One of the most critical challenges in large-scale data processing with Apache Spark is tracking what each job is doing. As Spark applications grow in complexity, understanding what’s running and when can become difficult, especially when looking at the Spark UI.
In this blog, we’ll explore a couple spark settings which allow for improving visibility in the Spark UI, making it easier to identify jobs, debug, optimize, and manage your applications. You’ll learn how to annotate your jobs with meaningful descriptions, organize related tasks into groups, and leverage these features to streamline your debugging and performance-tuning efforts.
The Challenge of Job Visibility in Spark
While Spark tends to be very flexible in terms of the lazy evalutation model resulting in highly efficient execution plans, when things do run longer than expected or things fail, it can be very challenging to triage.
While the Spark UI makes a massive amount of telemetry accessible, which platforms like Microsoft Fabric surface much of this information via native tooling, understanding what you are looking at is often quite daunting and confusing. Even if you understand the concepts of Jobs, Stages, Tasks, etc., the first step in troubleshooting is often identifying the specific job associated with the issue or correlating something that’s slow in the Spark UI back to meaningful code.
The challenge arises in how Spark names or describes operations in the UI—especially for jobs that are parameterized, called via functions, or executed in loops. By default, jobs are labeled based on the first line of code that results in an action. For instance:
spark.sql("OPTIMIZE customer")
When you check the SQL/DataFrame tab of the Spark UI, the operation is easy to identify because the table name is hardcoded. However, this clarity disappears in more dynamic or parameterized workflows, making it harder to track down the relevant job.
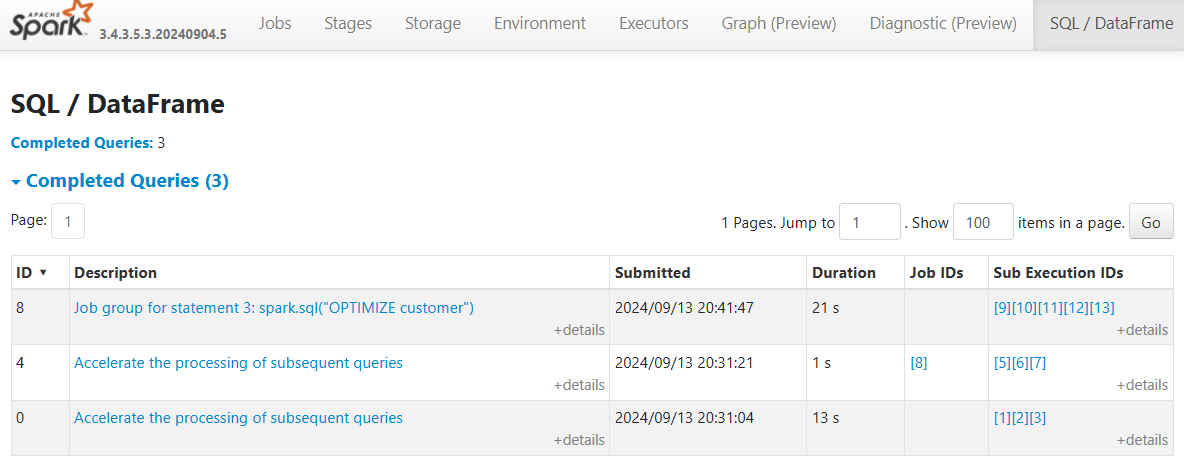
Consider a more typical scenario where we are building a scalable spark application where we want to programmatically perform bulk ELT operations. In this case the goal is to run OPTIMIZE on all tables:
tables = spark.catalog.listTables()
for table in tables:
spark.sql(f"OPTIMIZE {table.name}")
Now that we are iterating over a list and our Spark operation is not statically typed, the Spark UI doesn’t provide any high level metadata to identify which table each query relates to.
