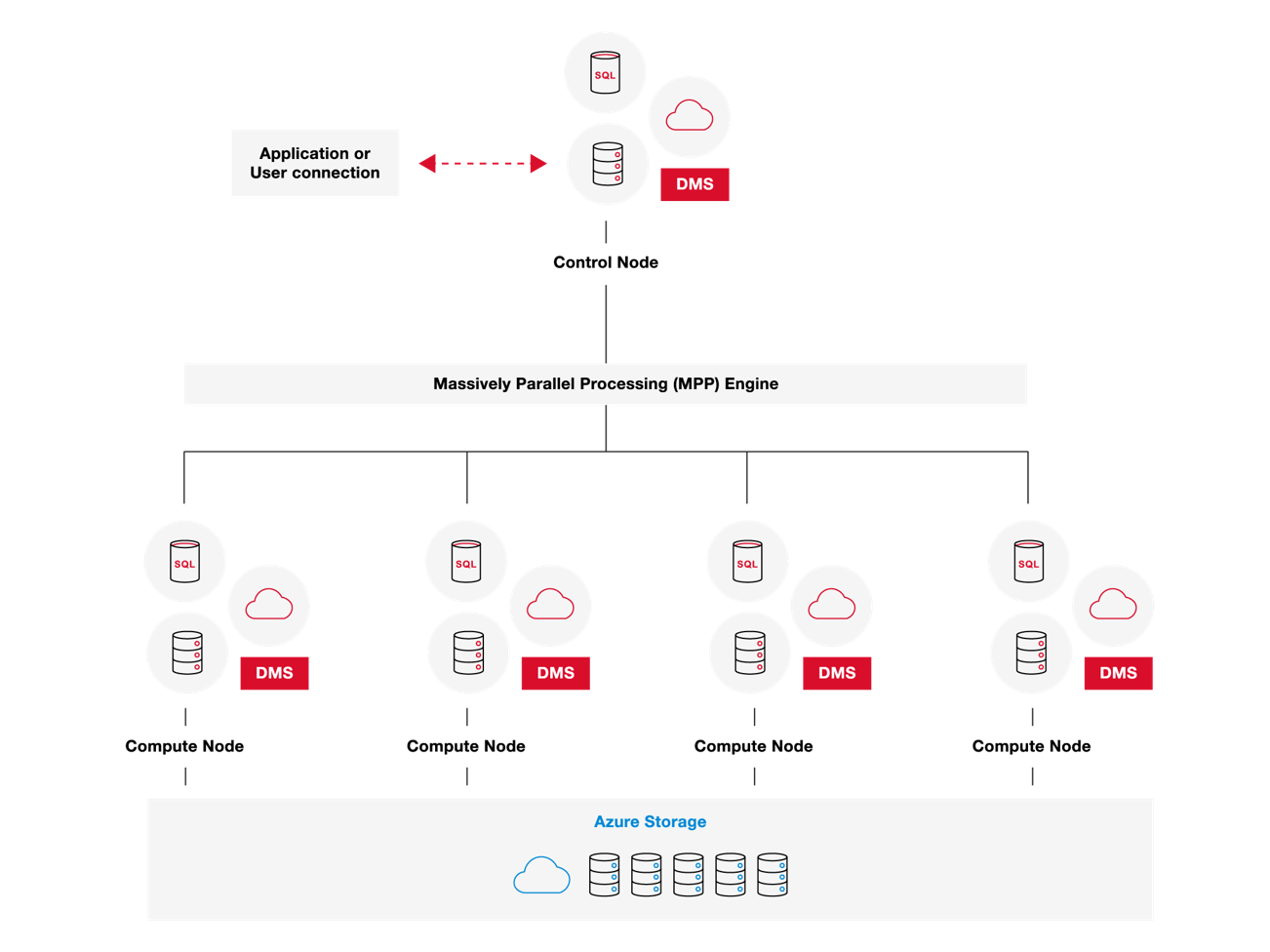 Synapse Dedicated SQL Pool Architecture
Synapse Dedicated SQL Pool Architecture
The biggest architectural differentiator compared to SQL Server is also not so coincidentally the biggest driver of performance compared to SQL Server: Table Distributions.
