Since its introduction, Unity Catalog has been creating significant buzz in the data community. But what exactly is it, and why is enabling it in your Databricks workspace so important? This article dives into the essence of Unity Catalog, demonstrating how it revolutionizes data engineering in lakehouses and provides guidelines for enabling it in your existing Databricks Workspace.
Understanding Unity Catalog
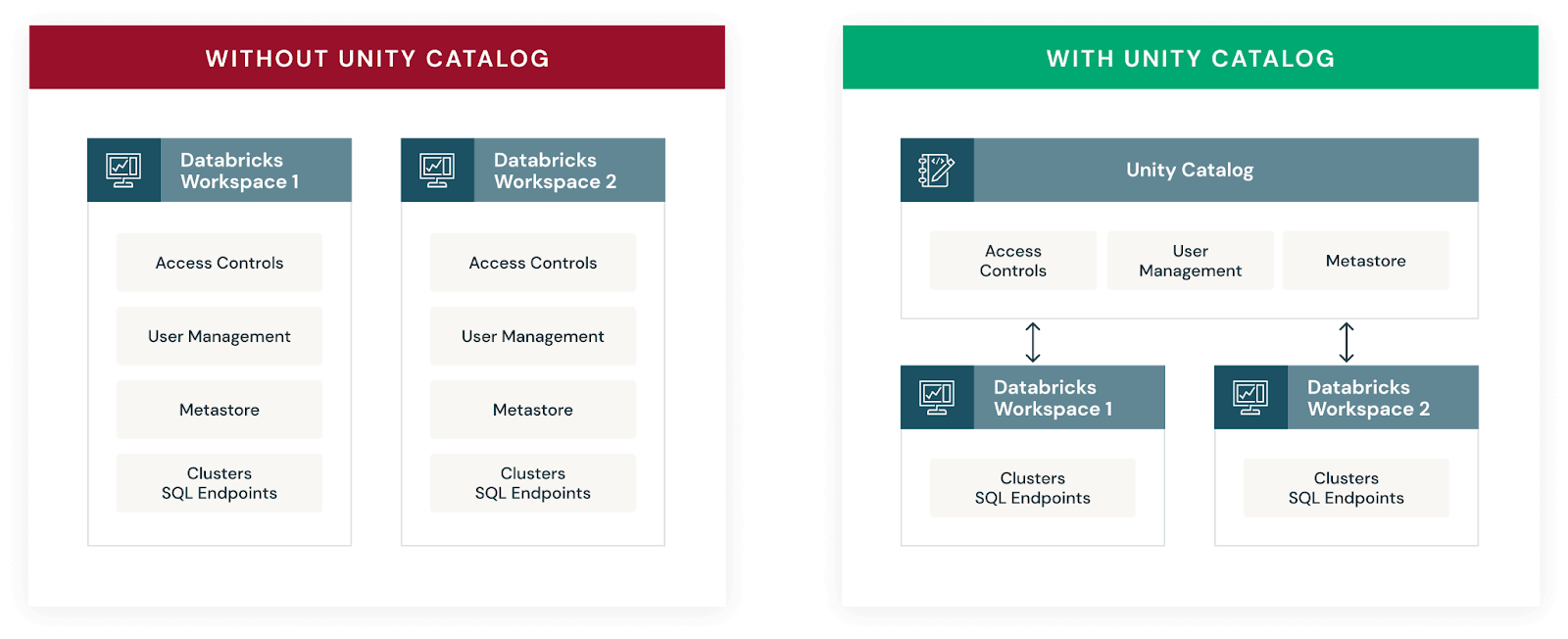
Unity Catalog brings a new era of centralized control in Databricks, streamlining access management, user governance, and data lake authentication across multiple workspaces. Beyond its primary role in data governance, Unity Catalog paves the way to cutting-edge lakehouse features, such as automated data lineage and AI-powered data discovery.
For comprehensive insights into Unity Catalog and its functionalities, I recommend these resources:
- Databricks Documentation: What is Unity Catalog.
- Databricks Blog: Unity Catalog Updates at Data and AI Summit 2023
One of the key aspects of Unity Catalog is its federated authentication model. In this setup, a single service principal or managed identity gains access to data though the Databricks Access Connector resource. Unity Catalog then enables defining granular access controls to this data. Consequently, users interact with data in ADLS or external sources though Unity Catalog, ensuring a secure and controlled data environment.
⚠️ Important Note: With Unity Catalog’s federated access model, non-admin users should not have direct RBAC or ACL access to the data. Such direct access would bypass Unity Catalog’s permissions, leading to potential security gaps.
Enhancing the Lakehouse with Unity Catalog
Simplifying Data Lake Authentication
The Traditional Challenge: Traditionally, authenticating to your Azure Data Lake Store (ADLS) involved one of several methods, each with its drawbacks - manual mount point creation, setting spark.config context in every notebook, or limited support for credential pass-through. Each of these options can result in in security risks and operational inefficiencies.
