If there anything that data engineers agree about, it’s that table compaction is important. Often one of the first big lessons that folks will learn early on is that not compacting tables can present serious performance issues: you’ve gotten your lakehouse pilot approved and it’s been running for a couple months in production and you find that both reads and writes are increasingly getting slower and slower while your data volumes have not increased drastically. Guess what, you almost surely have a “small file problem”.
What engineers won’t always sing the same tune on is how and when to perform table compaction. There’s really 5 things I see when looking generally at any platform using log-structured tables like Delta, Hudi, or Iceberg:
- No Compaction: We’ve all been there at some point in our career, no shame. You came from using SQL Server or Oracle with nice clustered indexes where any infrequent table rebuild operations were handled by a company DBA. Life was easy. While not a good option, it’s important to understand the impact of not having any compaction strategy. Yes, it’s a slow burn that takes you deeper and deeper down the poor performance rabbit hole.
- Pre-Write Compaction: Rather than needing to compact files, introduce a pre-write shuffle of data that ensures optimal sized files are written. In Delta this feature is called Optimized Write.
- Post-Write Manual Compaction: As part of your jobs you’ve coded an
OPTIMIZE(and possibly aVACUUM) operation to run after every table that is written to. - Scheduled Compaction (Manual): Just as it sounds, you schedule a job, maybe on a weekly basis, that will loop through all tables and run
OPTIMIZE. - Automatic Compaction: A feature of the log structured table that will automatically evaluate if compaction is needed and run it syncronously (or async in the case of Hudi) following write operations.
- Delta Lake: Auto Compaction is disabled by default but can be enabled to run syncronously, as needed, after writes. Here’s a all the basics on Auto Compaction in Delta Lakes:
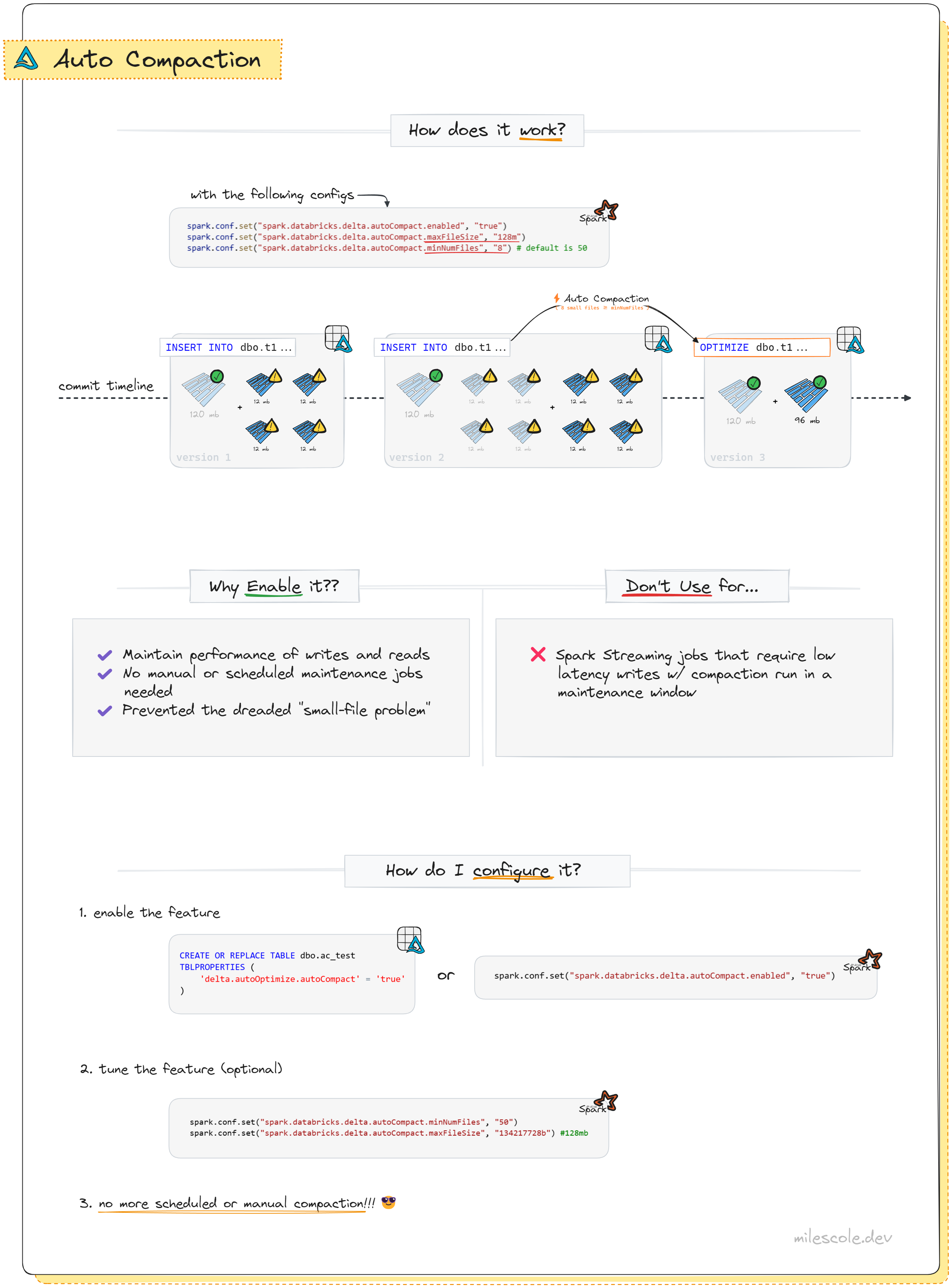
- Hudi: Compaction runs automatically (async) by default, as needed, after writes.
