With Microsoft going all in on Delta Lake, the landscape data architects deeply integrated with the Microsoft stack is undergoing a significant transformation. The introduction of Fabric and OneLake with a Delta Lake driven architecture meanas that the decision on which data platform to use no longer hinges on the time and complexity of moving data into the platform’s data store. Instead, we can now virtualize our data where it sits, enabling various Delta-centric compute workloads, including Power BI.
If there’s anything ChatGPT can’t tell you, until it includes my blog post in its training data, is accurate information about the compatibility of Delta table features across different versions of Delta Lake, and the nuances of Delta Lake compatibility between Databricks vs. Fabric. For those looking to enable hybrid architectures where we might store all or part of our data outside of Fabric (i.e. Azure ADLS, AWS S3, or GCP GCS) and simply virtualize it in OneLake via shortcuts, we need to understand the nuanced compatability between different versions of Delta Lake.
Learning Delta Feature Compatibility
How about good old fashion googling? Nope, information on this topic is sparse, confusing, and sometimes misleading.
How about the delta-io/delta documentation on GitHub? Still no, but getting closer. While there’s tons of helpful information in the Delta Transaction Log Protocol document on GitHub, the information on this topic is so nuanced that I really couldn’t get an accurate understanding of this concept till I started up a cluster and ran test cases.
So please, if anyone has already discovered the decoder ring, please drop me a message :)
Here are the key insights:
-
Databricks Delta Lake vs. Open-Source Delta Lake: The version of Delta Lake that Databricks says is used in its Runtimes is not the same as open-source Delta Lake within the same major and minor version.
⚠️ Databricks, the benevolent creator of Delta Lake, introduces new Delta Lake features in Databricks runtimes before they are publically accessible in the open-sourced Delta Lake project. For example, Liquid Clustering is first available in Databricks Runtime 14.x which runs Delta Lake 3.0.0, however open source Delta Lake doesn’t contain the Liquid Clustering table writer feature till version 3.1.0.
- Documentation Can Be Wrong: If documentation seems to conflict with other sources OR it doesn’t pass the smell test, always test to confirm delta table behavior. At the time of writing this post the delta.io/delta documentation incorrectly stated that enabling Default Columns on a table would prevent it from being read by versions before 3.1.X (I submitted a PR to fix this).
- The Compatibility Specification Has Changed: Compatibility before Delta Lake 2.3.0 was based on protocol versions which added something like
minimumReaderVersion=3, minimumWriterVersion=7to the transaction log of your Delta table, these minimum reader and writer version numbers entirely determined whether you could read from the table. Starting with Delta Lake 2.3.0, the concept of Table Features was introduced to replace the more ridgid protocol version, it allows for specific features to be feature flagged therefore allowing more flexibility and a high level of interoperability between different Delta versions.
That’s my preamble on core concepts I had to learn to generate the following info, now on to the compatibility matrix.
Delta Reader Feature Compatability
The table below contains the three Delta table features (plus one that requires a workaround) which not all Apache Spark Runtimes in Fabric can read when enabled by another Delta Lake based platform, i.e. Databricks.
⚠️ Seeing
Yesin the table does not necessarily mean you can enable that feature via the Fabric Runtime, just that your can read from a table that already has it enabled by another platform using Delta Lake.
| Table Feature | Runtime 1.2 (Delta Lake 2.4.0) | Runtime 1.3 (Delta Lake 3.2) | Runtime 2.0 EPP (Delta Lake 4.0) |
|---|---|---|---|
| Default Columns | Yes† | Yes | Yes |
| V2 Checkpoints | No | Yes | Yes |
| Liquid Clustering†† | Yes if v2Checkpoints are dropped | Yes | Yes |
| Deletion Vectors | Yes | Yes | Yes |
| Column Mapping | Yes | Yes | Yes |
| TimestampNTZ | Yes | Yes | Yes |
| Variant Type | No | No | Yes |
| Type Widening | No | No | Yes |
†† Databricks enables V2 Checkpoints by default when using Liquid Clustering. However, Liquid Clustering by itself is a writer table protocol and not a reader protocol, that means we can drop V2 Checkpoints after enabling Liquid Clustering to allow Fabric Runtimes prior to 1.3 to read from Liquid Clustered tables. This not a straightforward process, see how to drop V2 Checkpoints.
Dropping Table Features to Enable Read OR Write Compatibility
There are currently two Delta table features that can be dropped:
v2Checkpoints(available since Delta Lake 3.0)deletionVectors(available since Delta Lake 2.3)
Given that Delection Vectors are available in Delta Lake 2.3.0, I will only be highlighting dropping V2 Checkpoints, however the process is exactly the same.
How to Drop V2 Checkpoints
Since the transaction log contains transaction history which contains V2 Checkpoints, we must first drop the feature which will stop future transactions from using the feature, and then drop with the feature from historical transactions.