Table Distributions
The distribution of a table defines how it is physically stored across the 60 distributions (think 60 SQL Databases) that makeup Synapse Dedicated SQL Pools. The massive distribution of data across 60 physical storage layers in which compute can operate on independently allows for potential parallelism of 60. While every job leverages parallel processing, the efficiency in doing so heavily relies on the method in which data is distributed.
Round Robin Distribution
ROUND_ROBIN distribution randomly and evenly distributed data across the 60 distributions. This has the advantage of fast writes, an absence of data skew, and no need to understand the underlying data and related query patterns.
1
2
3
4
5
6
CREATE TABLE dbo.table1
WITH (
CLUSTERED COLUMNSTORE INDEX
, DISTRIBUTION = ROUND_ROBIN
)
AS SELECT 1
The key disadvantage of ROUND_ROBIN distribution is that join operations involving the table will require data shuffling or broadcasting from distribution to distribution, a.k.a., data movement. The more data movement taking place to complete a SQL operation the longer it will run. Sometimes this is unavoidable, or with small lookup tables, tends to have diminishing or even negligible returns.
Joining a ROUND_ROBIN distributed table with any other table will result in data movement to complete the operation because there is no guarantee (or even likelihood) that the common data required to perform the join exists on the same distribution, therefore the optimizer must choose to either broadcast or shuffle the data.
Synapse Dedicated SQL Pools use a cost-based query optimizer, where the cost of different methods to return the results is calculated and the lowest cost plan is selected to run.
1
2
3
4
SELECT *
FROM dbo.OrderLines ol
JOIN dbo.Product p
ON ol.ProductId = p.ProductId
|
dbo.OrderLines (DISTRIBUTION = ROUND_ROBIN)
|
dbo.Product (DISTRIBUTION = ROUND_ROBIN)
|
Notice that in the dbo.OrderLines table ProductId 2 exists in distribution 1 whereas in the dbo.Product table, ProductId 2 exists in distribution 2, it cannot return the result of the join at the distribution level. To return the results when data is not collocated, it will do one or multiple of 2 operations:
- A Broadcast Move operation could take place to create a temporary table replicating all dbo.Product data to each of the 60 distributions. This effectively will temporarily multiply your dbo.Product storage footprint by 60x to meet the needs of this query. The larger the dataset being broadcasted the most expensive this operation is.
- Two Shuffle Move operations could take place to create temporary tables reorganizing all dbo.Product and dbo.OrderLines data to be HASH distributed on ProductId, thus allowing data to be joined locally at each of the 60 distributions.
For this particular query the optimizer will select to Broadcast Move or Shuffle Move both datasets depending on table sizes.
Hash Distribution
The most efficient way to return the query results in this example would be to first alter the distribution of both dbo.OrderLines and dbo.Product tables to be HASH distributed on ProductId. Hash distributing a table passes the selected column (or multiple columns) values through a hashing algorithm which assigns a deterministic distribution to each distinct value. Every row that has the same hash column value is guaranteed to be physically stored on the same distribution, even for the same value contained in multiple tables. This would result in the following:
|
dbo.OrderLines (DISTRIBUTION = HASH(ProductId))
|
dbo.Product (DISTRIBUTION = HASH(ProductId))
|
Notice how ProductId 2 in both tables is now located in distribution 2. The optimizer will recognize that both tables are distributed on the same column which is present in the SELECT statement join condition (ol.ProductId = p.ProductId). This will result in a 100% local distribution level join taking place and will be incredibly fast.
Replicate Distribution
REPLICATE distribution is stored at the distribution level as ROUND_ROBIN, however, the data is replicated to each compute node after the first time the data is accessed. Think of this as a persisted compute node cache that can eliminate the need to broadcast move data in order to perform joins. See the Synapse Service Levels Documentation for details on how many compute nodes exist per Synapse SKU.