- Iceberg: Compaction in Iceberg is only supported as a user executed operation, there’s no support for automatic maintenance here. Ironically, the Iceberg docs even list compaction under Optional Mainenance, this seems a bit shortsighted as there’s no technical reason why Iceberg users wouldn’t suffer from small file issues just like Delta and Hudi.
- Delta Lake: Auto Compaction is disabled by default but can be enabled to run syncronously, as needed, after writes. Here’s a all the basics on Auto Compaction in Delta Lakes:
- Background Platform Managed Compaction: The first things that comes to mind is S3 Tables (AWS proprietary fork of Iceberg) with it’s heavily marketed managed compaction feature. You write and query your tables and we will charge you an exhorbinant amount to perform background compaction jobs so you don’t need to worry about table maintenance! While AWS may have gotten some flak their pricing ($0.05 per GB + $0.004 per 1,000 files processed) and overmarketing a feature that Hudi and Delta already solve for, not needing to manage or even configure compaction is a wonderful thing since it reduces the compelxity and experience needed to implement a performant solution.
So, there’s plenty of options for ensuring tables are appropriately sized. But, is there a best practice option when using Fabric Spark and Delta Lake? Lets find out.
The Case Study
To study the efficiency and performance implications of various compaction methods, I formed a benchmark to study the effects of the following 4 scenarios:
- No Compaction
- Pre-Write Compaction (a.k.a Optimized Write)
- Scheduled Compaction
- Automatic Compaction
I ran all tests using an iteration target batch count of 1K, 100K, and 1M rows. Each test consisted of running 200 back-to-back iterations of the below phases to immitate a table that has been updated long enough to start seeing small file issues:
- Merge Statement: data is generated with a target row count with +/- 10% random variance in batch size and is merged into the target table with 10% of the input records being updates and the rest being inserts.
data = spark.range(start_range, end_range + 1) \ .withColumn("category", sf.concat(sf.lit("category_"), (sf.col("id") % 10))) \ .withColumn("value1", sf.round(sf.rand() * (sf.rand() * 1000), 2)) \ .withColumn("value2", sf.round(sf.rand() * (sf.rand() * 10000), 2)) \ .withColumn("value3", sf.round(sf.rand() * (sf.rand() * 100000), 2)) \ .withColumn("date1", sf.date_add(sf.lit("2022-01-01"), sf.round(sf.rand() * 1000, 0).cast("int"))) \ .withColumn("date2", sf.date_add(sf.lit("2020-01-01"), sf.round(sf.rand() * 2000, 0).cast("int"))) \ .withColumn("is_cancelled", (sf.col("id") % 3 != 0)) delta_table_path = f"abfss://<workspace_name>@onelake.dfs.fabric.microsoft.com/<lakehouse_name>.Lakehouse/Tables/auto_compaction/{iteration_id}" if not DeltaTable.isDeltaTable(spark, delta_table_path): data.createOrReplaceTempView("input_data") if auto_compaction_enabled: ac_str = "TBLPROPERTIES ('delta.autoOptimize.autoCompact' = 'true')" else: ac_str = "" spark.sql(f""" CREATE TABLE mcole_studies.auto_compaction.`{iteration_id}` {ac_str} AS SELECT * FROM input_data """) delta_table = DeltaTable.forPath(spark, delta_table_path) else: delta_table = DeltaTable.forPath(spark, delta_table_path) delta_table.alias("target").merge( source=data.alias("source"), condition="target.id = source.id" ).whenMatchedUpdateAll() \ .whenNotMatchedInsertAll() \ .execute() - Aggregation Query: The query touches every column in the table and does not have any filter predicates to ensure that all files in the current Delta version are included in scope.
select sum(value1), avg(value2), sum(value3), max(date1), max(date2), category from mcole_studies.auto_compaction.`{iteration_id}` group by all - Compaction: only applicable for the Scheduled Compaction test, every 20 iterations the
OPTIMIZEcommand is executed.spark.sql(f"OPTIMIZE delta.`{delta_table_path}`")
For each phase of the iteration I logged the duration and count of files in the active Delta version.
Active File Count - 1K Row Batch Size
Before getting into the performance comparison of running these tests, let’s baseline how each scenario impacts the number of files written:
The following charts intentionally use the same Y axis max value for evaluating the magnitude of impact.