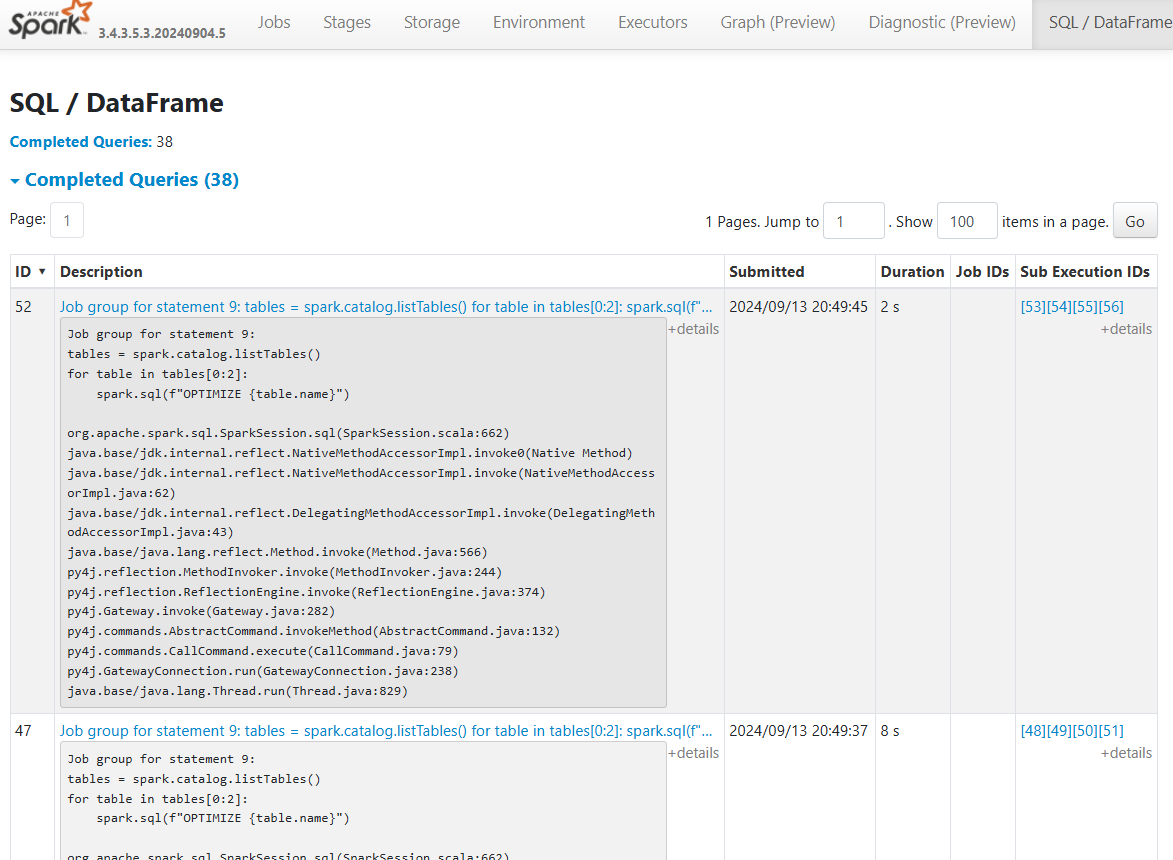
Sure, you could drill into the the query execution plan to find metadata which references the table name or ABFSS path, however that significantly slows down the process of triaging performance in spark, particularly as the number of operations you run in a Spark application increases.
Using setJobDescription()
The setJobDescription()method is used to override the default description of jobs in Spark to make the description human readable. We can wrap our spark operation in spark.sparkContext.setJobDescription(), when set this will result in all operations being logged with the defined description until the description is programmatically changed or set to None.
