At the time of writing this post, Fabric Spark Runtimes enable Optimized Write by default as a Spark configuration setting. This Delta feature aims to improve read performance by providing optimal file sizes. That said, what is the performance impact of this default setting, and are there scenarios where it should be disabled?
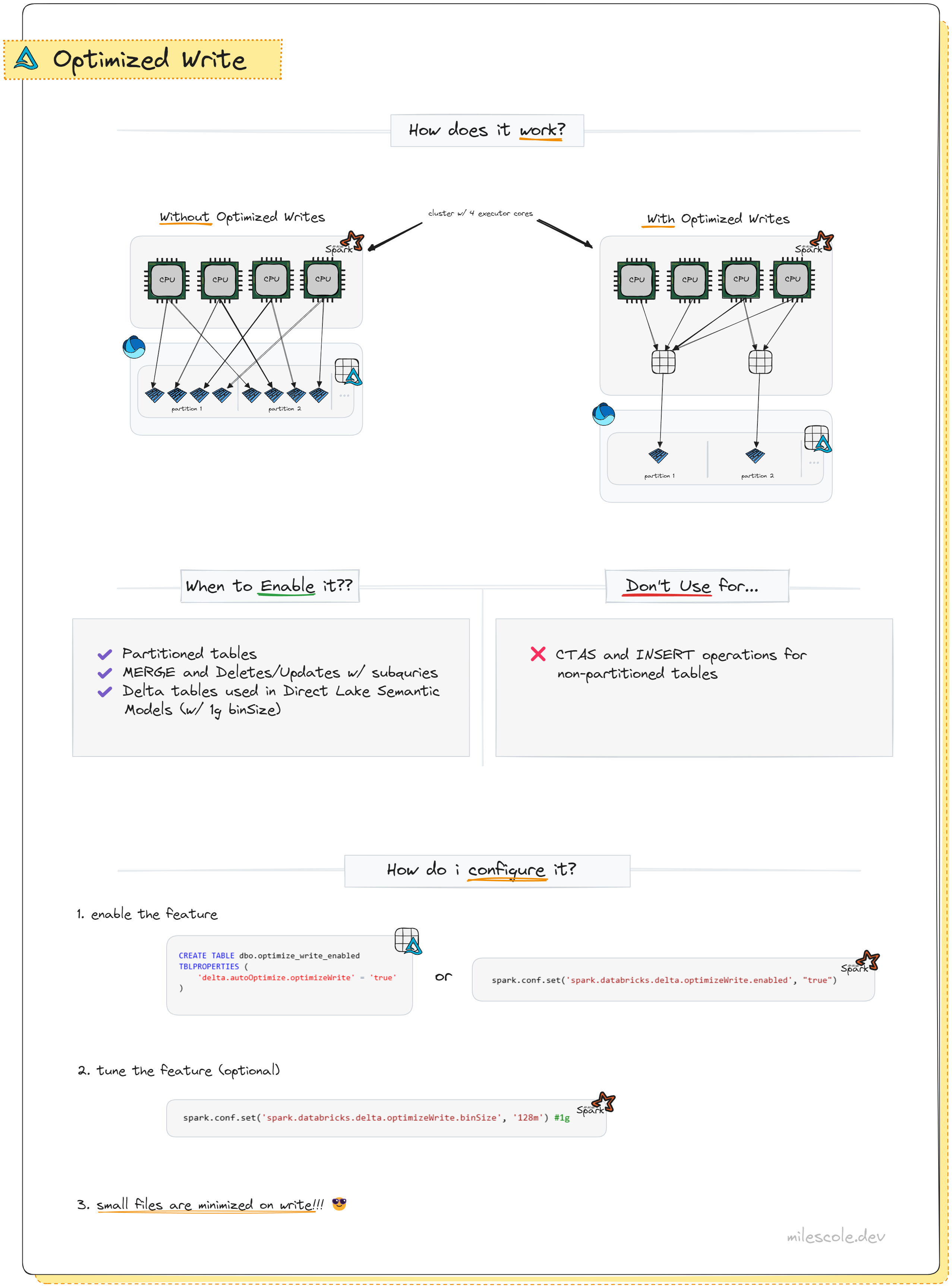
What is Optimized Write?
Optimized Write is a Delta Lake feature that aims to reduce the number of files written as part of a Delta table to mitigate the risk of having too many files. Known as “the small file problem,” when a large number of small files are generated via write operations or accumulated over time, distributed compute systems like Spark can see performance regressions due to the increased overhead of reading and managing many small files.