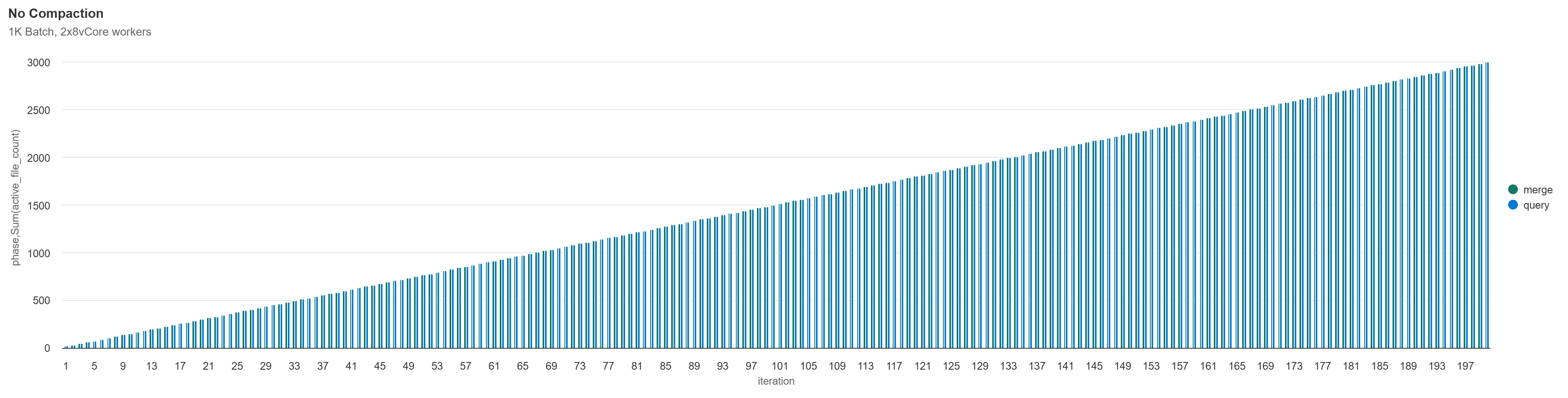
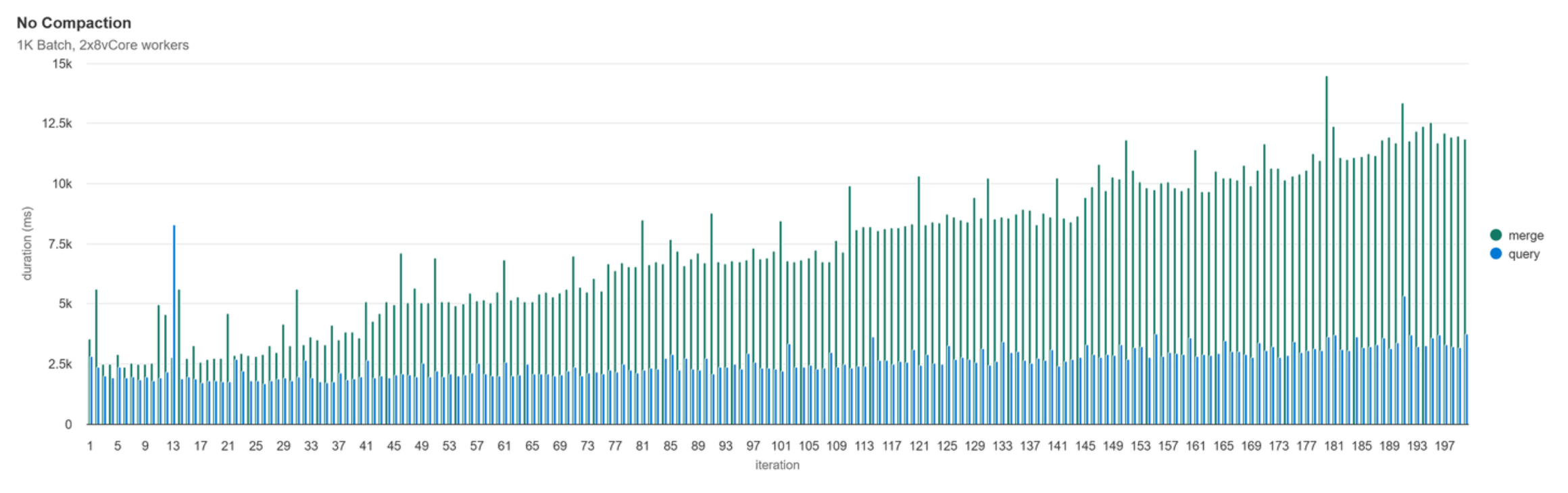
No Compaction
As expected, since we aren’t performing any maintenance, the count of parquet files in the active Delta version increases linearly. After 200 iterations, we have 3,001 files.
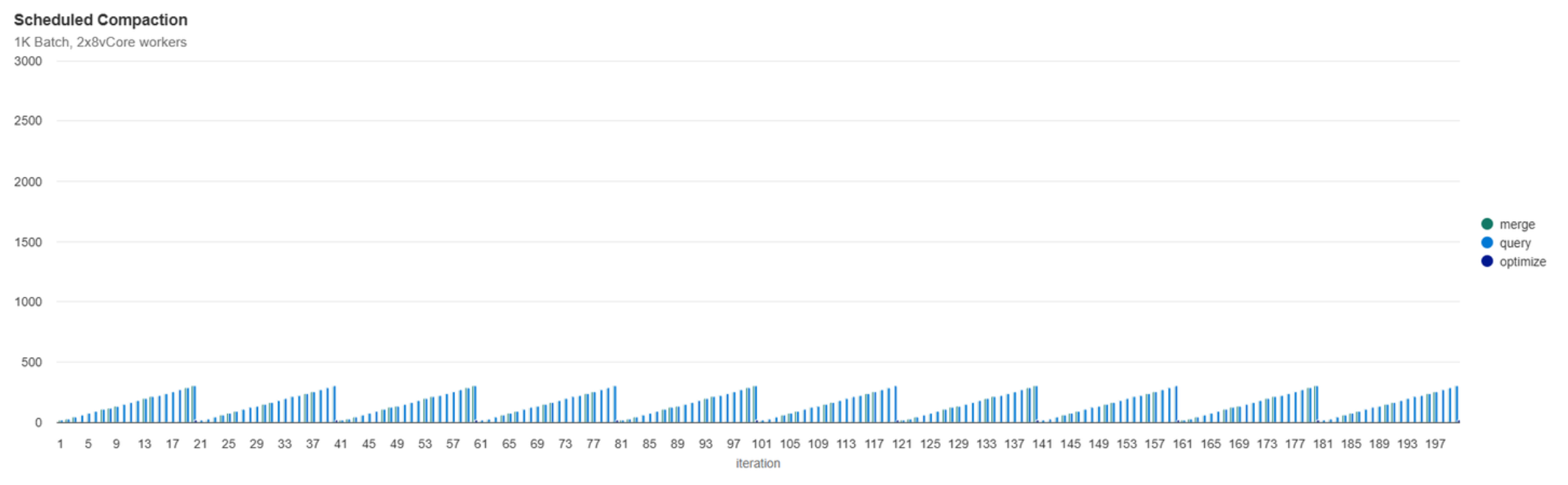
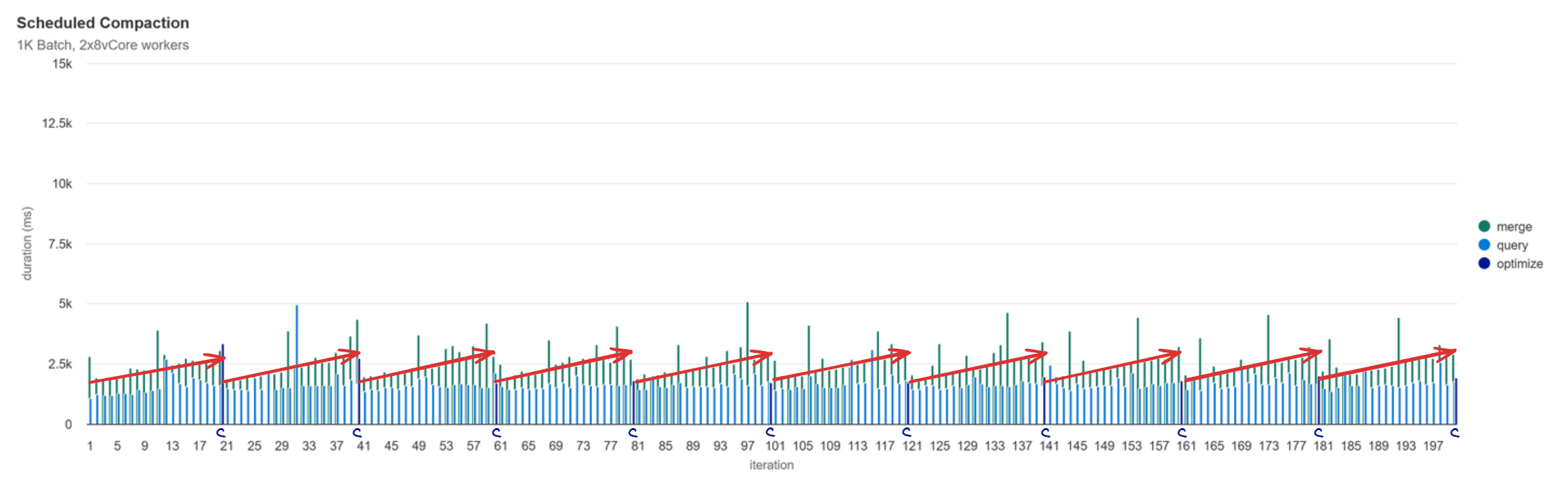
Scheduled Compaction
With compaction scheduled to run every 20th iteration, the final file count is 1 due to