Every software platform has its own terminology, and when terms overlap but don’t mean the same thing, it can be quite confusing. For example, coming from my years as a developer in Databricks land, I initially assumed that Fabric Spark Pools were just like Pools in Databricks. However, as I discovered, this assumption was completely wrong—and understanding this distinction is key to designing the right architecture.
In this post, I’ll cover the key differences between Spark clusters in each platform in hopes that those with a Databricks background won’t get tripped up like I did.
TL/DR: Fabric Spark Pools <> Databricks Pools
Fabric Spark Pools = Virtual clusters with workspace default software
Fabric Environments = Personalized virtual clusters with custom software
Spark Pools in Fabric vs. Databricks
It’s easy to assume that Fabric Spark Pools are similar to Databricks Pools, this is a reasonable guess based on the name. However, this is not the case, and understanding the difference is vital. While Databricks Pools focus on speeding up cluster startup times by keeping a managed cache of VMs, Fabric Spark Pools serve a completely different purpose.
Databricks Pools: Managed VM Cache
In Databricks, Pools (formerly Instance Pools) are designed to reduce cluster startup latency by maintaining a warm pool of VMs. This allows for quick provisioning of clusters by repurposing the same VMs across different clusters. Essentially, the focus here is on efficiency in starting clusters and reusing resources.
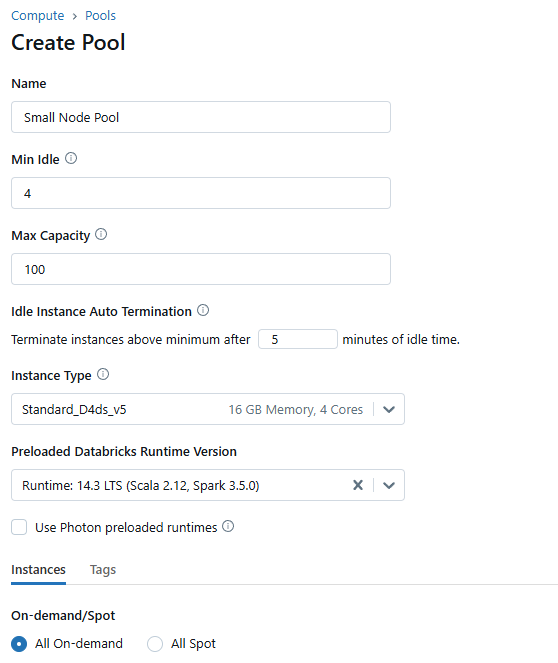
Fabric Spark Pools: Virtual Cluster Configurations
In contrast, Fabric Spark Pools act as virtual cluster configurations that are defined at the workspace or capacity level. Since these are virtual clusters, unless using high-concurrency mode, each Notebook or SDJ that runs targeting a specific Spark Pool will create its own instance of that cluster configuration. This means that you can run many notebooks or job definitions referencing the same Spark Pool without hitting concurrency constraints, aside from what your chosen Fabric SKU specifies.
Within the Spark Pool category, there are two types of Spark Pools in Fabric today, Custom Pools (which can be created at the Workspace or Capacity level) and Starter Pools.
- Starter Pools: allow for consuming nodes from a pool of Microsoft managed VMs that have the Fabric Runtime and Spark already running. This allows for a cluster startup time of about 5 to 10 seconds. This dramatically boosts developer productivity. A few key limitations exist with Starter Pools today:
- They are not available in workspaces that have a managed vNet enabled.
- Autoscale and Dynamic Allocation cannot be disabled.
- Starter Pools only use the Medium node size.
- Additional Starter Pools cannot be created, there is one Starter Pool created by default for every Fabric Workspace.
- Custom Pools: cluster nodes are provisioned on-demand, and therefore the startup time is between 2-4 minutes on average.
The following settings exist for Spark Pools (some of which cannot be changed for Starter Pools):
- Spark pool name
- Node family: right now the only option is memory optimized, in the future I expect that there will be other options such as compute optimized.
- Node size: T-shirt size of node from Small, Medium, Large, XL, and XXL.
- Autoscale: Flag to determine whether the cluster will scale executors up and down dependent on compute needs.
- Node count: Count of nodes (w/ min/max if autoscale is enabled). A few important points:
- The count of nodes is inclusive of the Driver. If you want to run a job on a cluster with 4 workers (nodes) you need to set the node count to 5 (4 workers + 1 driver).
