Something I’ve always found challenging in PaaS Spark platforms, such as Databricks and Microsoft Fabric, is efficiently leveraging compute resources to maximize parallel job execution while minimizing platform costs. It’s straightforward to spin up a cluster and run a single job, but what’s the optimal approach when you need to run hundreds of jobs simultaneously? Should you use one large high-concurrency cluster, or a separate job cluster for each task?
Coming from the relational database world, things seem simpler, largely because compute and storage are tightly integrated within a single service, supported by decades of investment in workload management mechanisms. These include built-in queues, resource governors, and algorithms for resource allocation, enabling an ideal balance between concurrent execution and performance.
Introducing the flexible paradigm of decoupled compute and storage, along with Delta Lake, which offers many foundational features of RDBMS systems like ACID transactions (Atomicity, Consistency, Isolation, and Durability), we can now surpass the limitations and constraints of traditional data warehousing. This includes scalability, cost, flexibility, and extensibility. However, this great flexibility comes with exponentially more settings to adjust and numerous different methods to achieve the same end result, making it easy to inefficiently use compute resources and inadvertently increase the cost of running a lakehouse, despite cost savings being a primary motivation for the lakehouse movement.
The goal of this post is to share some of the lessons I’ve learned about efficiently using compute in Spark, specifically regarding cluster configuration and orchestration patterns.
Methods for Parallel Spark Orchestration
1. Running Many Jobs on a Single High-Concurrency Cluster
Initially, it seems logical to emulate the RDBMS approach: run many different notebooks or Spark jobs on one large cluster, similar to how you might want to fire off many stored procedures at one time and allow the internal workload management features to run the show. While this may work for a small number of concurrent jobs, increased concurrency without properly scaling out your worker nodes and scaling up your driver node leads to:
- Dramatically longer execution times for all tasks, even simple commands.
- Failures in Spark and Python initialization phases (e.g.,
Failure starting REPL).
These issues arise due to the inherent characteristics of high-concurrency clusters:
- Concurrency Limited by Executors/Workers: In environments like Databricks and Fabric, as opposed to open-source Spark, the number of executors is directly tied to the number of workers; a cluster with 4 workers equates to having 4 executors. This configuration limits the ability to run concurrent operations, as each executor is dedicated to a single job. Consequently, attempting to run 8 notebooks on a 4-worker cluster results in half of the notebooks being queued until an executor becomes available.
- Shared Driver Node Becomes a Bottleneck: Contrary to the distinct driver-executor model in open-source Spark, platforms like Databricks and Fabric utilize a shared driver across all jobs in a high-concurrency cluster. All operations are executed through a single JVM, which can quickly become overwhelmed by resource demands. Enhancing the driver’s memory allocation may provide temporary relief; however, the overhead associated with managing multiple concurrent notebooks on a single cluster is significant. Each notebook requires the initialization of a Spark REPL (‘Read-Eval-Print-Loop’), and without a mechanism to queue REPL initialization requests, the cluster may encounter initialization failures (e.g.,
Failure starting REPL) under resource pressure. - Non-Shared Resources Within Executors: Consider the scenario of executing a
VACUUMcommand on multiple Delta tables within a notebook. Given that VACUUM is primarily an I/O-bound operation—focused on file management tasks like listing, checking, and deleting files—the CPU resources within the executor are underutilized. Despite this, the resources allocated to the executor are fully reserved for the operation, highlighting a potential inefficiency in resource utilization for certain types of operations.
Moreover, high-concurrency clusters in Databricks incur higher licensing costs than job clusters as they are intended for shared compute usage among multiple users.
2. Dedicated Job Cluster for Each Job
Looking to solve for the disadvantages of running many jobs on one high-concurrency cluster, naturally I found myself running only one single job on a right-sized (usually small and often single node) job cluster. This approach offers several advantages:
- Elimination of Resource Contention: By dedicating a cluster to each job, resource conflicts between jobs are avoided, ensuring that each job has access to the resources it requires without interference from others.
- Dynamic Cluster Sizing: Clusters can be tailored to the specific demands of each job, allowing for larger clusters to handle extensive tasks and smaller clusters for less demanding jobs. This flexibility ensures efficient resource utilization.
- Lower Licensing Costs: Utilizing dedicated clusters for each job can reduce expenses associated with licensing for high-concurrency features, as clusters are scaled according to the job size rather than maintaining a large, high-concurrency environment.
