With Microsoft Build 2024 underway, the wave of announcements are hot off the press! This is a recap of some of the data engineering specific updates that I’m particularly excited about.
Fabric Native Execution Engine for Spark
Via Photon, Databricks has been the only PaaS/SaaS Spark platform to offer a native execution engine, until today. Fabric’s Native Execution Engine (referred to as NEE from here on… I expect Microsoft to formally brand this for the GA announcement), while composed of different OSS technologies, offers the same value proposition as Photon: it is a pluggable execution engine written entirely in C++ that provides significant acceleration on top of vanilla Apache Spark.
To learn more, check out Sandeep Pawar’s blog on the NEE.
Fabric NEE vs. Photon
The biggest difference between Fabric’s NEE and Photon is that the NEE is composed of two OSS technologies, Gluten and Velox, whereas Photon is entirely written and maintained by Databricks.
A bit of background on both technologies:
- Velox: Velox is a pluggable or standalone accelerator engine written in C++ that aims to accelerate workloads via not having JVM overhead and performing transformations on columnar data rather than row data. Velox was created by Meta and is currently being developed in partnership with a few other companies including Intel.
- Apache Gluten (Incubating): Gluten is effectively the glue (that’s why it’s named gluten) that binds JVM-based SQL engines (i.e. Apache Spark) with native execution engines. Gluten is effectively the integration between Spark and Velox since Velox. Gluten was developed by Intel and has since been donated to the Apache software foundation.
For background on Photon, I wrote a blog on Photon and important cost considerations.
I will write a blog comparing the performance of Photon vs. NEE later, for now, I’ll highlight that enabling the Fabric NEE provided an average of ~30% improvement in query execution times for a sampling of queries that contained a few 100M row tables. Higher volumes of data should result in more improvement since the NEE uses columnar storage for data transformations. I would expect that the improvement will get faster and closer to Photon by GA.
Fabric Runtime 1.3 (Preview)
This preview runtime gives us access to Spark 3.5 and Delta 3.1 whereas Runtime 1.2 has Spark 3.4 and Delta 2.4.
Spark 3.5
Spark 3.5 introduces a lot of important features, I’ll highlight a couple:
- Arrow-optimized Python UDFs: Arrow? Arrow is a columnar in-memory storage format. DuckDB, Polars, etc. are all super fast and efficient at processing largish data on single machines because they leverage Arrow columnar memory format. While it must be manually enabled for your Python UDFs, it’s worth it as they can perform up to 2 times faster than standard Python UDFs.
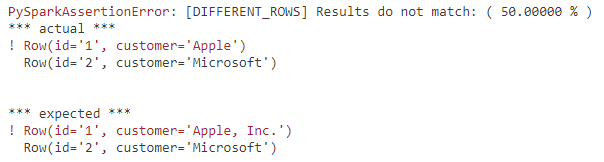
- Testing APIs: While libraries like chispa have been around to help with DataFrame comparison and equality tests, now we get out-of-the-box capabilities via Spark (
assertDataFrameEqual,assertPandasOnSparkEqual,assertSchemaEqual). Here’s a quick example:1 2 3 4 5 6
from pyspark.testing import assertDataFrameEqual df1 = spark.createDataFrame(data=[("1", "Apple"), ("2", "Microsoft")], schema= ["id", "customer"]) df2 = spark.createDataFrame(data=[("1", "Apple, Inc."), ("2", "Microsoft")], schema=["id", "customer"]) assertDataFrameEqual(df1, df2)
Running the above will throw an error:
Delta Lake 3.1
Fabric Runtime 1.3 (Experimental) was previously using Delta Lake 3.0 but now the preview version of Runtime 1.3 includes Delta Lake 3.1. This is extremely exciting as per the roadmap shared at the Fabric conference, we should be seeing this runtime as GA in the next month or two which will unlock a number of critical features for production workloads not available in Fabric Runtime 1.2 (Delta 2.4):
- Liquid Clustering: this completely replaces Hive-style partitioning and Z-ORDER optimization. Hive-style partitioning is inflexible and often misused which results in performance degredation via having too many small files. Z-ORDER optimisation, while offering performance benefits, is not an incremental operation and doesn’t take place on write into a table which makes it extremely expensive to run (all data has to be rewritten… every.. single.. time). See Denny Lee’s blog on Liquid Clustering for details on how it works and this blog for some benchmarks showing the performance impact.