- Setting the node count to 1 makes it a single node cluster where 1 core on the node acts as the driver, and the rest of the cores act as individual workers.
- Dynamic Allocation: allows the number of executors allocated to a Spark application to be dynamically adjusted based on the workload. When enabled, Spark can automatically add or remove executors during the runtime of a Spark job based on the stage of the job and the resource requirements at any given time.
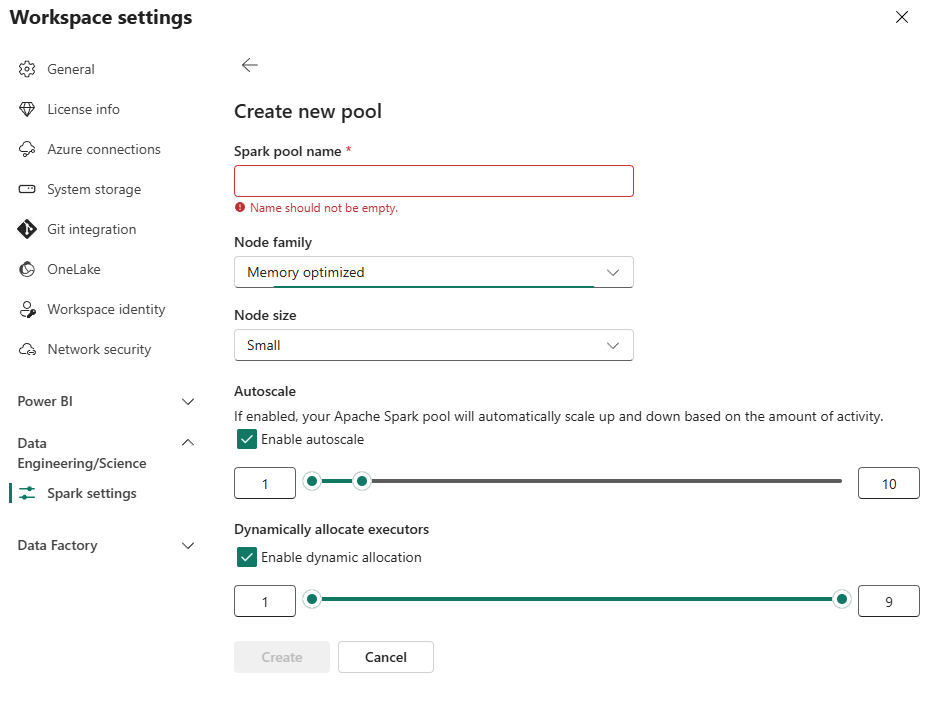
You’ll notice that Spark Pools do not allow you to set the Runtime version, libraries, spark configs, etc. This is where Environments come into play.
Fabric Environments: Personalized Virtual Cluster Configurations
Environments in Fabric allow you to further customize how a cluster is created by configuring software settings like libraries, Spark configurations, the Fabric Runtime version, and even fine tuning the size and scale settings defined in Spark Pools. This separation between Spark Pools, which focus on hardware, and Environments, which focus on software, allows for a more modular approach to managing Spark clusters.
This separation means that as a workspace admin, you can define a few Spark Pools that fit your users’ needs, and then users can apply different environment configurations as needed, such as installing specific libraries, setting cluster configurations, and/or choosing a specific Fabric Runtime.
Databricks Clusters: Personalized Clusters
Lastly, we have Clusters in Databricks. Clusters can contain all hardware and software configuration settings OR you can use them in conjunction with Pools so that the nodes of the Cluster come from the managed pool of VMs. Using Cluters with Pools is typically useful for decreasing latency between jobs in production scenarios since the 2-4 minute cluster start up time can be reduced to ~ 40 seconds if you have warm nodes in your pool.
To enforce the use of specific compute sizes, similar to Spark Pools, Databricks provides Policies which can be used to enforce that new clusters are created per the defined specs or limits.