tables = spark.catalog.listTables()
for table in tables:
# set the description of all following spark jobs
spark.sparkContext.setJobDescription(f"Running OPTIMIZE on {table.name}")
spark.sql(f"OPTIMIZE {table.name}")
# disable the user defined description
spark.sparkContext.setJobDescription(None)
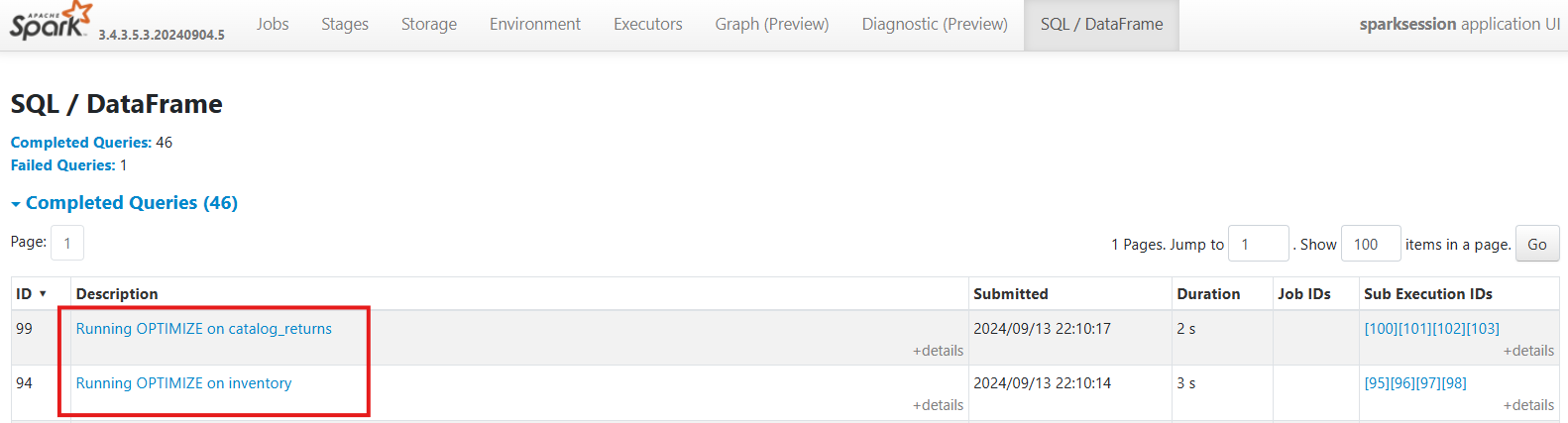
Now when the code is executed, the Spark UI returns descriptions that allow us to immediately know which table the OPTIMIZE command was run on. If we had a performance issue, we would immediately know which process it relates to.
Using setJobGroup()
The setJobGroup() method in Spark allows you to group related Spark jobs together under a common group ID and description. By default, all Spark operations executed in a single notebook cell or job submission are considered part of the same job group. However, setJobGroup() provides the flexibility to explicitly define job groups, making it easier to track related jobs and operations in the Spark UI.
This method is particularly useful when you have multiple stages of processing that are logically connected (e.g., ELT workflows, multi-step transformations, optimizations, or maintenance jobs), and you want to track and monitor these phases as a single unit.
spark.sparkContext.setJobGroup(groupId, description, interruptOnCancel=False)
groupId: A unique identifier for the group.description: A human-readable description that will appear in the Spark UI for all jobs within this group.interruptOnCancel: If set to True, it will interrupt the tasks if the group is canceled.
Example Use Case
Imagine you are processing a dataset where each table undergoes multiple steps: reading, cleaning, and optimizing. You want to group all operations related to a specific table under the same group ID so you can track progress easily and cancel all related tasks if needed.
tables = ['customers', 'orders', 'transactions']
for table in tables:
# Set a job group for all operations related to this table
spark.sparkContext.setJobGroup(f"processing_{table}", f"Processing {table} data", interruptOnCancel=True)
# Perform multiple operations on each table under this group
spark.sql(f"SELECT * FROM {table}").show()
spark.sql(f"OPTIMIZE {table}")
spark.sql(f"VACUUM {table}")
Once setJobGroup() is set, all Spark jobs in the active thread will be related to a particular group (in this case, processing_customers, processing_orders, etc.) and will appear in the Jobs tab of the Spark UI with the group description you provided. This allows you to:
- Track Jobs by Group: Easily identify which jobs are part of the same group. If one stage of the processing takes longer or fails, it’s easier to trace back to all jobs related to that specific table.
- Cancel a Group of Jobs: If you realize something is wrong with the processing of a specific table, you can cancel all jobs under that group ID using:
spark.sparkContext.cancelJobGroup(f"processing_{table}")This is particularely useful in the context of multithreading where you may kick off a thread of jobs asynconously and need to cancel the job group based on an event from another thread.

Closing Thoughts
Sure, it would be great if the Spark UI provided better default logging for Spark queries, like displaying the actual query in the expanded details of the job description. However, we do have the ability to add our own custom descriptions to improve clarity. Strategic use of both setJobDescription() and setJobGroup() is essential for building scalable Spark applications that are much easier to debug. Whenever you’re executing parameterized, iterative, or function-based Spark operations, it’s crucial to provide your future self with meaningful and enhanced metadata in the Spark UI for better traceability.