1
spark.conf.set("spark.databricks.delta.clusteredTable. enableClusteringTablePreview", "true")
 Source: https://www.databricks.com/blog/announcing-delta-lake-30-new-universal-format-and-liquid-clustering
Source: https://www.databricks.com/blog/announcing-delta-lake-30-new-universal-format-and-liquid-clustering - MERGE and UPDATE Performance Improvements: better support for data skipping, improved execution, and faster merges (Delta 3.1) and updates (Delta 3.0) that can now leverage Deletion Vectors.
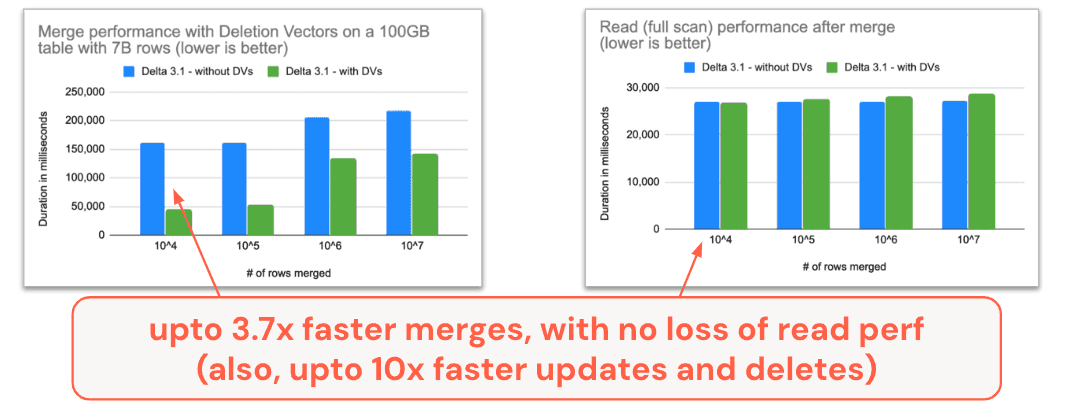 Source: https://delta.io/blog/state-of-the-project-pt2/
Source: https://delta.io/blog/state-of-the-project-pt2/ - Delta Uniform: supports enabling Iceberg and Hudi metadata logs to be created with the Delta Lake metadata log to enable interoperability between different data readers.
- V2 Checkpoints: enables Delta tables to scale to a whole new level and makes reading the transaction log much more efficient via checkpoints every 10 transactions. Every 10 transactions, all prior commits are unioned together into 1 checkpoint parquet file. This means that even with a table that has 1M transactions and has not been vacuumed, the delta reader will still only need to read 1 parquet (the latest checkpoint file) and up to 9 commits that have taken place since the latest checkpoint and the reader will still have the 1M transactions to inform what data is read, without needing to read more than 10 files (1 parquet plus up to 9 json files). Denny Lee has another great blog explaining how this works.
- Default Column Values: you can now set default column values which upon write, if the
DEFAULTkey is used or the column is omitted from the INSERT, UPDATE, or MERGE, the default value will be used. Note: you currently need to enable allowColumnDefaults via TBLPROPERTIES to enable this on table creation.1 2 3 4 5 6 7