it ending on a compaction interval. The file count peaks at > 300 right before each compaction operation is run.
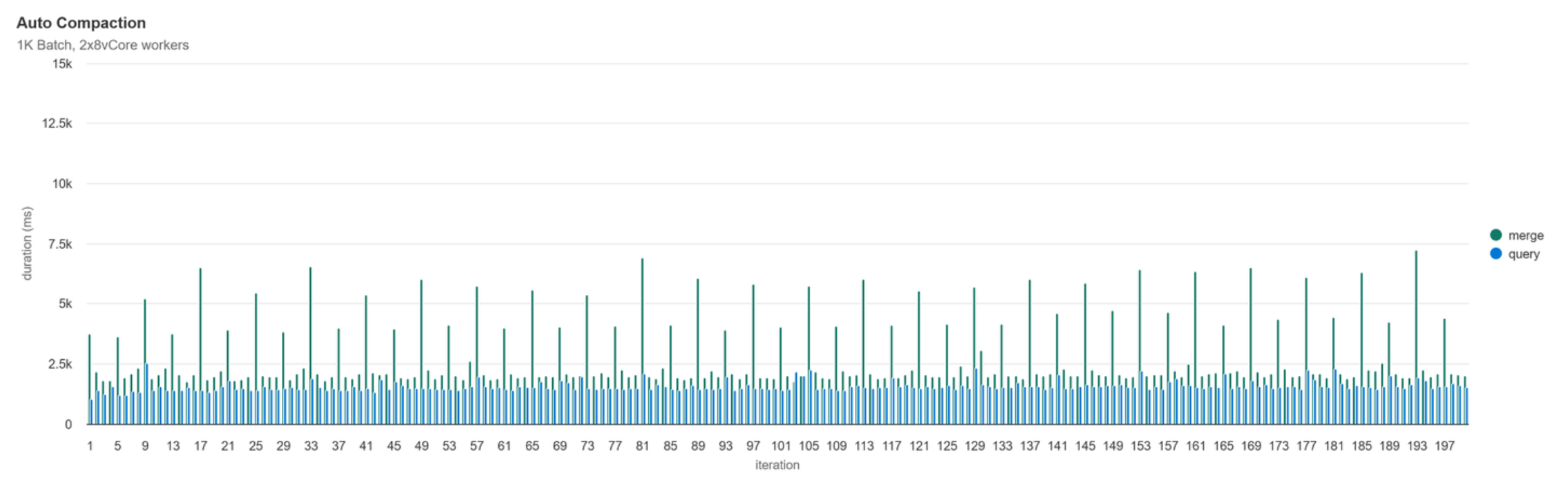
Automatic Compaction
With Auto Compaction, based on this workload, we see that every 4 iterations results in the background, syncronously run, min-compaction job. After 200 iterations we have 47 files, this makes sense as by default auto-compaction triggers whenever there is 50 or more files below 128MB.
