So, pretty much everyone seems to be on board with Lakehouse architecture these days, and for good reason. Decoupled compute and storage with all of the best data warehousing type features and more via Delta Lake is a pretty easy sell. It’s a complete no-brainer for greenfield development, but the conversation gets quite a bit more nuanced as you start talking about migrating, or more accurately, replatforming from a traditional data warehousing platform (coupled compute and storage) to Lakehouse.
Most data warehouses that are not in their infancy will have hundreds of code files, possibly thousands, that make up the business logic of the warehouse. They might be views, stored procedures, tables, functions, random scripts, etc. This can become a major road block to replatforming unless you have an army of data engineers… most companies are not so privileged.
In this post I’ll share details on one of the most important Python libraries you need to get familiar with if you are considering a replatform, have one planned, or are not yet on a lakehouse architecture in Fabric or Databricks.
Introducing SQLGlot
SQL what? SQLGlot. Think polyglot, someone who is blessed with linguistic prowess and can speak four or more languages, but for SQL. SQLGlot is an open-source Python project that aims to support transpiling between SQL dialects and also supports dynamically building and parsing SQL statements, in your dialect of choice, in a very Pythonic way.
SQLGlot supported dialects: Athena, BigQuery, ClickHouse, Databricks, Doris, Drill, DuckDb, Hive, MySql, Oracle, Postgres, Presto, PRQL, Redshift, Snowflake, Spark, SqLite, StarRocks, Tableau, Teradata, Trino, and T-SQL (Synapse Dedicated, MSSQL, etc.)
When we look at replatforming a traditional data warehouse to lakehouse architecture there are three primary challenges to deal with on the code side of things:
- Volume of code to refactor: In my career I can think of a few environments I’ve worked on where there were hundreds of thousands of lines of code that made up the platform. In a smaller environment, you might have closer to 10,000 lines of code, regardless, that is a whole lot of code to refactor or rewrite to support a different SQL dialect.
- Variety of code to refactor: Companies migrating to lakehouse architectures are coming from all sorts of data warehousing technologies, and a lot of businesses are unlucky enough to be on the hook for modernizing multiple legacy systems. This means we could be talking about a plethora of SQL dialects that we need to consider.
- Giving up dated coding patterns: Are you a fan of writing dynamic SQL? Guess what? You’ll love PySpark. Sure, you can do some pretty cool stuff with dynamic SQL, but Python + SparkSQL will change your life. This is the way.
The good news is that SQLGlot can do wonders to help with #1 and #2. #3 is more challenging but I’ll cover how you can use generative AI to help automate pattern changes in a future blog post.
The Basics
In this post, I’ll only be focusing on transpiling use cases. The syntax is almost too straightfoward. You simply pass in the SQL to convert, the dialect that is being read, and the dialect you want to write out. Easy.
import sqlglot as sg
sg.transpile("SELECT CONVERT(BIT, 1) AS C1", read="tsql", write="spark")[0]
The above returns SELECT CAST(1 AS BOOLEAN) AS C1.
How about a more complex example? The below T-SQL contains a number of different syntax constructs that exist in SparkSQL, although with completely different syntax.
CONVERT: I prefer CONVERT over CAST but guess what? Every other SQL dialect I’m aware of uses CAST.[Brackets for column name aliasing]: easily one of my least favorite things to refactor across dialects since every dialect does it slightly differently and it takes forever.OUTER APPLY: SparkSQL supports a different syntax,LEFT JOIN LATERAL.LEFT: SparkSQL usesSUBSTRINGinstead.