The Unity Catalog Solution: Unity Catalog eliminates these complexities. By employing a Unity Catalog-compatible cluster, identity authentication to ADLS is seamlessly handled through Unity Catalog’s permission model. This eliminates the need for additional authentication code, mount points, and streamlines your data engineering process.
Unity Catalog greatly simplifies data engineering workflows since you don’t have to think about how you will access the data lake or adding code to each notebook to make that happen.
Refined Access Control
Traditional Constraints: Without Unity Catalog, enforcing object, column, and row-level security is a challenging task. Options either limit functionality or require cumbersome management of Access Control Lists (ACLs), which are not only tricky to administer but also inflexible and potentially limiting in scope of what access can be controlled.
The Unity Catalog Approach: Unity Catalog simplifies this with straightforward ownership and permission settings. Inheritance of access rights is a built-in feature, making it easier to manage permissions across schemas and their associated tables, views, or other objects.
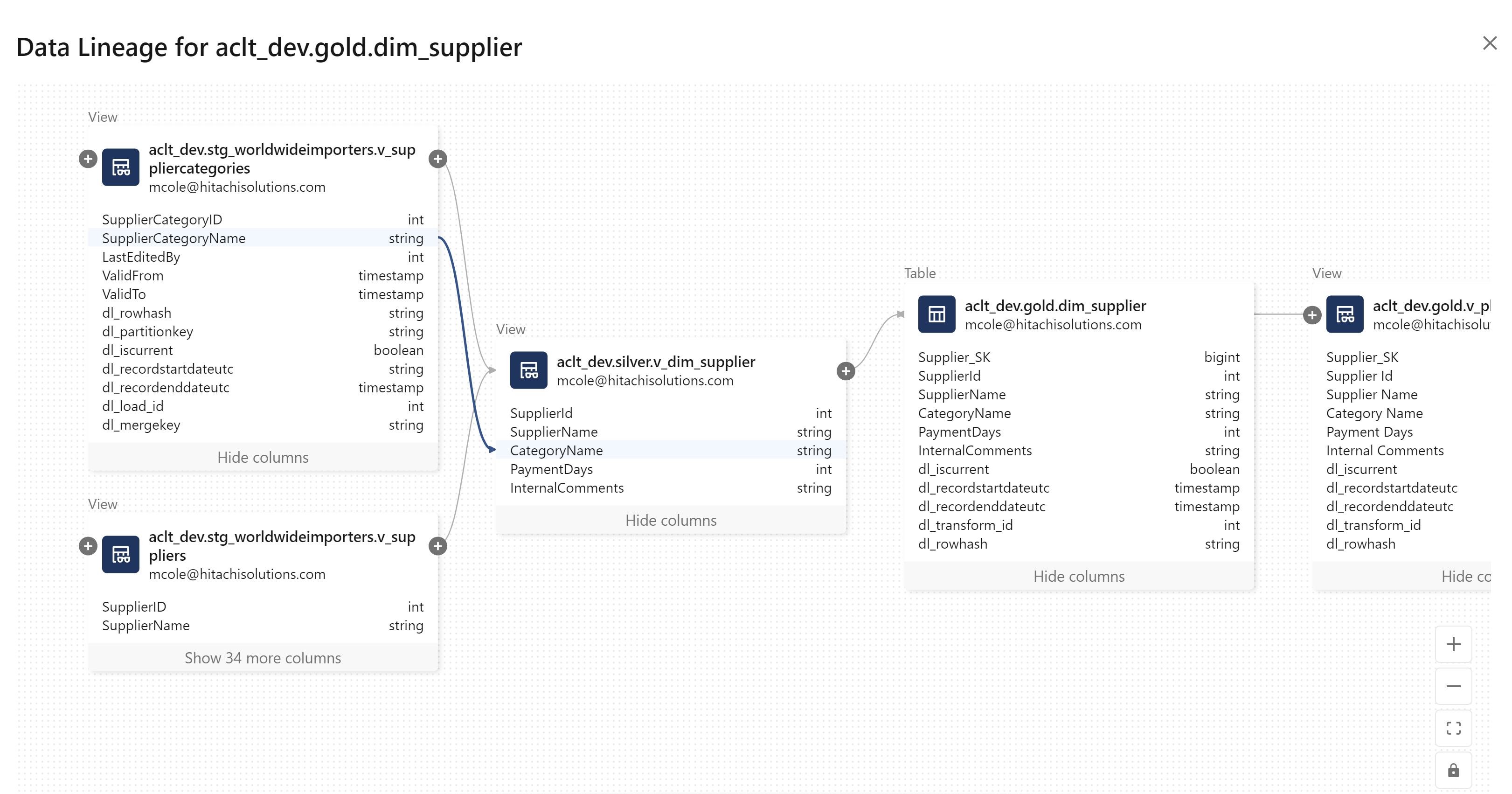
Automating Lineage and Data Dictionary Maintenance
Without Unity Catalog, tracking data lineage and maintaining data dictionaries is often manual, error-prone, time-consuming, and becomes out-of-date nearly as soon as it’s initially created.