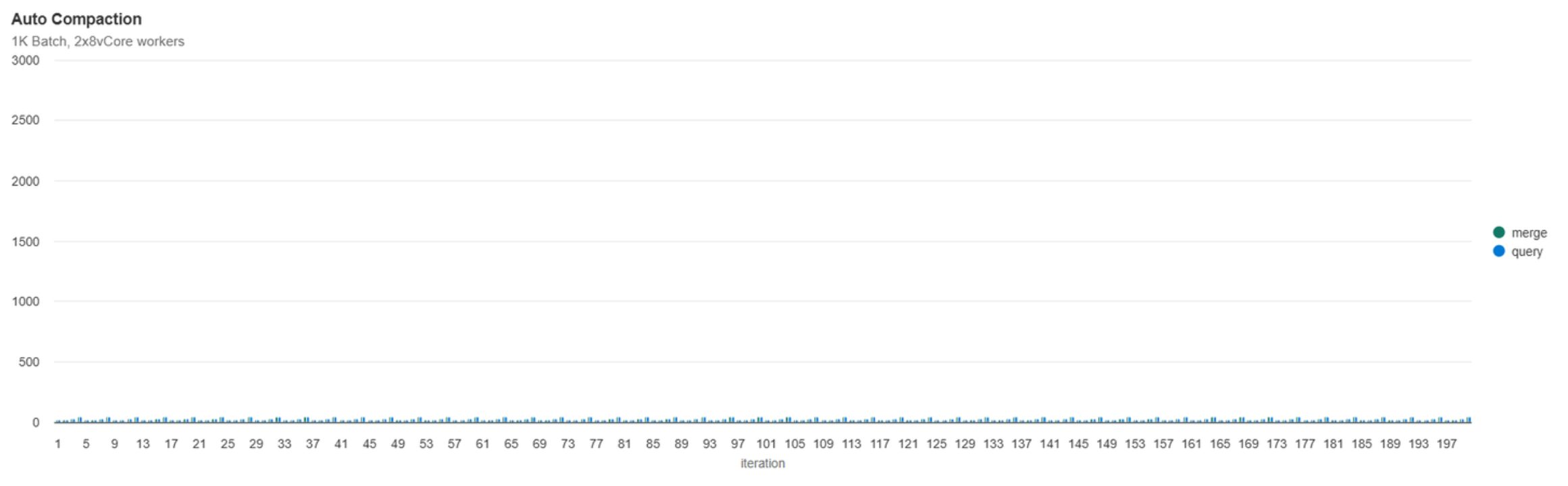
Automatic compaction certainly produces the most optimal file layout after 200 iterations, it has by far the lowest standard devation of file count which will result in more consistency in both write and read performance.
Performance Comparison - 1K Row Batch Size
No Compaction
Without any compaction, by iteration 44 the write duration has doubled and by iteration 200 the merge operation now takes nearly 5x longer to complete. Reads were impacted less, but by the last iteration had surpassed being 1.5x slower.
Scheduled Compaction
With compaction every 20th iteration, we see that the performance of both writes and reads gets slower until the compaction operation runs.
Automatic Compaction
With automatic compaction, just like how there’s the lowest standard deviation in the active file count, we also see that performance is extremely stable. Both the write and query duration from start to end have no discernable upward trend. What is noticeable though is that every 4th write operation after the first, we can see that the merge step takes over 2x longer since it is performing the min-compaction.
