So you’ve figured out how to write data into Delta format, congratulations! You’ve joined the Delta Lake club and are enabled for all the goodness that comes with Detla, such as ACID transactions, time travel, etc. Now, how do you ensure that the underlying storage of your Delta Tables is maintained so that as you have inserts, updates, and deletes taking place over time, your data is still stored in the most optimal manner.
Vacuum
No, this isn’t a blog post about the best vacuum brands, however I do want to share how you can keep your Delta Table clean and tidy via performing the vacuum operation.
Delta Tables are just like your house, and even more so if you have young children like myself, things tend to get pretty messy and dirty in short order. As DML transactions (think insert/update/delete) take place on your Delta Table, the prior state of the table will still exist as Delta automatically retains transactional history for your table. This means that as DML operations take place over time, the table folder directory in the data lake will contain an increasing amount of data even if the number of total rows is unchanged.
Time Travel
Since the Delta table transaction log maintains the link to the scope of parquet data that represents the data as of that moment in time, you can use the AS OF syntax to query a Delta table as of a given time period.
SELECT * from gold.dim_customer AS OF '2023-01-01 00:00:00'
While time travel is fantastic, it does increase your storage footprint, therefore it is best practice to consider the amount of time that you want to store transactional history for a Delta table. While data lake storage tends to be quite cheap in comparison to services that do not separate compute from storage, if you do not have a process to periodically vacuum your tables, the continual retention of all historic data can really add up.
In a Lakehouse with 120 GB of daily data growth your storage account bill would be ~ 4x higher after 1 year if you aren’t Vacuuming tables and have a 30 day archival policy on files in raw.
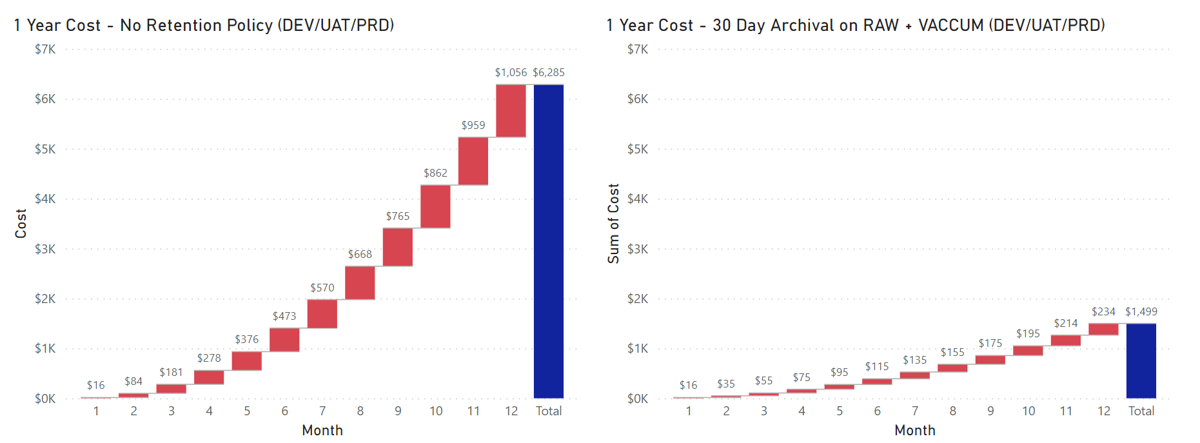 Azure Storage Cost Comparison
Azure Storage Cost Comparison
How to VACUUM a table?
Vacuuming a table is simple, doing it in a cost optimized manner requires additional considerations.
To vacuum a table you can use the simple SparkSql syntax below:
VACUUM gold.dim_customer
Optionally you can specify the number of hours of history to be retained and/or do a dry run to retrun the top 1000 files that would be deleted if the vacuum operation were run. The default retention is 7 days or 168 hours.
VACUUM gold.dim_customer 720 True
Just like your own home, is it efficient to vacuum your floors every day? No. The same principal applies for Delta tables, as transactions take place you have an increasing number of files that are not part of the transaction log, thus adding to the cleanliness of your table, however given that the vacuum operation requires scanning all files in the Delta table directory (that do not start w/ ‘_’), in most cases it will be a waste of compute to run a vacuum operation daily or every time your Delta table gets refreshed.
Typically, engineers will run a weekly or monthly operation to vacuum all tables based on a defined retention period.
My recommendation is to apply a vacuum policy as part of your delta table refresh operation, therefore you don’t need any additional or unique job to run just to clean up your Delta tables.
While there isn’t out-of-the-box functionality to apply a Vacuum policy, it is quite doable to write a function or method to do just that. The below is an example of how you could extract the last vacuum run date to use as part of a function to conditionally Vacuum the table.