Despite its benefits, this model introduces its own set of challenges:
- Infrastructure quotas: A key premise of this approach is the cost-efficiency of running multiple VMs simultaneously—e.g., running 60 VMs for one minute costs the same as running one VM for an hour. However, this strategy is constrained by the available VM quota in the chosen cloud region, which may not support the instantaneous provisioning of thousands of VMs.
- Complex Cost Estimations: Accurately predicting costs becomes more challenging, as it necessitates advanced calculations to account for the dynamic sizing of clusters and the varying durations of job executions.
- Risk of Underutilized Compute Resources: When each job runs on its dedicated compute resources without the possibility of sharing, there’s a risk that even minor tasks might not fully utilize the allocated resources. For instance, a small job running on a single-node, 4-core cluster might not use all available computing power, leading to inefficiencies.
What have we learned so far?
Having implemented the above methods, there’s some clear lessons to be learned here:
- Strategic Resource Allocation: Both approaches highlight the need for strategic resource allocation and management, tailored to the specific demands of the jobs and the overall data processing goals.
- Limited Resource Sharing (memory, CPU, network, etc.): Both approaches show that a lack of sharing of resources across jobs is an inefficiency since one task not requiring a lot of compute (within an executor or cluster) cannot be used by other tasks.
This now brings us to the last method I’ll discuss…
3. Multithreading for Concurrent Job Execution in Clusters
This approach, which certainly not free from disadvantages, can be the most efficient for executing multiple jobs in parallel.
The concept involves utilizing one or several job clusters to execute numerous jobs concurrently through multithreading. This can be achieved by either statically or dynamically setting the number of threads (concurrency), all operating under a single Spark session.
The primary disadvantage here is the barrier to entry as you have to learn the fundamentals of one of the threading libraries in python or scala. If you’re using Microsoft Fabric, there is a new mssparkutils command (mssparkutils.notebook.runMultiple()) that can simplify some uses cases for concurrent processing, my colleague over at Fabric.guru has an excellent blog post on this command. Note that this requires some initialization time for each notebook so there is still overhead to this approach.
Before we dive in to some ways to implement and key things to know about each, let’s be clear why we are only talking about multithreading rather than multi-processing.
Why Multithreading Over Multiprocessing?
Multithreading shares resources within the compute environment, constrained by mechanisms like the Python Global Interpreter Lock (GIL), which allows only one Python task to execute at a time. This approach is compatible with Spark’s architecture, unlike multiprocessing, which creates resource boundaries that are incompatible with Spark’s processing framework.
In computing, a thread can be likened to a section of musicians within an orchestra. Just as musicians share the stage, instruments, and sheet music, threads share the resources of a single computing environment, including memory and processing power. This shared environment is orchestrated by the Python Global Interpreter Lock (GIL), akin to a conductor in an orchestra. The GIL ensures that, despite the shared resources, only one thread (or section) performs at any given moment. However, much like a skilled conductor who seamlessly directs different sections of the orchestra to play in harmony, the GIL allows for efficient task switching. When one thread awaits an I/O operation to complete (i.e. reading from a source, or writing to blob storage), another thread can take the spotlight, ensuring a continuous and harmonious performance without skipping a beat.
In contrast, a process operates like an entire orchestra, complete with its own stage, instruments, and conductor. Each process is a self-contained unit with dedicated resources, such as memory and CPUs, allowing it to perform independently of others. This independence means that resources are not shared between processes, mirroring how separate orchestras do not share their musicians or conductors. While each orchestra (process) can produce a magnificent performance on its own, the lack of shared resources means they operate in isolation, without the intertwined coordination found within the sections of a single orchestra (threads within a process).