With the frequent mini-compactions taking place, this begs the question: can we avoid writing small files to begin with?
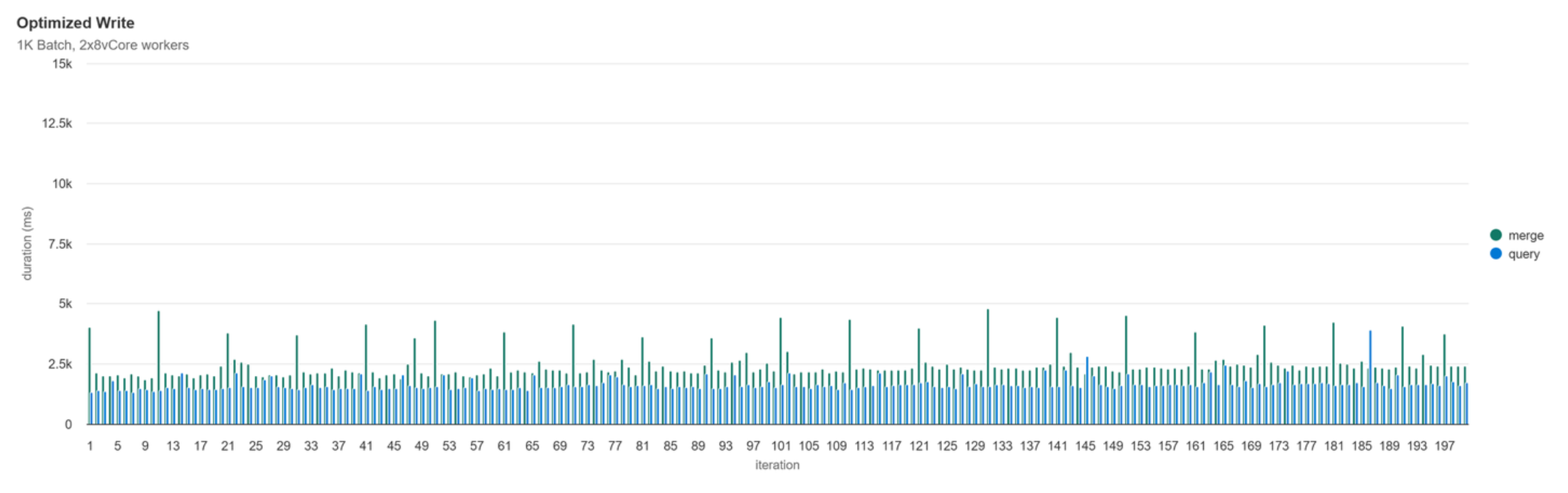
Optimized Write
If we refresh our knowledge on Optimized Write, the idea is that there’s a pre-write step where data is shuffled and grouped across executors to bin data together so that fewer files are written. This feature is critical for partitioned tables, however for non-partitioned tables there are even a few write scenarios where more files are typically written due to the nature of the operation, and optimized write can help prevent this:
- MERGE statements
- DELETE and UPDATE statements w/ subqueries
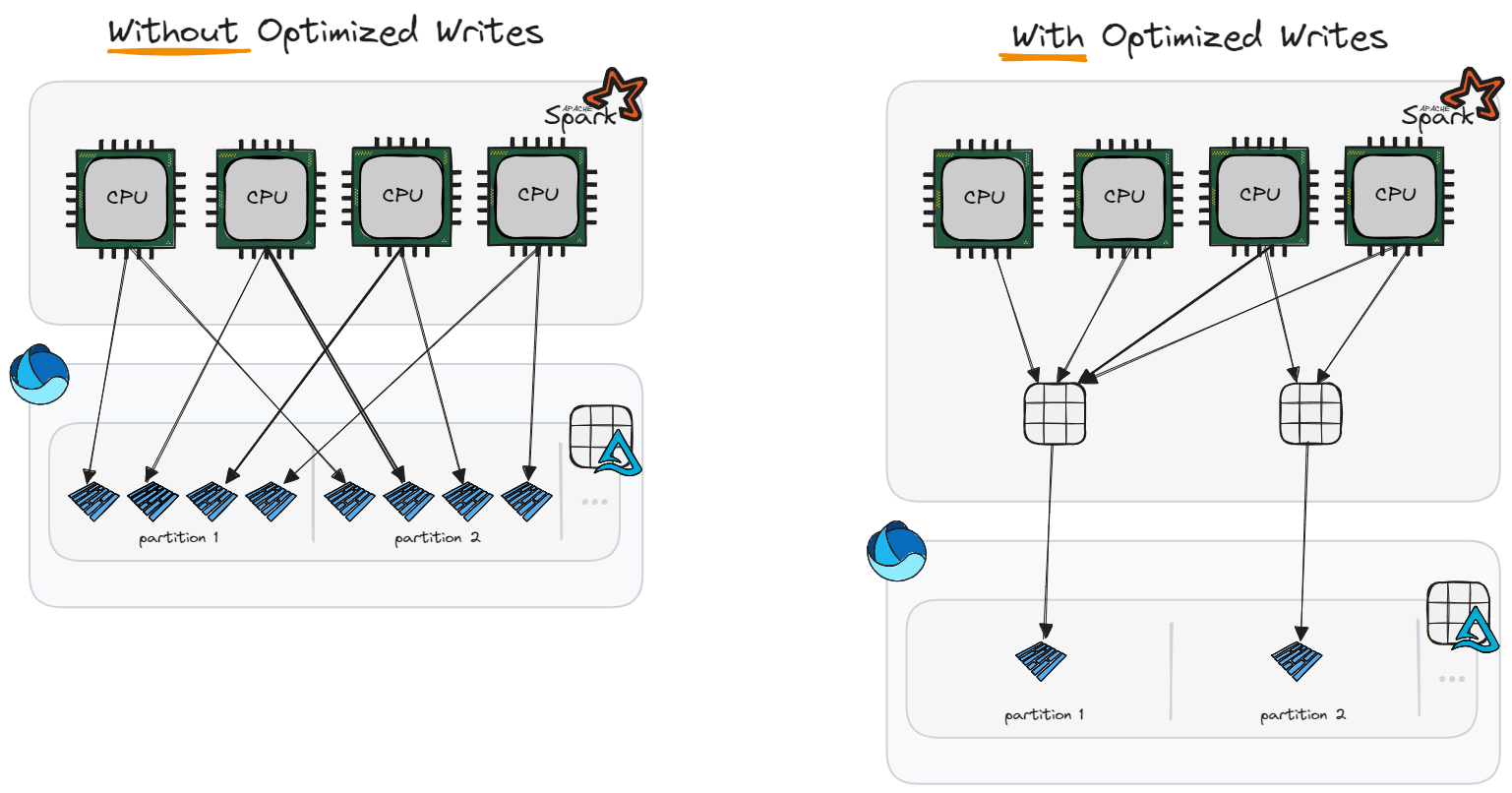
For this small batch size, optimized write results in one file being written each iteration rather than ~16. The small amount of data being shuffle pre-write has an immaterial impact on write performance and more importantly, we can see that the performance from start to finish was extremely consistent.