With Unity Catalog, these processes are automated:
-
Lineage: Unity Catalog captures and retains data flow lineage automatically for 90 days, irrespective of the programming language used.
-
Data Dictionary: Unity Catalog leverages generative AI to provide initial descriptions for data objects and fields, simplifying data documentation.

You must enable Generative AI features at the Databricks Account level for this to show up.

Quick Takeaway
Unity Catalog is not just an option but a necessity for modern lakehouse architecture in Databricks. By enabling Unity Catalog, you streamline your data workflows, enhance security, and unlock advanced features for your data lake.
To get the most out of your Databricks environment, consider adopting Unity Catalog as a key component of your data strategy.
Migrating to Unity Catalog: A Step-by-Step Guide
Migrating to Unity Catalog in an existing Databricks Workspace requires careful planning. While enabling Unity Catalog in your workspace is straightforward once a metastore is created, the migration of objects from the hive_metastore to a Catalog is a crucial step.
1 - Setup Unity Catalog
There are plenty of good blogs and videos on how to do the initial set up to enable Unity Catalog in your Workspace. I recommend following one of the below:
2 - Create External Locations, Catalogs, and Databases
You will need to create an External Location for each distinct container that you want to manage via Unity Catalog. After creating External Locations, create a Catalog and Databases (aka Schemas) for each Database you want to migrate from the hive_metastore
3 - Assign Permissions to External Locations, Catalogs, and Databases
After creating External Locations, Catalogs, and Databases, assign permissions and ownership to each object.
As an example, for a user to read data from a table within a given schema, the user must have the following permissions:
- USE CATALOG on the parent catalog
- SELECT on either Catalog, Schema, or Table
- READ FILES on the External Location the data exists in
Tip: Assign permissions to Databricks Account groups rather than individual users. I.e. you could have data_admin, data_contributor, and data_reader groups and then assign permissions to those groups instead of named users.
(Recommended) Sync Entra ID Users and Groups to Databricks
To avoid the need to potentially manage group membership multiple places, it is recommended to use the Azure Databricks SCIM Connector so that the membership of groups is managed from Entra ID.
See the following for implementing the SCIM connector: Provision identities to your Azure Databricks account using Microsoft Entra ID
4 - Migrate Delta Tables
When you have tables stored as EXTERNAL TABLES rather than MANAGED TABLES, your migration journey is smoother. For EXTERNAL TABLES, migrating into the Unity Catalog (UC) is primarily a metadata operation, with no physical data movement required. This process retains all transaction logs, table properties, and other metadata. In contrast, migrating MANAGED TABLES involves copying the physical data to create a new table (transaction log is not maintained).
Tip: Opt for EXTERNAL TABLES over MANAGED TABLES. This can save significant time and effort during migrations to new Spark platforms or when adapting to major architectural changes, like the shift to Unity Catalog.
To migrate Delta tables into your new catalog, you can use the following Python script:
# Define the new catalog and default owner
catalog = 'new_catalog'
default_owner_email = 'owner@domain.com'
# Switch to the hive_metastore
spark.catalog.setCurrentCatalog('hive_metastore')
database_list = spark.catalog.listDatabases()
for database in database_list:
print(f"Migrating tables from schema: {database}")
# List all tables in the database
all_tables = spark.catalog.listTables(database.name)
# Separate the table types
external_tables = [table.name for table in all_tables if table.tableType == "EXTERNAL"]
managed_tables = [table.name for table in all_tables if table.tableType == "MANAGED"]
for table in external_tables:
# Set new and old table locations
new_table_location = f"{catalog}.{database.name}.{table}"
old_table_location = f"hive_metastore.{database.name}.{table}"
# Migrate External Tables
try:
spark.sql(f"""
CREATE TABLE IF NOT EXISTS {new_table_location} LIKE {old_table_location}
COPY LOCATION
COPY TBLPROPERTIES
""")
spark.sql(f"ALTER TABLE {new_table_location} OWNER TO `{default_owner_email}`")
except Exception as e:
print(f"Error migrating {table}: {str(e)}")
for table in managed_tables:
# Set new and old table locations
new_table_location = f"{catalog}.{database.name}.{table}"
old_table_location = f"hive_metastore.{database.name}.{table}"
# Migrate Managed Tables
try:
spark.sql(f"""
CREATE TABLE IF NOT EXISTS {new_table_location}
AS SELECT * FROM {old_table_location}
""")
spark.sql(f"ALTER TABLE {new_table_location} OWNER TO `{default_owner_email}`")
except Exception as e:
print(f"Error migrating {table}: {str(e)}")
5 - Remove hive_metastore objects
Once you’ve verified the successful migration of all tables, and notified users to use the new catalog, you should remove tables and views from the hive_metastore. This step ensures that users can no longer see or access Delta tables outside of Unity Catalog. Similar scripting techniques can be used for migrating other objects like views.