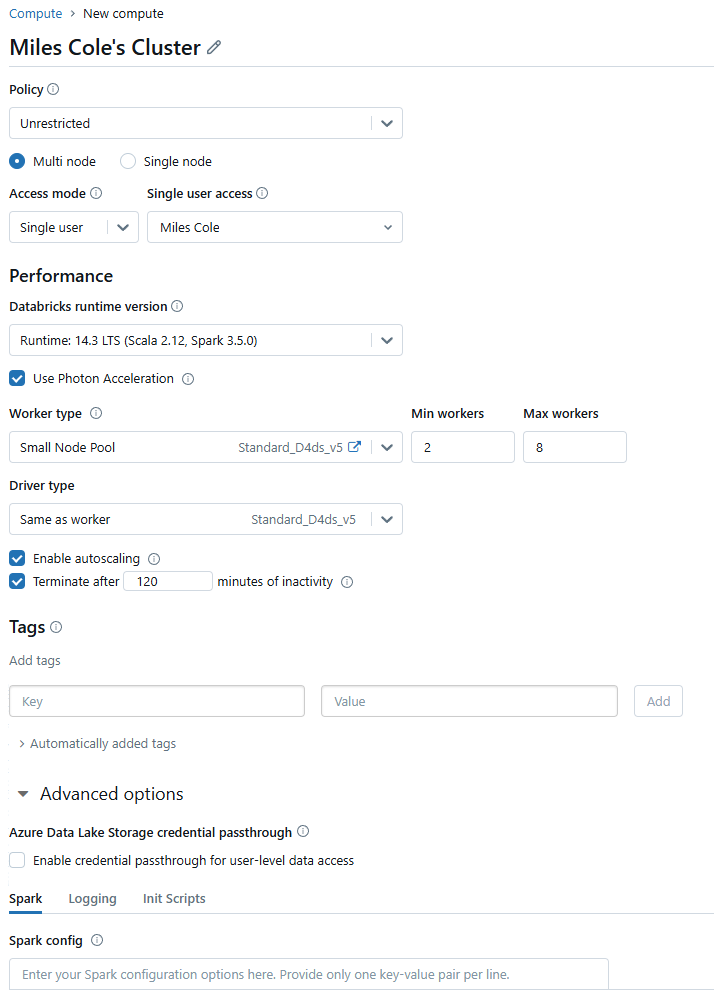
VM SKU Options
In Databricks, you select which Virtual Machine (VM) SKU to use for your driver and executors, while having this option is nice for those well versed in VM specs, there’s a very strategic reason why there’s no VM SKU option beyond the Node Type when configuring Fabric Spark Pools: most developers are not experts in the specs and price/performance metrics of various different VM options. However, Microsoft is, and therefore keeps Fabric Spark running on VM SKUs by region that provide the best price/performance mix.
In today’s fast changing world of compute, I much prefer having this managed and maintained automatically for a few reasons:
- Keeping up with new chip performance improvements: Every year there’s a newer generation of Intel and AMD chips, this potentially leaves you with 2 times a year that you might need to test your workloads, request vCore Family specific quota increases, and update source code (or potentially manually update deployed clusters and job schedules) to ensure that the newest and fastest chip is being used. In Fabric, this isn’t something you need to worry about and your can’t fall into the scenario where you’re just too busy with new business priorities to update the configuration of a bunch of stable jobs you haven’t touched in ages.
- Keeping up with SKUs that get deprecated, retired, or have limited capacity: With next generation hardware being available, naturally, prior-generation hardware typically stops being deployed, and old hardware gets replaced. If you are running workloads on prior-generation hardware there’s a good chance you’ll run into capacity limits at some point, and as every year goes by, the chances of hardware retirement increases. Again, in Fabric you don’t have to worry about this.
Cost Differences
There are 4 primary differences between Fabric and Databricks that should be considered when budgeting or comparing each:
1. Billing Model
Fabric Capacities
This one is obvious and well known, likely because it is admittedly counterintuitive for data engineers coming from Azure services that have true pay-per-consumption models. Building on its Power BI platform heritage, Fabric uses a Capacity model. In this model, you purchase a certain amount of compute power, measured in Capacity Units (CUs). These CUs can be utilized across any Fabric workload within the converged data platform, including Spark, data warehousing, real-time streaming, reporting, machine learning, custom APIs, and more. Fabric SKUs purchased via the Azure portal operate in pay-as-you-go mode, meaning that you can create a capacity, run a workload, and then pause your capacity.
Databricks
Databricks operates on a pure pay-as-you-go model, you pay for the compute used plus a licensing multiplier. If you run a cluster for 5 minutes, you pay for 5 minutes, no need to pause a capacity. Depending on the feature used, the multiplier will vary. As a general rule of thumb, anytime you deviate from open source capabilities and use Databricks propriatary tech (i.e. Photon, Delta Live Tables, and Serverless Compute), the licensing multiplier is significantly higher. Licensing multipliers are important to consider in designing a solution as it may change how you actually organize and orchestrate your processes, see my post on the TCO of Photon in Databricks for more details.