REPLICATE distribution is typically appropriate for dimension tables which can’t be HASH distributed on the same column as fact tables. Since each compute node will have the full table needed to perform the join, operations to broadcast move the table to join with larger facts can typically be eliminated.
Rebuilding Replicated Tables
Replicated tables are rebuilt asynchronously by the first query against the table after:
- DML operations (INSERT/UPDATE/DELETE)
- The Synapse SQL instance is scaled to a level with a different number of compute nodes
- The table definition is updated
⚠️ REPLICATE distribution should be avoided in the following cases:
- Tables w/ more than 1M rows or 2GB of compressed data (the less frequently the underlying data changes the more you can exceed this threshold).
- Tables w/ frequent DML operations (i.e. DELETE/INSERT/UPDATE). Only one replicated table can be rebuilt at a given time so frequent table updates can lead to queuing of tables waiting to be rebuilt.
- SQL Pools with frequent scale operations that change the number of compute nodes.
- Tables with many columns where only a small subset are typically accessed.
TPC-DS 10x Scale Example
Now that we have the core concepts, let’s look at a closer to real-world example with a CTAS (CREATE TABLE AS SELECT) statement.
See my AzureSynapseUtilities Repo for scripts used to create the TPC-DS datasets for Synapse Dedicated Pools.
| Table | Row Count |
|---|---|
| tpcds.inventory | 133,110,000 |
| tpcds.store_sales | 28,800,501 |
| tpcds.item | 102,000 |
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
CREATE TABLE dbo.inventory_summary
WITH (
CLUSTERED COLUMNSTORE INDEX
, DISTRIBUTION = ROUND_ROBIN
) AS
SELECT inv_item_sk
, inv_warehouse_sk
, i_product_name
, AVG(inv_quantity_on_hand) AS avg_on_hand_inventory
, MAX([ss_sales_price]) AS max_sell_price
, MIN([ss_sales_price]) AS min_sell_price
FROM tpcds.inventory /*DISTRIBUTION = ROUND_ROBIN*/
JOIN tpcds.item /*DISTRIBUTION = ROUND_ROBIN*/
ON inv_item_sk = i_item_sk
JOIN [tpcds].[store_sales] /*DISTRIBUTION = ROUND_ROBIN*/
ON inv_item_sk = ss_item_sk
GROUP BY i_product_name
, i_item_sk
, inv_warehouse_sk
While this SQL is very readable, the Synapse Optimizer tends to be very literal in terms of executing plans based on how your TSQL reads, I don’t find that it is as creative as regular SQL Server with finding alternate and more optimal plans. This is extremely important with the MPP architecture because depending on how your SQL is written, you could be getting worse performance when migrating from SQL Server to Synapse Dedicated Pools and a simple reorganization of some SQL could produce much better utilization of the distributed compute and the table distributions.
Notice in the below query plan how the Group by Aggregates transformation takes place after the 3 tables are shuffled and joined.
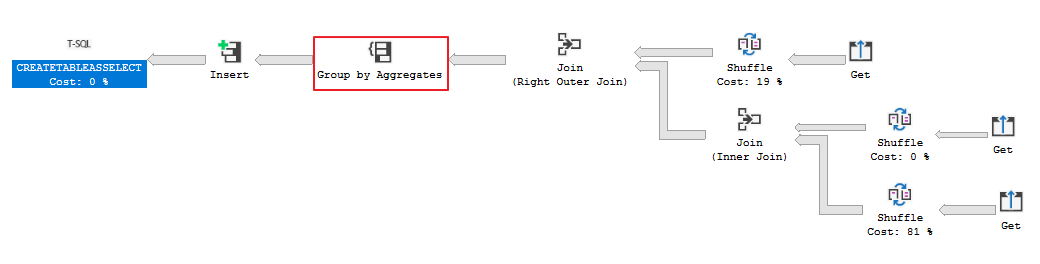
Running this statement producing ~ 1M rows took ~ 1 hour 55 minutes on DW100c (smallrc with no other jobs running)
Ideally, since we are performing aggregates that are not dependent on the joining tables, I’d expect the Group by Aggregates step to take prior before the 3 tables are shuffled and joined as this would result in dramatically less data being moved.