SELECT
CONVERT(VARCHAR, GETDATE(), 101) AS [CurrentDateFormatted],
LEFT(ProductName, 10) AS [Short Product Name],
YEAR(OrderDate) AS OrderYear,
PIVOTData.*
FROM
Sales.Orders o
INNER JOIN
Sales.OrderDetails od ON o.OrderID = od.OrderID
INNER JOIN
Products p ON od.ProductID = p.ProductID
OUTER APPLY
(SELECT
1 AS JanuarySales,
2 AS FebruarySales,
3 AS MarchSales
FROM
(SELECT
MONTH(OrderDate) AS SaleMonth,
SalesAmount
FROM
Sales.Orders
WHERE
YEAR(OrderDate) = YEAR(GETDATE())) AS SourceTable
PIVOT
(SUM(SalesAmount)
FOR SaleMonth IN (1, 2, 3)
) AS PivotTable
) AS PIVOTData
WHERE
o.OrderDate BETWEEN '2023-01-01' AND '2023-12-31'
GROUP BY
ProductName, OrderDate, PIVOTData.JanuarySales, PIVOTData.FebruarySales, PIVOTData.MarchSales
ORDER BY
OrderYear DESC;
Here’s the simple SQLGlot code after I set the above T-SQL as a variable named input_sql:
import sqlglot as sg
sg.transpile(input_sql, read="tsql", write="spark", pretty=True)[0]
And the result of the conversion…
SELECT
CAST(DATE_FORMAT(CURRENT_TIMESTAMP(), 'MM/dd/yyyy') AS VARCHAR(30)) AS `CurrentDateFormatted`,
LEFT(CAST(ProductName AS STRING), 10) AS `Short Product Name`,
YEAR(OrderDate) AS OrderYear,
PIVOTData.*
FROM Sales.Orders AS o
INNER JOIN Sales.OrderDetails AS od
ON o.OrderID = od.OrderID
INNER JOIN Products AS p
ON od.ProductID = p.ProductID LEFT JOIN LATERAL (
SELECT
1 AS JanuarySales,
2 AS FebruarySales,
3 AS MarchSales
FROM (
SELECT
*
FROM (
SELECT
MONTH(OrderDate) AS SaleMonth,
SalesAmount
FROM Sales.Orders
WHERE
YEAR(OrderDate) = YEAR(CURRENT_TIMESTAMP())
) AS SourceTable PIVOT(SUM(SalesAmount) FOR SaleMonth IN (1, 2, 3))
) AS PivotTable
) AS PIVOTData
WHERE
o.OrderDate BETWEEN '2023-01-01' AND '2023-12-31'
GROUP BY
ProductName,
OrderDate,
PIVOTData.JanuarySales,
PIVOTData.FebruarySales,
PIVOTData.MarchSales
ORDER BY
OrderYear DESC
The below diff highlights how truly powerful this library is:
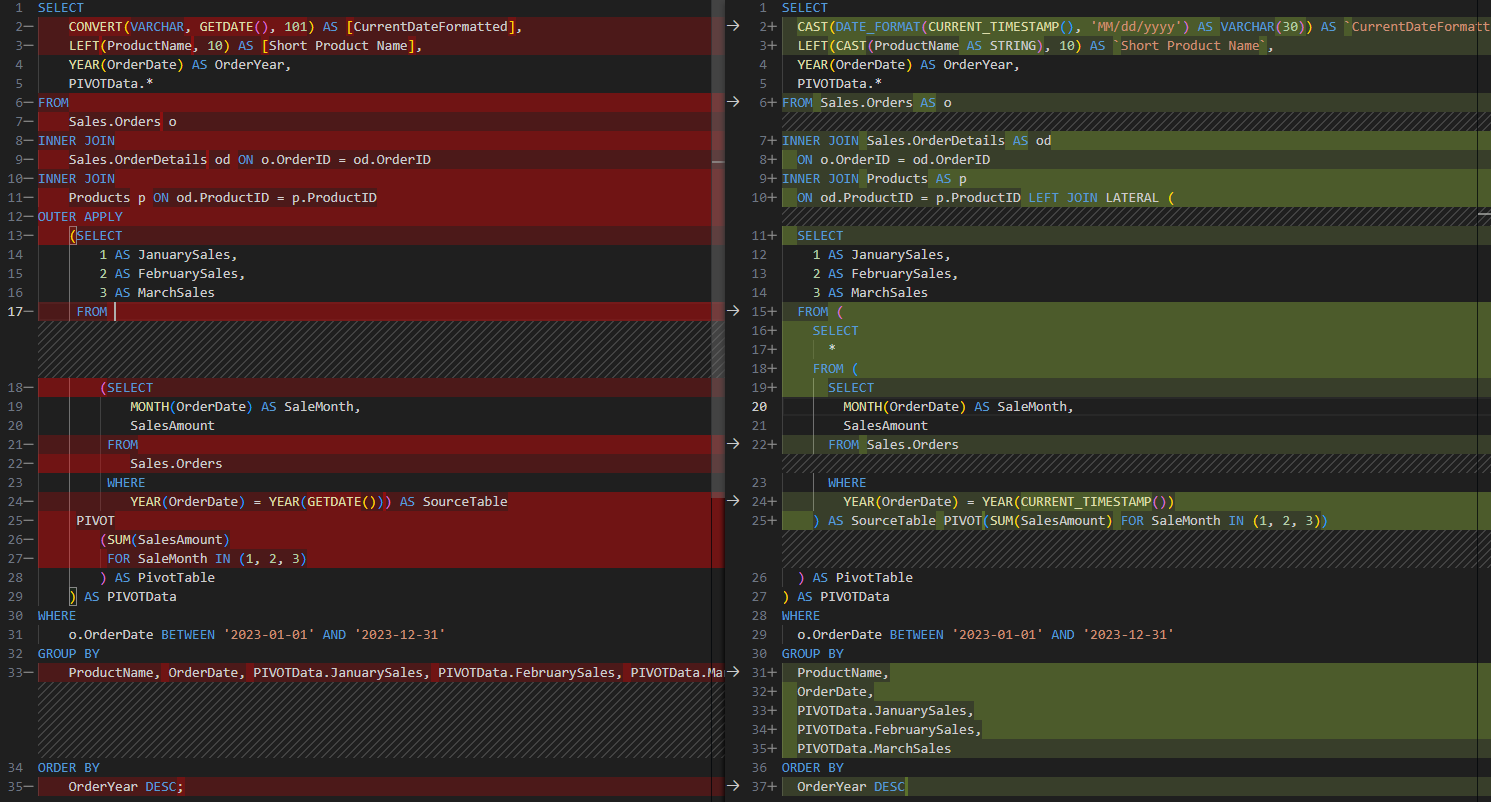