Steps:
- Drop the table feature
ALTER TABLE default.liquid_clustered_table DROP FEATURE v2Checkpoint - 24 hours later, drop the table feature with
TRUNCATE HISTORY.ALTER TABLE default.liquid_clustered_table DROP FEATURE v2Checkpoint TRUNCATE HISTORYOR
- Wait until the Delta log retention duration has passed. This setting is 30 days by default.
At this time it is not possible to disable V2 Checkpoints on creation of a Liquid Clustered table. However, after following these steps we will be able to successfuly shortcut a Liquid Clustered table into Fabric and read it natively.
Delta Writer Feature Compatability
The below table contains the Delta table features which not all Apache Spark Runtimes in Fabric can write to.
| Table Feature | Runtime 1.2 (Delta Lake 2.4) | Runtime 1.3 Preview (Delta Lake 3.2) | Runtime 2.0 EPP (Delta Lake 4.0) |
|---|---|---|---|
| Default Columns | No | Yes | Yes |
| Generated Columns | Yes | Yes | Yes |
| V2 Checkpoints | No | Yes | Yes |
| Liquid Clustering | No | Yes | Yes |
| Identity Columns | No | No | Yes |
| Row Tracking | No | Yes | Yes |
| Domain Metadata | No | Yes | Yes |
| Iceberg Compatibility V2 | No | Yes† | Yes† |
| Deletion Vectors | Yes | Yes | Yes |
| Column Mapping | Yes | Yes | Yes |
| TimestampNTZ | Yes | Yes | Yes |
| Variant Type | No | No | Yes |
| Type Widening | No | No | Yes |
| Collations | No | No | Yes |
† Iceberg Compatibility V2 is enabled via Delta 3.2, however Fabric Runtime 1.3 is doesn’t pre-install the delta-iceberg package to support writing the Iceberg metadata.
Bulk Evaluating Delta Tables for Compatibility
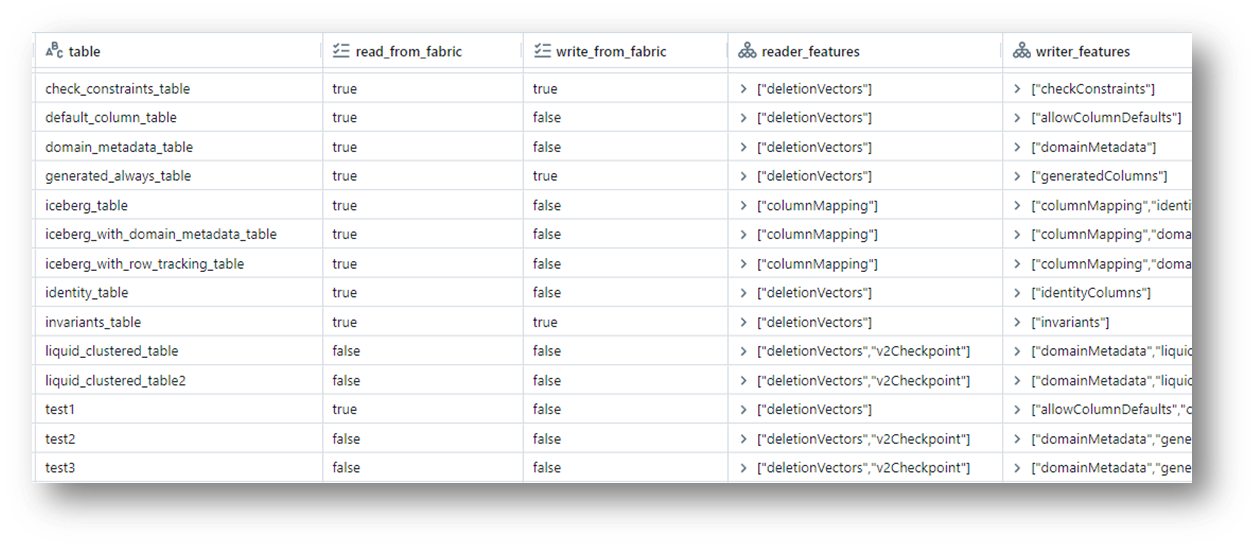
Now we have somewhat of a decoder ring, although still pretty nuanced to understand. Since every business using Power BI and Delta Lake should be evaluating migrating to use Direct Lake over Import/DirectQuery/Dual storage mode, I created a PySpark library that can be used to evaluate your existing Delta Tables in Databricks. It will return a dataframe report with information highlighting your Delta Tables with boolean indicators showing whether or not they can be read or written to from the different Fabric runtimes.
Simply install the library on your cluster from PyPi via the %pip magic command:
%pip install onelake_shortcut_tools
from onelake_shortcut_tools.compatibility_checker import CompatibilityChecker
df = CompatibilityChecker(
catalog_names=['catalog1', 'catalog2'],
schema_names=[],
fabric_runtime='1.3'
).evaluate()
display(df)