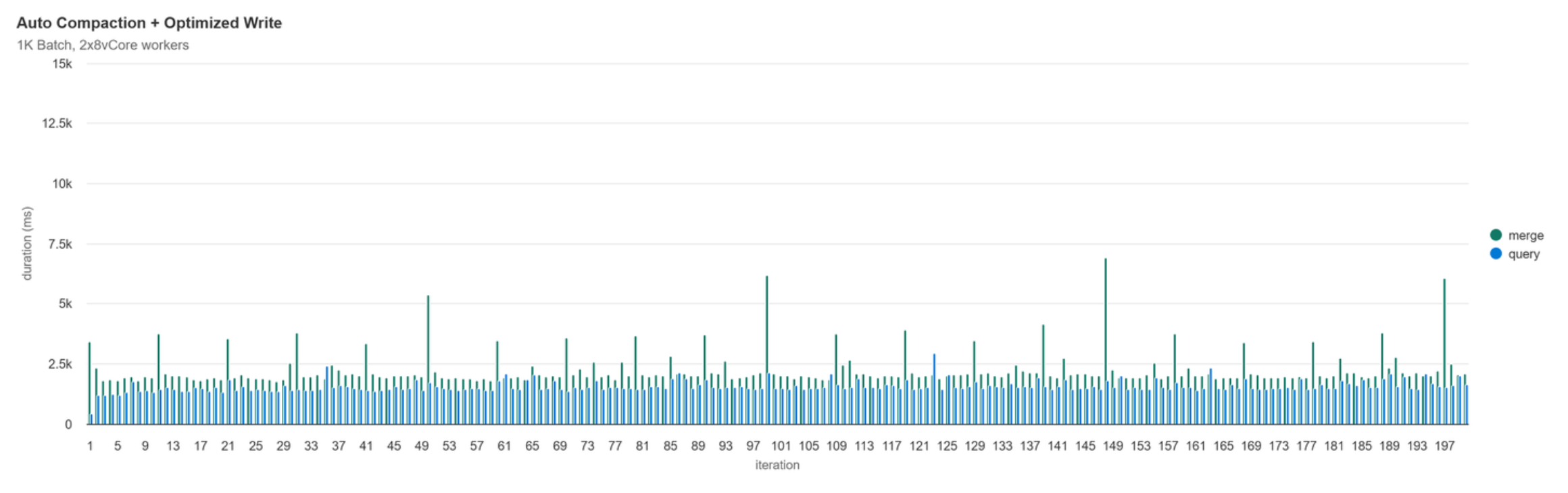
Auto Compaction + Optimized Write
Is Optimized Write a replacement for Auto Compaction or Scheduled Compaction here? No, consider if this process of merging 1K rows into a table were in production for 1 year running once every hour; after 1 year we would have 8,760 files in our table. Over the course of the year the performance of both reading and writing would become signficantly slower. Given that we still need some sort of process to compact files post-write, what if we combined this feature with Auto Compaction?
With both features combined, we have less files written per iteration which translates to less frequent auto compaction being run. As the number of small files exceed 50, auto compaction is run, now we get the best of both worlds :).
File Count Impact
See below for a comparison of only enabling Optimized Write vs enabling the feature with Auto Compaction:
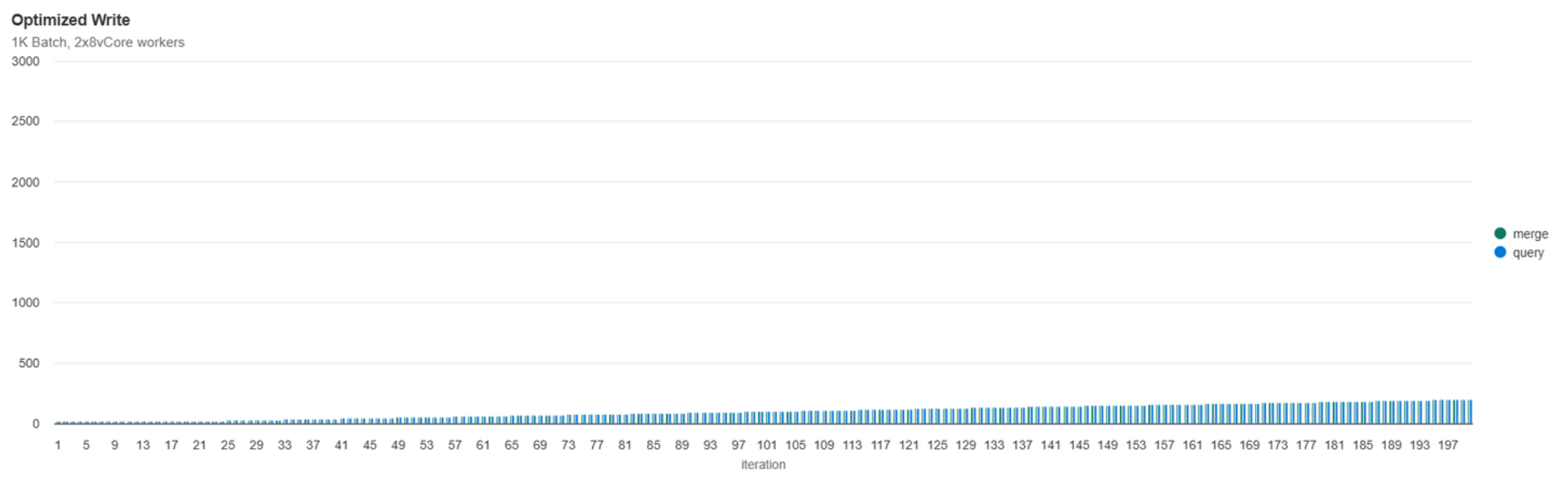
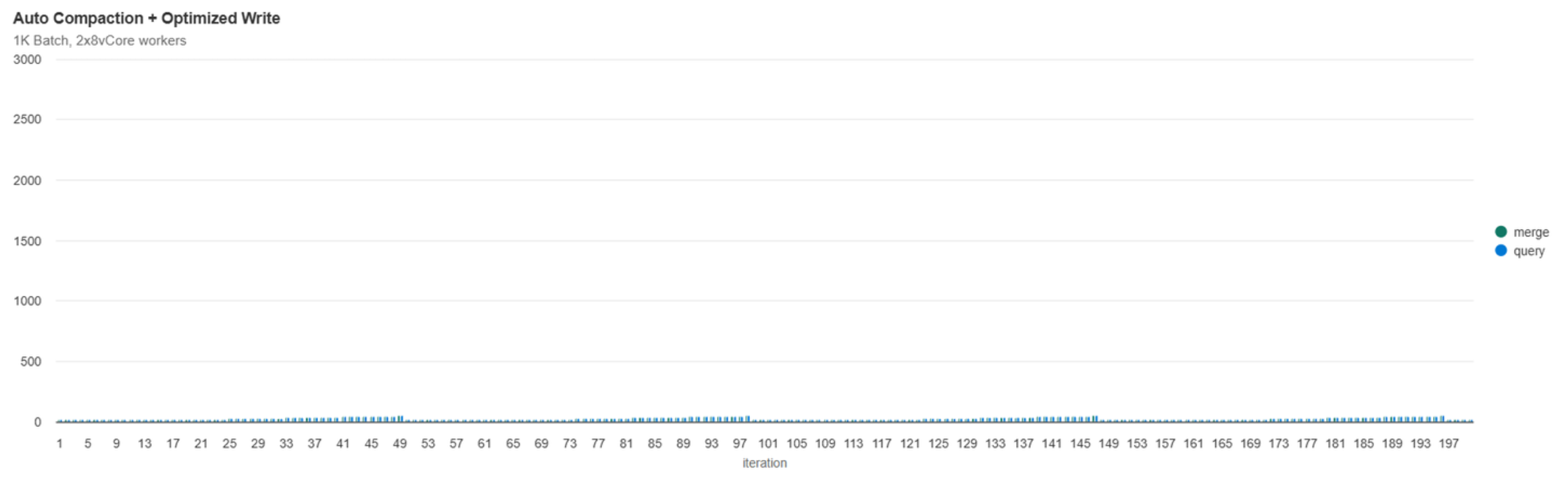
So What Method Won?