2. Billing Rates
People often want to know which is cheaper. The answer however, is extremely complicated because both operate on completely different billing models and each has it’s situational nuances.
Cost per vCore Hour
To evaluate the cost of each, I prefer to look at an atomical job and compare the effective cost of that single job. After understanding this cost, I then extrapolate it as part of an all-up platform cost. To do this we need to know the job duration, cluster size, and the vCore cost per hour including any licensing fees. The follow rates are from the West Central US Azure region, using my go-to VM SKU family in Databricks as the benchmark: Edsv5. Microsoft doesn’t publish the VM SKU used in Fabric as it can vary by region and will change over time (which is reflected in the Fabric F SKU pricing), however the Edsv5 or Easv5 VM families match the most important VM specs.
| Workload | Total Cost per vCore Hour | Hardware Cost per vCore Hour (Edsv5) | Licensing Cost per vCore Hour |
|---|---|---|---|
| Fabric Spark | $0.10 | $0.09 | $0.01 |
| Fabric Spark w/ Native Execution Engine | $0.10 | $0.09 | $0.01 |
| Databricks Jobs Compute | $0.20 | $0.09 | $0.11 |
| Databricks Jobs Compute w/ Photon | $0.37 | $0.09 | $0.28 |
| Databricks All-Purpose Compute | $0.30 | $0.09 | $0.21 |
| Databricks All-Purpose Compute w/ Photon | $0.50 | $0.09 | $0.41 |
⚠️ These are point-in-time costs at the time this blog was written, rounded to the nearest hundreth of a cent, subject to change, and for illustration only. Neither Microsoft Fabric nor Databricks advertise costs per vCore hour, this is an attempt to standardize billing models for comparison purposes at the lowest compute grain, 1 vCore used for 1 hour.
Interactive vs. Scheduled Rates
As illustrated above, your vCore cost per hour is dependent on various factors, some of which I didn’t consider for sake of not boiling the ocean (DLT, interactive serverless compute, automated serverless compute, serverless SQL, etc.). However, a major billing difference between the platforms comes down to how the code is being executed.
In Databricks, if you are running a notebook interactively (All-Purpose Compute) for development or to share compute across jobs via a high-concurrency cluster, you pay more in licensing compared to if it was an automated scheduled job (Jobs Compute). Yes, even with the exact same cluster size and run duration, a Notebook executed interactively or jobs run in high-concurrency mode, costs ~47% more for non-Photon and ~35% more for Photon compared to the same job that was scheduled or submitted as a standlone non-interactive job.
In Fabric, there’s no deliniating between an interactive and scheduled job, both emit the same CU consumption rate, $0.10 per vCore hour.
3. When Billing Meters Start
Another key difference between Fabric and Databricks Spark is when billing meters start to run.
Fabric’s Approach to Billing Meters
If the fact that starter pools starting in about 15 seconds isn’t just the bees knees, consider that these pools don’t consume capacity units (CUs) when not in use, CUs are only consumed once your Spark Session starts. That’s right, even when the starter pool nodes are being personalized with custom libraries, etc., CUs are not consumed/billed.