In the below SQL I rewrote the aggregations to take place as sub-queries to try and force the optimizer to perform these aggregations before data is joined, again - the optimizer tends to be very literal.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
CREATE TABLE dbo.inventory_summary
WITH (
CLUSTERED COLUMNSTORE INDEX
, DISTRIBUTION = ROUND_ROBIN
) AS
SELECT inv.inv_item_sk
, inv.inv_warehouse_sk
, i_product_name
, inv.avg_on_hand_inventory
, ss.max_sell_price
, ss.min_sell_price
FROM (
SELECT inv_item_sk
, inv_warehouse_sk
, AVG(inv_quantity_on_hand) AS avg_on_hand_inventory
FROM tpcds.inventory /*DISTRIBUTION = ROUND_ROBIN*/
GROUP BY inv_item_sk
, inv_warehouse_sk
) inv
JOIN tpcds.item /*DISTRIBUTION = ROUND_ROBIN*/
ON inv.inv_item_sk = i_item_sk
JOIN (
SELECT ss_item_sk
, MAX([ss_sales_price]) AS max_sell_price
, MIN([ss_sales_price]) AS min_sell_price
FROM tpcds.store_sales /*DISTRIBUTION = ROUND_ROBIN*/
GROUP BY ss_item_sk
) ss
ON i_item_sk = ss.ss_item_sk
Notice that there are now multiple Group by Aggregates steps taking place but they all occur before tables are joined and 1/2 are taking place before any data is shuffled… thus vastly cutting down the total size of data moved and joined to return results.

Running this statement producing ~ 1M rows took 1 minute on DW100c, a 155x performance improvement
The optimizer calculated that 81% of the statement cost is related to reorganizing the post-aggregation rows of the tpcds.inventory table.
Since the tables are joining on the item_sk column we can infer that the optimizer is planning to shuffle these tables on this column. We can confirm this by looking at the D-SQL plan by putting EXPLAIN at the start of the query and running it, unfortunately, outputs XML which is visually difficult to interpret.
The key portion of the very paired-down XML plan below is the SHUFFLE_MOVE dsql_operation and the shuffle_columns element, this highlights that the underlying data will be shuffled on the _item_sk columns:
1
2
3
4
5
6
7
8
9
10
11
<dsql_operation operation_type="SHUFFLE_MOVE">
<operation_cost cost="22.032" accumulative_cost="22.032" average_rowsize="54" output_rows="102000" GroupNumber="20" />...
<shuffle_columns>i_item_sk;</shuffle_columns>
<dsql_operation operation_type="SHUFFLE_MOVE">
<operation_cost cost="8.1419184" accumulative_cost="30.1739184" average_rowsize="22" output_rows="92521.8" GroupNumber="53" />...
<shuffle_columns>ss_item_sk;</shuffle_columns>
</dsql_operation>
<dsql_operation operation_type="SHUFFLE_MOVE">
<operation_cost cost="81.6" accumulative_cost="111.7739184" average_rowsize="20" output_rows="1020000" GroupNumber="39" />...
