Photon is a native vectorized execution engine within Databricks, entirely written in C++, designed to massively boost performance on top of Spark by circumventing some of the JVM inefficiencies and better leveraging modern hardware.
Sounds like a no-brainer, right? However, unless your CIO doesn’t care about reducing cloud costs, it’s advisable to consider the TCO (Total Cost of Ownership) of Photon when executing your Lakehouse strategy in Databricks. Databricks applies a 2x DBU multiplier when Photon is enabled, meaning you will pay twice as much per second in licensing costs. Ideally, this cost should be offset by at least a 2x performance improvement to make it cost effective.
In this post, I’ll detail benchmarks that illuminate the TCO implications of enabling Photon in Databricks and scenarios where you may not want to enable it.
How Does Photon Work?
For those interested in the technical details, Databricks has published a comprehensive whitepaper on the Photon engine.
A key takeaway from the whitepaper is that the Photon engine uses a columnar representation of data in memory, similar to Apache Arrow, whereas Spark SQL uses a row-oriented repesentation of data. As hybrid Photon and SparkSQL query plans are generated, data must be transfered between columnar and row-oriented memory formats, while the memory transformation takes place, the performance gains on the columnar format still typically produce performance gains in the net. To prevent too much back and forth transfer between columnar and row-oriented memory, Databricks elected to make Photon be on the conservative side of generating hybrid query plans.
What Queries will Photon Benefit?
As the whitepaper notes:
Photon primarily improves the performance of queries that spend a bulk of their time on CPU-heavy operations such as joins, aggregations, and SQL expression evaluation.
Photon can also provide speedups on other operators such as data exchanges and writes by either speeding up the in-memory execution of these operators or by using a better encoding format when transferring data over the network. We do not expect Photon to significantly improve the performance of queries that are IO or network bound.
The Benchmark
Configuration
To assess the performance enhancements provided by Photon, I had ChatGPT whip me up six OLAP queries using varying SparkSQL transformations. These queries were run on a synthetic database that reflects data volumes typical of small to medium-sized enterprises (approximately 100M rows in transaction tables). Delta Tables with Liquid Clustering enabled showed greater performance improvements with Photon compared to unclustered tables. I will discuss this further and compare Liquid Clustering with Hive-style partitioning in a future post.
I conducted all tests on a single-user cluster with two worker nodes, each an E8ds_v5 VM (64 GB Memory, 8 Cores), comparing results with Photon enabled and disabled. I repeated the tests after restarting the cluster to clear any caches and averaged the results.
Results
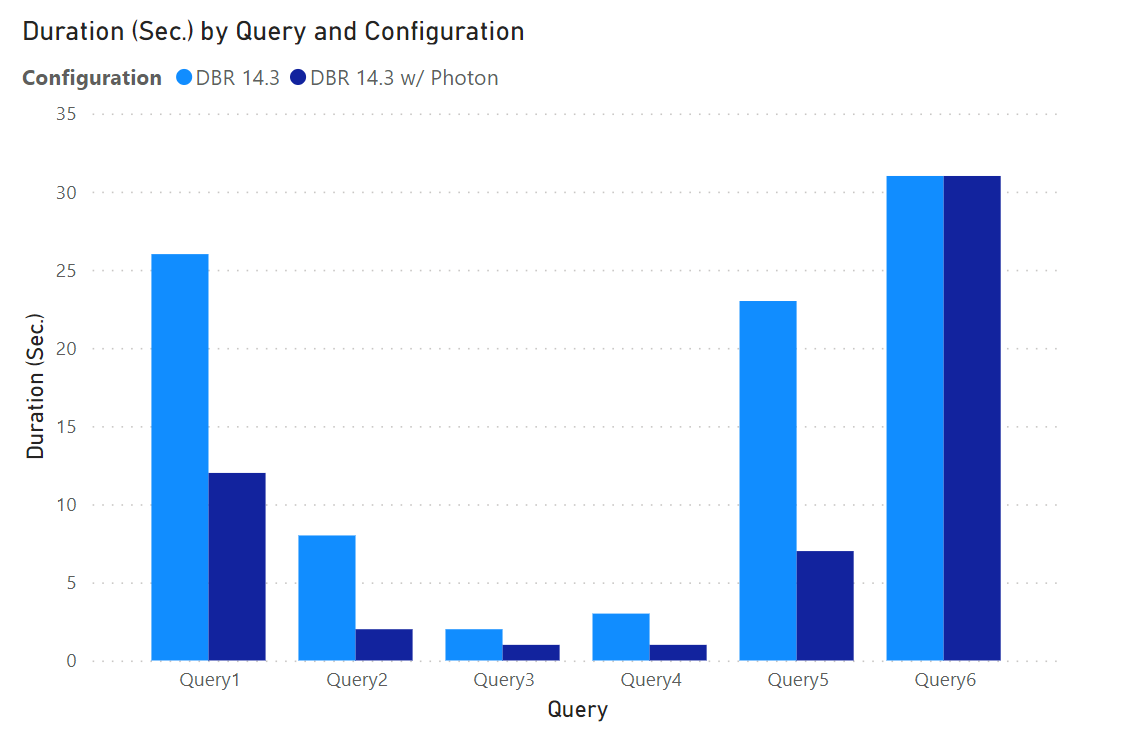
| Query | DBR 14.3 Duration (Sec.) | DBR 14.3 w/ Photon Duration (Sec.) | Percentage Improvement | Times Faster |
|---|---|---|---|---|
| Query1 | 26 | 12 | 54% | 2.17x |
| Query2 | 8 | 2 | 75% | 4x |
| Query3 | 2 | 1 | 50% | 2x |
| Query4 | 3 | 1 | 67% | 3x |
| Query5 | 23 | 7 | 70% | 3.3x |
| Query6 | 31 | 31 | 0% | 1x |
Excluding Query6, which showed no performance improvement with Photon due to its simplicity (a single table insert), Photon, on average, was 63% faster. Said differently, excluding Query6, Photon was 2.7x faster on average than DBR 14.3 without Photon.