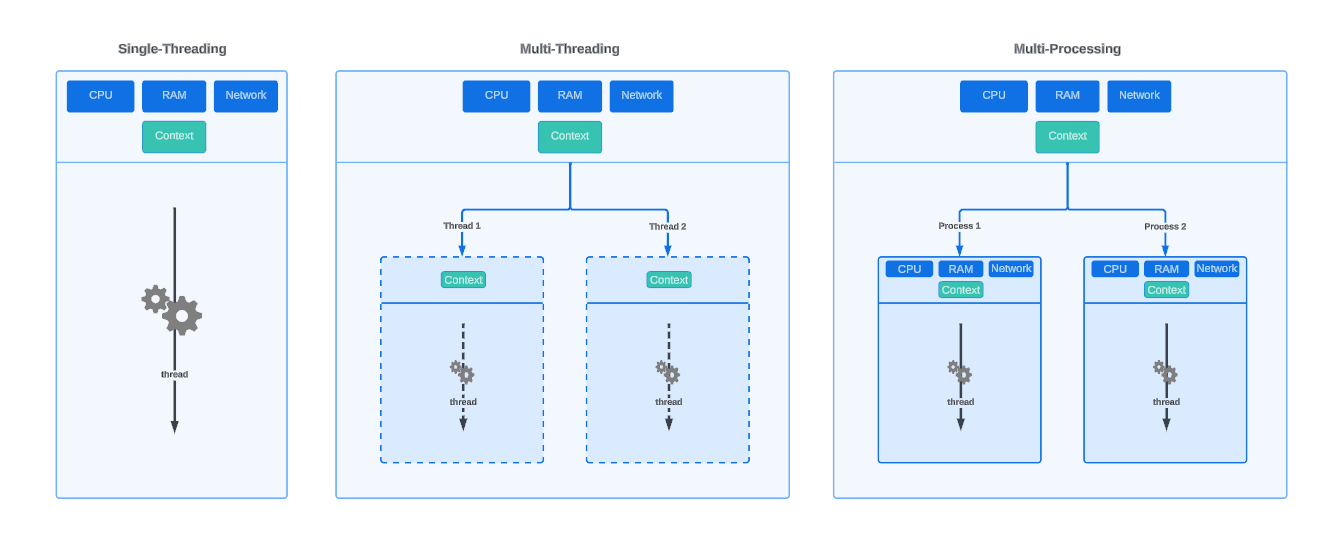 Mulithreading vs. Multiprocessing
Mulithreading vs. Multiprocessing
Threading Library
The Threading module in Python allows for the creation, synchronization, and management of threads. It offers a more manual approach to thread management.
Syntax Example
import threading
import time
# Example job function
def job(job_id):
print(f"Starting job {job_id}")
time.sleep(10) # Simulate a task
print(f"Finished job {job_id}")
# Total jobs to execute
total_jobs = 8
# Maximum number of concurrent jobs
max_concurrency = 4
# List to keep track of threads
threads = []
# Queue to manage job IDs
job_queue = list(range(total_jobs))
while job_queue or threads:
# Start threads until max concurrency or no more jobs
while len(threads) < max_concurrency and job_queue:
job_id = job_queue.pop(0) # Get a job ID from the queue
thread = threading.Thread(target=job, args=(job_id,))
thread.start()
threads.append(thread)
# Check for completed threads and remove them
threads = [t for t in threads if t.is_alive()]
# If max concurrency reached, wait a bit before checking threads again
if len(threads) == max_concurrency:
time.sleep(0.1)
# Wait for all threads to complete
for t in threads:
t.join()
Pros:
- Fine-grained control of threads.
- Direct manipulation of threads, allowing for custom behaviors and management.
Cons:
- Manual management of threads and their lifecycle.
- No built-in support for cancelling or terminating threads
- Handling synchronization and potential race conditions requires careful design.
- The Python GIL limits execution speedups in CPU-bound tasks.
Conccurent.Futures Library
The concurrent.futures module provides a high-level interface for asynchronously executing callables. The ThreadPoolExecutor is particularly useful for I/O-bound tasks. ProcessPoolExecutor is going to be more efficient for CPU-bound tasks as it executes multiple processes in parallel, however, this is incomatible with Spark since spark itself is a parallel processes framework.
Syntax Example
import concurrent.futures
import time
# Example job function
def job(job_id):
print(f"Starting job {job_id}")
time.sleep(10) # Simulate a task
print(f"Finished job {job_id}")
return f"Job {job_id} completed."
# Total jobs to execute
total_jobs = 8
# Maximum number of concurrent jobs
max_concurrency = 4
# Use ThreadPoolExecutor to manage concurrency
with concurrent.futures.ThreadPoolExecutor(max_workers=max_concurrency) as executor:
# Submit all jobs to the executor
futures = [executor.submit(job, job_id) for job_id in range(total_jobs)]
# As each job completes, you can process its result (if needed) in the order they are completed
for future in concurrent.futures.as_completed(futures):
print(future.result())
Pros:
- Simplified thread management compared to the threading module.
- Easy to use API for handling concurrent executions.
- Suitable for I/O-bound and high-latency tasks.
- Out-of-the-box cancellation of threads that have not started with cancel() method.
Cons:
- Still subject to the limitations of the GIL; not ideal for CPU-bound tasks.
- No built-in support for canceling threads that have already started.
Important Considerations When Using Multithreading
Whether you use Threading or Concurrent.Futures (I recommend the latter), it is important to consider the lifecycle management of threads.