<shuffle_columns>inv_item_sk;</shuffle_columns>
</dsql_operation>
If we were to change the distribution of all tables to be HASH distributed on the item_sk in each table before running our statement, we will continue to improve our results. We can use the stored procedure below to easily make these changes, the procedure can be found in my AzureSynapseUtilities Repo
1
2
3
EXEC dbo.AlterTableDistribution 'tpcds', 'item', 'HASH(i_item_sk)'
EXEC dbo.AlterTableDistribution 'tpcds', 'inventory', 'HASH(inv_item_sk)'
EXEC dbo.AlterTableDistribution 'tpcds', 'store_sales', 'HASH(ss_item_sk)'
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
CREATE TABLE dbo.inventory_summary
WITH (
CLUSTERED COLUMNSTORE INDEX
, DISTRIBUTION = ROUND_ROBIN
) AS
SELECT inv.inv_item_sk
, inv.inv_warehouse_sk
, i_product_name
, inv.avg_on_hand_inventory
, ss.max_sell_price
, ss.min_sell_price
FROM (
SELECT inv_item_sk
, inv_warehouse_sk
, AVG(inv_quantity_on_hand) AS avg_on_hand_inventory
FROM tpcds.inventory /*DISTRIBUTION = HASH(inv_item_sk)*/
GROUP BY inv_item_sk
, inv_warehouse_sk
) inv
JOIN tpcds.item /*DISTRIBUTION = HASH(i_item_sk)*/
ON inv.inv_item_sk = i_item_sk
JOIN (
SELECT ss_item_sk
, MAX([ss_sales_price]) AS max_sell_price
, MIN([ss_sales_price]) AS min_sell_price
FROM tpcds.store_sales /*DISTRIBUTION = HASH(i_item_sk)*/
GROUP BY ss_item_sk
) ss
ON i_item_sk = ss.ss_item_sk
Notice that the resulting query plan below doesn’t have any broadcast or shuffle move operations.

Running this statement took ~ 12 seconds on DW100c, a 5x improvement from the prior change
Good improvement but we aren’t done. We could distribute the target table (dbo.inventory_summary) on the same item_sk to completely avoid data leaving each individual distribution. While the prior query plan eliminates data movement to produce the result set, it must return the results to the compute node(s) so that the data can be ROUND_ROBIN distributed. The below will result in 0 data movement, all operations take place solely on each of the 60 distributions, all in parallel.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
CREATE TABLE dbo.inventory_summary
WITH (
CLUSTERED COLUMNSTORE INDEX
, DISTRIBUTION = HASH (inv_item_sk)
) AS
SELECT inv.inv_item_sk
, inv.inv_warehouse_sk
, i_product_name
, inv.avg_on_hand_inventory
, ss.max_sell_price
, ss.min_sell_price
FROM (
SELECT inv_item_sk
, inv_warehouse_sk
, AVG(inv_quantity_on_hand) AS avg_on_hand_inventory
FROM tpcds.inventory /*DISTRIBUTION = HASH(inv_item_sk)*/
GROUP BY inv_item_sk
, inv_warehouse_sk
) inv
JOIN tpcds.item /*DISTRIBUTION = HASH(i_item_sk)*/
ON inv.inv_item_sk = i_item_sk
JOIN (
SELECT ss_item_sk
, MAX([ss_sales_price]) AS max_sell_price
, MIN([ss_sales_price]) AS min_sell_price
FROM tpcds.store_sales /*DISTRIBUTION = HASH(i_item_sk)*/
GROUP BY ss_item_sk
) ss
ON i_item_sk = ss.ss_item_sk
Estimated query plans do now show or calculate data movement for inserting into tables (i.e. CTAS) so the plan will look identical to the prior.
Running this statement took ~ 8 seconds on DW100c, a 1.5x improvement from the prior change
This query now runs 862x faster than where we started!
Selecting the right distribution
Picking the ideal distribution can be difficult, especially the more complex the query is, you will have to pick and choose to eliminate the most costly data movement and consider what makes sense for your most common queries involving tables.
Here’s some guidance for picking the right distribution column:
- Look at the join conditions for common columns
- Prioritize tables that have the biggest cost impact to query plans
- When running CTAS, INSERT, or even UPDATE statements, consider the distribution of the target table you are updating, inserting into, or creating. If you can align both your source table(s) and target table on the same distribution column you will minimize data movement to transform and land your data.
Quickly changing distributions
I created the stored procedure below to simplify the process of altering the distribution of any table. It compresses ~ 9 lines of TSQL to 1 and will re-implement the same table index.
Happy tuning!