The documentation has a great illustration for this:
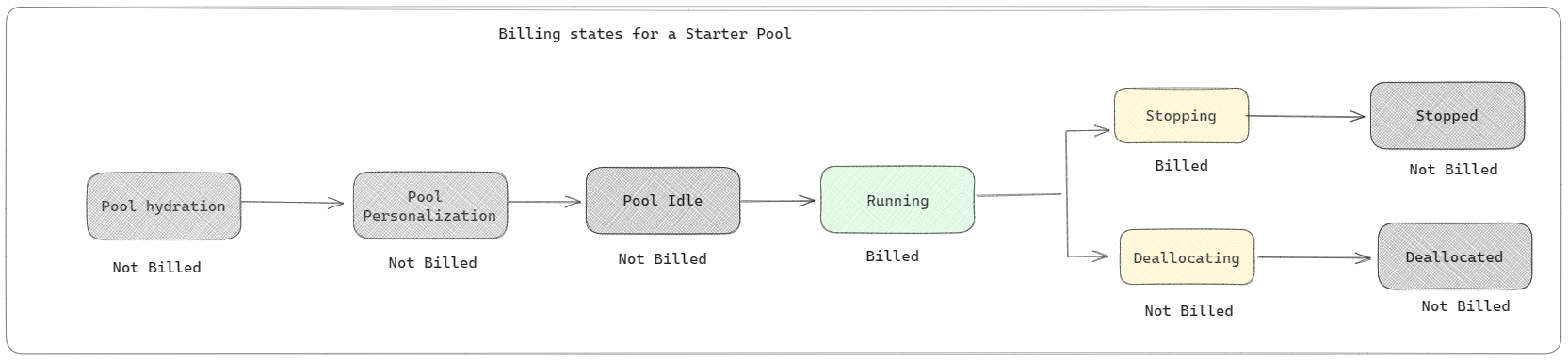
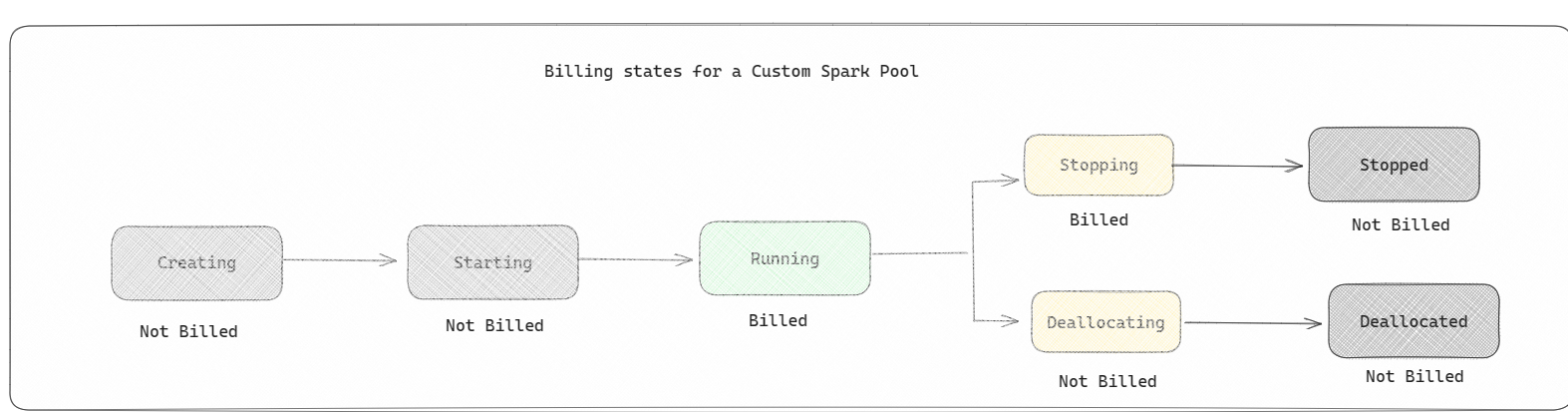
For Custom Pools, it’s the same: you are only billed once your Spark Session begins:
Databricks’ Approach to Billing Meters
In Databricks, you start paying for VMs as soon as they are provisioned, which is reasonable given that the VM is active. Additionally, once the Spark context is initiated (which typically takes 40+ seconds), Databricks charges licensing fees (DBUs). If you have a pool of VMs sitting idle, you are billed for the hardware every second they remain in the pool.
4. Billing Reservations
Fabric currently offers one year reservations on Fabric SKUs that provides a 40% discount on pay-as-you-go pricing. Note, just like other reservation models, purchasing a reservation only makes sense if intending to keep the capacity enabled 24/7. That said, Fabric capacities have a feature called smoothing where capacity demand is spread forward across a rolling 24 hours window to reduce job contention and scheduling concerns.
With Databricks you can separately purchase one or three year virtual machine reservations (~41% and ~62% respective savings), however this really only makes sense if you have VMs running 24/7 as the Azure VM reservation model is designed for truly consistent hardware needs. For Databricks licensings fees known as DBUs (Databricks Units), you can prepurchase DBUs with volume discounting that is valid for a one or three years. If prepurchasing DBUs, just like Fabric Capacities, it is a use it or lose it model, so plan accordingly.
Closing Thoughts
Understanding the differences in how Spark clusters works between Fabric and Databricks is essential for making informed decisions about your architecture. Fabric’s approach of separating hardware configuration (Spark Pools) from software customization (Environments) offers a flexible and modular system that can adapt to various needs and with the opportunity for greatly improved developer productivity via access to low latency starter pools.