TCO
For TCO calculations, I used an All-Purpose Compute with the previously mentioned cluster configuration. The approximate cost per hour in West US, including VM cost, is:
- Without Photon: $6.27/hour
- With Photon: $10.80/hour
Based on the query runtimes, the cost analysis for each query is as follows:
| Query | DBR 14.3 Cost | DBR 14.3 w/ Photon Cost |
|---|---|---|
| Query1 | $0.045 | $0.036 |
| Query2 | $0.014 | $0.006 |
| Query3 | $0.003 | $0.003 |
| Query4 | $0.005 | $0.003 |
| Query5 | $0.040 | $0.021 |
| Query6 | $0.054 | $0.093 |
All queries that could be improved by Photon, except Query3, were less costly to run with Photon enabled. Query6 was almost twice as expensive since Photon does not optimize simple queries without joins. With this specific cluster configuration, a query needs to run approximately twice as fast to offset the higher licensing costs.
When Should I Avoid Photon?
Photon does not enhance performance for certain Lakehouse operations:
- Append mode queries where the source data does not involve CPU-heavy operations (e.g., appending data from Parquet files to a Delta table, structured streaming in append mode).
- Maintenance operations (e.g., VACUUM and OPTIMIZE).
- Extraction jobs (e.g., extracting data via API, JDBC, etc., and writing to Parquet or appending to Delta).
- Non-Spark (single-machine) tasks (e.g., Polars, regular Pandas, web scraping via BeautifulSoup).
- Development clusters: consider that during development, you rarely run a notebook from start to finish and then shut it down. Every second spent coding, thinking, being distracted, or after finishing your work as your cluster nears the auto-pause threshold, you are paying twice as much for DBU licensing, which can be as costly as the underlying machine.
⚠️ Enabling Photon for any of the above tasks will likely result in double the licensing costs without any performance benefit.
Should You Always Enable Photon?
I advise against enabling Photon for all jobs across all user clusters in Databricks. Photon generally does not improve performance for simple DML operations that only involve a single table. Thus, it may be wise to strategically organize and execute jobs based on whether Photon provides a significant performance improvement and/or results in net lower job cost.
Ultimately, understanding your workload and recognizing when to use Photon can lead to more efficiently configured development, UAT, and production clusters, as well as grouped jobs based on workload type.
Is this ideal? No. Does this encourage a natural development pattern? Not really. Are we doing this because Databricks’ pricing model necessitates it? Absolutely. I believe Databricks may have missed an opportunity by designing their pricing model this way, which complicates development processes to optimize TCO on their platform. As a user, I would prefer if Databricks included the costs of maintaining and developing Photon within the overall DBU costs, thus differentiating itself from competitors without making Photon a separate profit center that customers need to cautiously enable. Unlike the cloud VMs that Databricks Runtime (DBR) operates on, Photon usage is not a constrained resource; it’s simply an optimized part of the DBR software. Therefore, its cost shouldn’t scale linearly with the number of cluster cores, especially given that many Databricks customers likely don’t fully understand the cost implications and scenarios where it offers no benefit.
Today, I’m not aware of any competitors that offer anything similar to Photon, once there are, I have to assume that Databricks’ hand will be forced to drop the Photon DBU multiplier, as afterall, when Photon is no longer a unicorn feature that no other service offers, why would you pay such a significant premium for it?
In conclusion, Photon can provide a massive performance improvement, however enabling it blindly is a costly decision.