-
Canceling jobs: Suppose you execute a notebook cell with a
time.sleep(3600)command (waiting for 1 hour) in each thread and attempt to cancel the cell execution. In that case, the operation will continue until each thread completes. Concurrent.Futures supports canceling threads that haven’t started yet, provided your code invokes thecancel()method on all futures upon a KeyboardInterruption event. However, all active threads will persist until thetime.sleep(3600)concludes—either after an hour or when you terminate or detach the notebook. As an alternative, consider implementing a flagging mechanism that periodically checks within each thread if a KeyboardInterruption (cancel button) has been activated externally, subsequently raising an exception if triggered. -
Thread Status: Given that threads may run for extended periods, particularly in ELT jobs, it’s useful to communicate their status. This can be achieved in various ways, with Rich.Progress being a the most robust option due to its extensive customization options for displaying each thread’s progress within the notebook cell output.
⚠️ Rich.Progress and Microsoft Fabric notebooks are currently not compatible. If you are using Databricks notebooks, Rich.Progress works flawlessly.
Efficiency Comparison
To demonstrate the potential efficiency gains, I conducted a simple experiment involving reading 1M rows from a Databricks sample Delta table and subsequently writing the dataframe to a new Delta table, utilizing a single-node, 4-core cluster (with 1 core dedicated to the driver and the remaining 3 as workers).
import uuid
import concurrent.futures
job_count = 12
def read_and_write_table():
uid = str(uuid.uuid4())
uid = uid.replace('-','')
df = spark.sql("SELECT * FROM sample.tpcs.lineitem limit 1000000")
df.write.format("delta").saveAsTable(f"test.{uid}")
with concurrent.futures.ThreadPoolExecutor() as executor:
futures = [executor.submit(read_and_write_table) for i in range(job_count)]
for future in concurrent.futures.as_completed(futures):
print(future.result())
This test was not performed on High-Concurrency clusters, as high-concurrency cannot be enabled on single-node clusters.
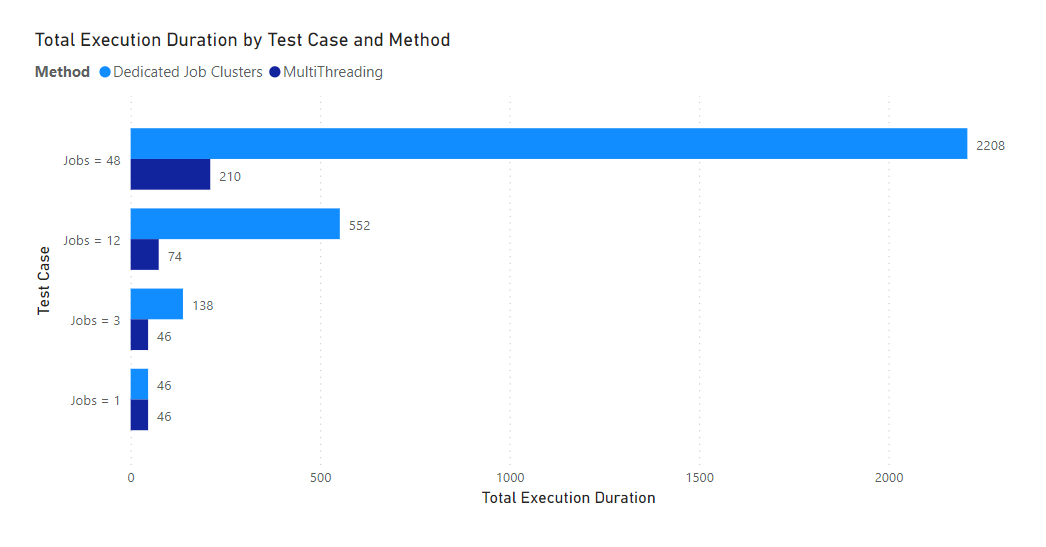 Dedicated Job Clusters vs. Multithreading
Dedicated Job Clusters vs. Multithreading
When running 48 jobs, multithreading took 9.5% of to total cluster execution duration compared to running dedicated job clusters for each job! This test highlights how there is considerable overhead to starting a spark application even after the compute is already allocated.
For the multithreading tests I used the default max_workers setting
min(32, os.cpu_count() + 4)which returns 8 on a 4 core single node cluster. This enabled 8 concurrent threads.
Final Thoughts
Multithreading is certainly not a one size fit all approach, however when it comes to orchestrating a high volume of lakehouse processes, if you can integrate robust logging, monitoring, and metadata-driven orchestration, it can definately be the most efficient and cost effective mechanism to use.