To draw an analogy: consider you are moving into a new house, it would be inefficient to put just one small item in each packing box or carry a single small item at a time, regardless of how many people you have helping. To maximize efficiency, you would want to fill each box and make sure that the movers (or your friends :)) are carrying as much as reasonable in each trip.
The Optimized Write feature is designed with partitioned tables in mind. When tables are partitioned, you naturally end up with more files since each executor is going to write its own file(s) to the given partition. The more executors and partitions that you have, the more files you will have that make up your table. Reading from a single partition may be efficient, but when reading from many or all partitions, there’s a much higher likelihood of seeing performance degradation because of there being too many small files. Optimized Write solves for this by shuffling data before it is written so that a single executor would contain all data within a given partition to ensure that fewer (and larger) files are written.
Here’s all of the basics of the feature:
The number of files written depends on the BinSize Spark config, which controls the target in-memory size of each file before it is written. In Fabric Runtimes, the setting currently defaults to 1GB. If leaving Optimized Write enabled, you may want to change the BinSize to 256MB or even 128MB depending on your workload.
⚠️ UPDATED 10/1/2024: Starting with Fabric Runtime 1.3, Optimized Write is now controlled via the
spark.databricks.delta.optimizeWrite.enabledspark config and notspark.microsoft.delta.optimizeWrite.enabledproperty that was used in Runtime 1.2. This is because Optimized Write was introduced as a core Delta feature (non-Microsoft specific) starting with OSS Delta 3.1. Jobs using Runtime 1.2 would still use thespark.microsoft.delta.optimizeWrite.enabledproperty.
The BinSize setting can be changed via the code below; integer values are interpreted as MB:
1
spark.conf.set("spark.databricks.delta.optimizeWrite.binSize", 128) # '128m'
The feature can be turned off and on via the below code:
1
spark.conf.set("spark.databricks.delta.optimizeWrite.enabled", "<true/false>")
Or in SparkSQL:
1
SET `spark.databricks.delta.optimizeWrite.enabled` = true
When Should I Use It?
UPDATED 2/5/2025 There are a few scenarios where Optimized Write is beneficial and sometimes even critical to maintain performance of writing to and querying Delta tables via Spark:
- Partitioned Tables: Partitioned tables introduce additional complexities because writes must be distributed across multiple partitions. Each worker core will write its in-memory partition of data to all table partitions that it has data for, this can result in many small files being written.
- Streaming Jobs: Spark Structured Streaming jobs naturally generate smaller files due to the frequency of micro-batch execution. Enabling Optimized Writes helps minimize small file issues before data is written and often with negligible cost.
- Small Workloads: Small workloads == small writes. Make sure to use a small bin size (i.e. 128MB) to avoid over binning files.
Without Optimized Writes:
- UPDATE: Update operations can potentially touch many existing files and if deletion vectors are enabled, this can results in a high likelihood of writing small files.
- MERGE: Merge statements combine updates, inserts, and deletes into one operation and thus has the same implications as individual UPDATEs.
For Spark workloads, arguably there’s really only one standard use case for Optimized Write, partitioning. While the feature does result in shuffling all data before writing it, the improved time to write less files and downstream impact of reading less files (which improves DML operations that require reading the Delta table), often outweighs the shuffle performance hit. You should only ever consider using it for partitioned tables. UPDATED 08/19/24: I was reminded that Optimized Write is important for optimizing Power BI Direct Lake Semantic Model performance.
Considering that this feature results in consolidating data into less files (targeted based on the size of data in-memory), outside of Spark, this feature can be useful for writing out Delta tables for other engines that might be optimized when reading less files. A prime example of this is Power BI Direct Lake Semantic Models: cold cache Direct Lake queries are fastest on average when reading from Delta tables where Optimized Write was enabled with a 1GB bin size. This is why the default Spark config in Fabric uses 1GB as the bin size.
If you are using partitioned tables, consider the number of distinct partitions that you have. If you have a small number of partitions (i.e., less than 10), you may not see much benefit from using Optimized Write given the large overhead involved in shuffling the data.
⚠️
Do not use Optimized Writes if using non-partitioned tables!Only consider using Optimized Write if using partitioned tables or if a critical consumption engine benefits from less files, i.e. Power BI Direct Lake Semantic Models.
Can I use it with Liquid Clustering?
Optimized Write is functionally incompatible with the idea of Liquid Clustering, when both are enabled you'll find that Optimized Write has no bearing on the number of files written.
Liquid Clustering automatically groups values in the cluster key together to optimally and evenly distribute the data. See Denny Lee’s post on Liquid Clustering for a phenomenal explaination of how it conceptually works.
What is the performance impact?