It accurately converted all T-SQL syntax differences to SparkSQL, even the specific style (101 for US datetime) of the CONVERT function. If that’s not enough, if you didn’t notice, in the last command I threw in pretty=True to return formatted SQL.
What about an example of it returning a partially successful conversion? Let’s convert the former simple SQL to Oracle.
import sqlglot as sg
sg.transpile("SELECT CONVERT(BIT, 1) AS C1", read="tsql", write="oracle")[0]
The output returned is SELECT CAST(1 AS BIT) AS C1. Anyone familiar with Oracle knows that this code wouldn’t pass the sniff test, Oracle has this wonderfully inconvenient feature where you have to query FROM DUAL when writing a tableless select statement. The easy solution here is just to not migrate your data warehouse to Oracle. Seriously, problem solved. The lesson here is that SQLGlot isn’t foolproof but it sure can do wonders to accelerate the ability to convert between SQL dialects in bulk.
Using SQLGlot in Replatforming Projects
Now, how can you use SQLGlot as part of a large replatforming project? Here’s one relatively straightforward method:
- Upload all of your SQL script files to your data lake or as Notebook resources in Fabric.
- List the SQL files in your directory
- Loop over the file list and do the following:
- Read the file contents into a variable
- Convert via SQLGlot and output as another variable
- Write converted SQL to a file back to your directory of choice.
Your code would look something like the below:
import sqlglot as sg
input_dir = '<input sql file directory>'
transpiled_dir = '<director to save transpiled files>'
sql_list = mssparkutils.fs.ls(input_dir)
for s in sql_list:
sql = mssparkutils.fs.head(s.path, 1000000)
sql_transpiled = sg.transpile(sql, read="tsql", write="spark", pretty=True)[0]
file_name = f"{transpiled_dir}/{s.name}"
mssparkutils.fs.put(file_name, sql_transpiled, overwrite=True)
So easy… you could iterate over and convert thousands of SQL files to another dialect in minutes. Sure, it may not always be a perfect conversion, however, it will greatly accelerate the process of getting to a Lakehouse architecture.