# Get the table history
schema_name = 'gold'
table_name = 'dim_customer'
history = spark.sql(f"DESCRIBE HISTORY {schema_name}.{table_name}")
# Find the timestamp of the latest VACUUM operation
latest_vacuum_timestamp = history.filter(history.operation == "VACUUM END").select("timestamp").orderBy(desc("timestamp")).limit(1).collect()
# Set it to a very old date if no VACUUM operation has been run
if latest_vacuum_timestamp:
latest_vacuum_timestamp = latest_vacuum_timestamp[0]["timestamp"]
else:
latest_vacuum_timestamp = datetime.strptime('1900-01-01', '%Y-%m-%d')
The idea is that following any Delta table refresh operation, you’d call a vacuum function or method which would check when the last time a vacuum operation was run, and if it is greater than your vacuum every N days policy parameter, it will trigger a vacuum, otherwise nothing will happen. This is a quick and easy way to integrate vacuum into your existing processes without having to run separate jobs to perform the same operation.
Optimize
Now that we’ve covered keeping the directory of a Delta lake table clean and tidy, how do you ensure that the data is kept in an ideal order and number of files to optimize queries against it.
The optimize command functionally does two things depending on the Delta table configuration and how the OPTIMIZE command is run:
- Compaction of small parquet files
- Reorganization of data within parquet files to co-locate or cluster similar values in the same file
Here’s the basic syntax:
OPTIMIZE table_name [WHERE predicate]
[ZORDER BY (col_name1 [, ...] ) ]
Why is data clustering important?
Functionally this is the same concept as an RDBMS clustered index, Delta Lake table data can be logically ordered based on a set of column values, thus greatly improving the performance of querying a Delta table where one of those columns is used in a where clause or join condition. For those that are new to this concept, think of a dictionary, it is ordered with entries, A to Z. You know that if you are looking for the word yak you would find it the fastest if you immediately opened a page near the end of the book. The same concept applies for Delta tables, statistics on column values are capture so that the query optimizer knows the potential min, max, and distribution of a sampling of values so that when a query is run it knows approximately which parquet file contains the record that meets the WHERE or JOIN condition.
How can I cluster a Delta Table?
Liquid Clustering
If you are using Spark w/ Delta Lake 3.x (Databricks Runtime 13.3 LTS and above), Databricks has introduced a new feature called Liquid Clustering. Liquid Clustering is designed to completely replace hive-sytle partitioning and Z-ordered clustering. Simply put, it is akin to a lazily maintained clustered index. This means that the columns of an optimized table are guaranteed to be physically close to each other, however it is unlike a RDBMS clustered index in that an absolute order of records following the clustering keys is not strictly enforced or even an objective.
Liquid Clustering has many advantages over Z-order (explained later):
- The clustering keys of the Delta table can be changed without needing to rewrite the entire table.
- The data layout can evolve overtime without drastic rewrite operations.
- It is possible to cluster on write. See the Azure Databricks documentation for the specific conditions that must be met.
- Optimize operations to cluster the data are incremental and idempotent.
⚠️ Because not all operations will apply liquid clustering on write, Databricks recommends to frequently run
OPTIMIZEto make sure that all data gets clustered.
The below SparkSql would create liquid clustered table:
CREATE TABLE gold.fact_sales CLUSTER BY (SalesOrderId, SalesOrderDate)
To incrementally rebuild the cluster of a liquid clustered table, simply run the following:
OPTIMIZE table_name
The first run will be longer as it reorganizes the data layout, however you’ll notice that when you run it a second time or even after data is updated, it will run much faster. While it is recommended to only periodical run a Vacuum operation, because Optimize with Liquid Clustering is incremental, I recommend running it following any DML operation.
Limitations of Liquid Clustering
- Only columns with statistics collected can be clustered, by default this is the first 32 columns.
- Only 4 columns can be selected as clustering keys
- Boolean data types cannot be clustering keys
Z-Order Clustering
If you are using Spark w/ Delta Lake 2.x or lower (Databricks Runtime 12.x, Synapse Spark, Fabric Spark Runtime 1.1), liquid clustering is not yet available and therefore Z-Order clustering is the closest thing you can do to logically order your data to improve query performance.
Z-order is conceptually very similar to liquid clustering however has the below shortcomings which make it inferior to liquid clustering if you do have the option to use Delta Lake 3.x.
- The clustering keys can be changed however will require rewriting all data
- The clustering keys cannot be defined on creation of the delta table and instead are only defined when OPTIMIZE is called
- There aren’t any write operations that will cluster the data on write, it is always a post write operation and is not fast to run.
- Optimize with ZORDER is not idempotent and tends to take the same amount of time even if the underlying data is unchanged.
To Z-order your data, run the following:
OPTIMIZE gold.fact_sales ZORDER BY (SalesOrderId, SalesOrderDate)
Whether you are using liquid clustering, Z-Order, or are storing your data uncluster: Consider DML (i.e. INSERT/UPDATE/DELETE) and DQL (SELECT) query patterns on top of your Delta tables before blindly applying a data storage strategy.