CREATE OR REPLACE TABLE column_defaults ( c1 BIGINT, c2 string DEFAULT 'A' ) TBLPROPERTIES ( 'delta.feature.allowColumnDefaults' = 'enabled' )
External Data Sharing
External Data Sharing in Fabric is exactly what it sounds like: the capability of sharing data externally. Entire Lakehouses can be shared with external tenants. I’d have to guess that this feature does not use the OSS Delta Sharing protocol since this supports both Lakehouses + KQL Databases. I hope that
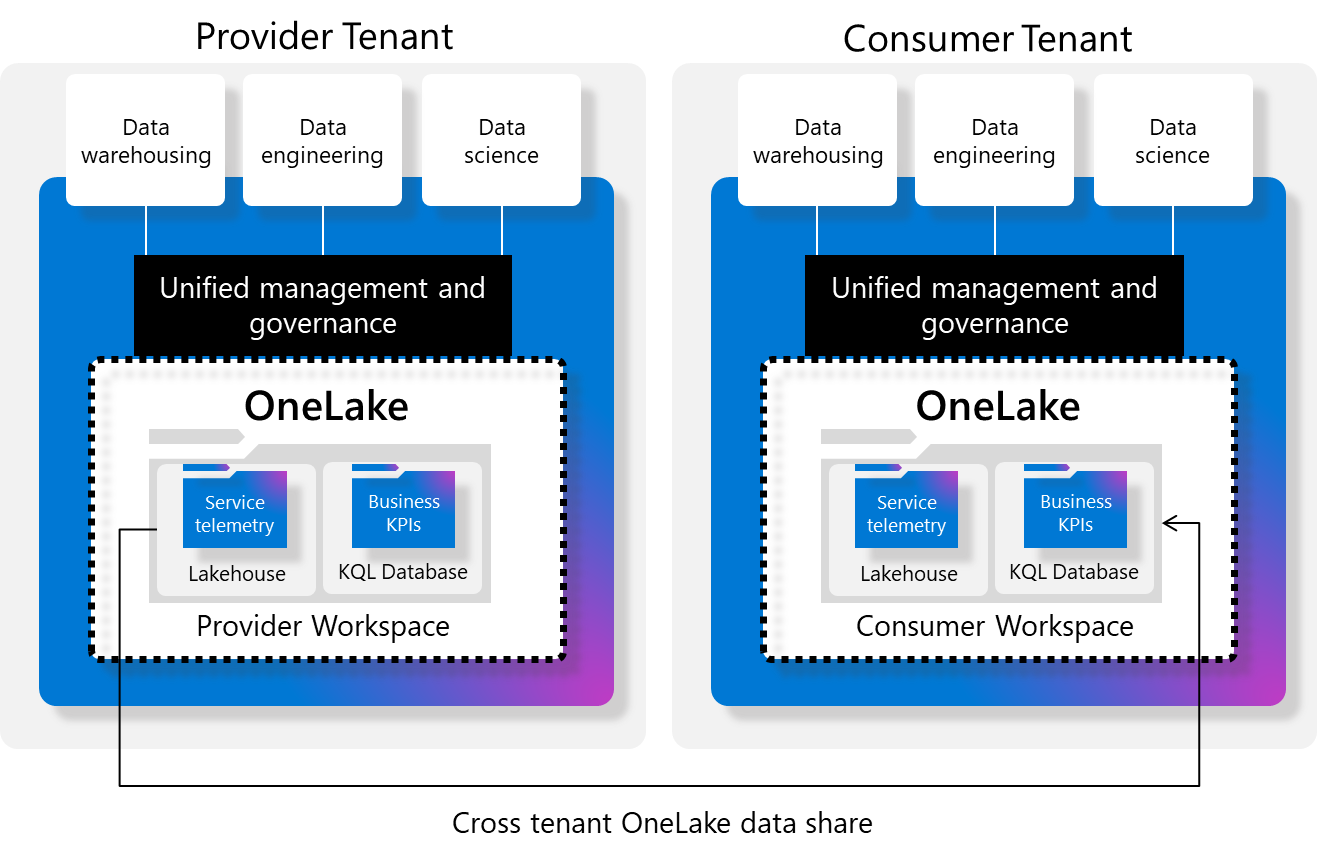 Source: https://learn.microsoft.com/en-us/fabric/governance/external-data-sharing-overview
Source: https://learn.microsoft.com/en-us/fabric/governance/external-data-sharing-overview
⚠️ Important limitation: shortcuts will not resolve when shared externally.
Spark Run Series Analysis
This feature allows you to analyze the run duration and performance over time to identify outliers and potential performance issues. The OSS Spark UI is not the most intuitive so the more tooling that Microsoft can give to help make what is happening and why more comprehensible to your non-expert data engineer the better.
User Functions
User functions in Fabric are Azure Functions but with a super simple and low-friction development experience. Have you ever been bothered by the complexity of deploying Azure Functions via IaC? If so, Fabric User Functions are for you, no complex configuration settings, no annoying lack of idempotency with the WEBSITE_RUN_FROM_PACKAGE setting when deploying via Bicep, Terraform, or ARM.
Data Workflows
I haven’t gotten a chance to play around with Data Workflows yet, however, the concept is super exciting: Apache Airflow with an ADF-like wrapper for monitoring.