In my testing, reading TPC-DS parquet files and writing out non-partitioned Delta tables, disabling Optimized Write resulted in 35% better performance. Given that the feature can result in a pre-write shuffle of data across executors, it should be used with caution. When files exist that can be binned together and stay under the target bin size, data will be coalesced and if the bin size is too large relative to the workload, it can result in much slower writes.
Writing out partitioned Delta tables would also see the same performance regression; however, we may see improved performance when reading from partitioned tables where Optimized Write was enabled to minimize the number of files, particularly as the number of partitions increases.
To illustrate the potential impact, I created a few different variants of a sales table. I intentionally picked a high cardinality partitioning column, date_sold, to show the magnitude of impact that Optimized Write can have:
| Partitioned By | Optimized Write Enabled | Table Write Duration (hh:mm:ss) | Partition Count | File Count | Data Size | SELECT SUM(profit) FROM… Duration (hh:mm:ss) |
|---|---|---|---|---|---|---|
| date_sold | false | 00:06:43 | 1823 | 175008 | 20,327 MB | 00:01:35 |
| date_sold | true | 00:00:53 | 1823 | 1823 | 15,287 MB | 00:00:05 |
| n/a | false | 00:00:40 | 0 | 96 | 12,767 MB | 00:00:01 |
| n/a | true | 00:01:47 | 0 | 15 | 12,304 MB | 00:00:02 |
Takeaways:
- Optimized Write is often critical to enable on partitioned tables, particularly as the number of partitions increases.
- Creating a table partitioned by a somewhat low cardinality column (1832 distinct values) with Optimized Write disabled resulted in 175,008 parquet files and took almost 8x longer to write! ⚠️ WARNING: SMALL FILE PROBLEM!!!
- This same table had ~33% more MB of data written since the data was so fragmented into many small files that the net data compression suffered.
- Running a simple
SELECT SUM(profit)...from the table with a “small file problem” took 19x longer than the same partitioned table with Optimized Write enabled.
- Partition wisely!
- I intentionally picked a terrible column to partition by; year and month would’ve been a far more appropriate strategy compared to partitioning by date (with day). Don’t over-partition, look for very low cardinality columns that are often used in query predicates.
- Partitioning is often overused.
- The fastest configuration to write and read in this scenario was the table that was not partitioned and had Optimized Write disabled. Less MB of data was written, fewer files were written, the table was written 32% faster, and the simple query ran 5x faster. With this data size, even if the query was filtered on a single date in the where clause, thus allowing the engine to selectively read from a single partition, there would be no meaningful improvement in the duration to execute the query. Don’t partition simply because you can, always partition with strategic intent and validate your thesis.
- Don’t default to enabling Optimized Write for non-partitioned tables!
- Disabling Optimized Write for the non-partitioned table resulted in writing the table 167% faster, and a 2x faster run of the simple query. This is mostly a result of the target
binSizeof 1GB being too large for the given workload.
- Disabling Optimized Write for the non-partitioned table resulted in writing the table 167% faster, and a 2x faster run of the simple query. This is mostly a result of the target
I also ran the TPC-DS power test (99 queries run sequentially) on non-partitioned Delta tables that were created with Optimized Write enabled vs. tables written with Optimized Write disabled. I found that running the test on tables with the feature disabled resulted in 10% better performance at the 1TB scale. This is because the Optimized Write feature resulted in fewer files and, given these tables weren’t partitioned, the effective read parallelism was reduced.
ADDED 08/19/24: Why was reading from 96 files faster than 15 files? Optimizing Spark performance involves fully leveraging all available cores across all executors. In my test cluster, which had a total of 144 executor cores, this meant that up to 144 parallel read tasks could be executed simultaneously. When reading from a Delta table with only 15 Parquet files that each had single row groups, the operation was slower because only 15 read tasks could run in parallel, leading to lower read parallelism and underutilization of the available cores.
Although Spark is capable of parallelizing reads within a single Parquet file (via dividing the file into smaller chunks such as row groups), there is overhead associated with identifying and processing these chunks. As a result, whether Spark will effectively parallelize reading from a single file depends on various factors, including the file’s internal structure and runtime statistics. This can make parallelization less predictable and potentially less efficient compared to reading from multiple files.
Closing Thoughts
As illustrated, while Optimized Write can dramatically improve performance for partitioned tables, enabling the feature for non-partitioned tables, especially if Power BI Direct Lake Semantic models are not being used, can be quite detrimental if not used in the right scenarios.
Don’t be like the sad sap below, if using partitioned Delta tables or managing a workload that naturally writes small files, make sure to test your workload with Optimized Write enabled.