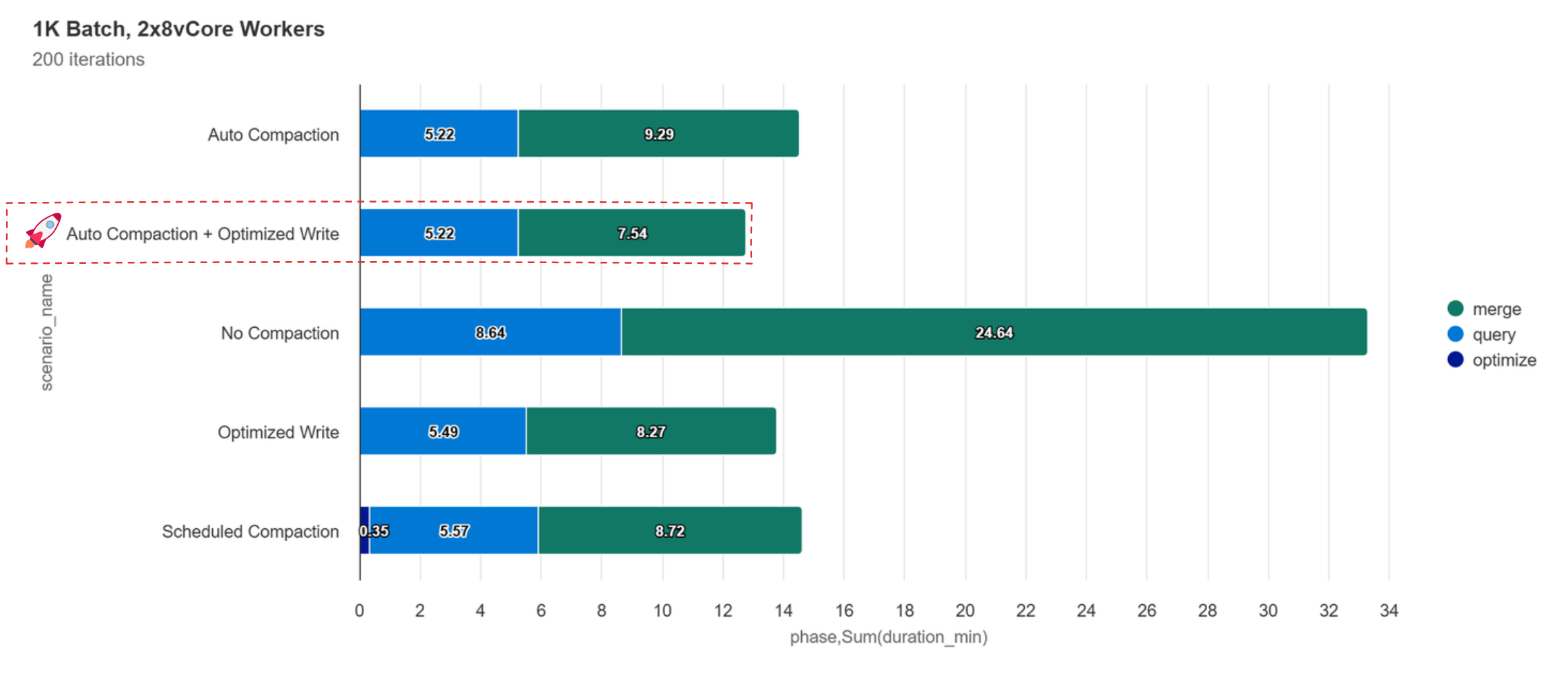
Auto Compaction + Optimized Write had the lowest total runtime, lowest standard deviation of file count, nearly the lowest standard deviation for queries, and the 2nd lowest standard deviation of write duration. By all measures, the combination of avoiding writing small files (where possible) and automatically compacting small files was the winning formula.
| Scenario | Duration (minutes) | Std. Deviation of File Count | Std. Dev. of Merge + Optimize Duration (seconds) | Std. Dev. of Query Duration (seconds) |
|---|---|---|---|---|
| No Compaction | 33.27 | 864 | 2.90 | 0.70 |
| Scheduled Compaction | 14.63 | 89 | 0.61 | 0.35 |
| Auto Compaction | 14.51 | 17 | 1.40 | 0.21 |
| Optimized Write | 13.76 | 58 | 0.62 | 0.27 |
| Auto Compaction + Optimized Write | 12.77 | 14 | 0.74 | 0.24 |
While Scheduled Compaction was almost as fast as Auto Compaction, it’s important to consider the additional cost of coding, scheduling, optimzing the frequency of run, and maintaining the maintenance job. With Auto Compaction on the other hand, just turn it on and you get the same benefit as a perfectly scheduled compaction job, but without any of the overhead and complexity.
What about larger batch sizes?
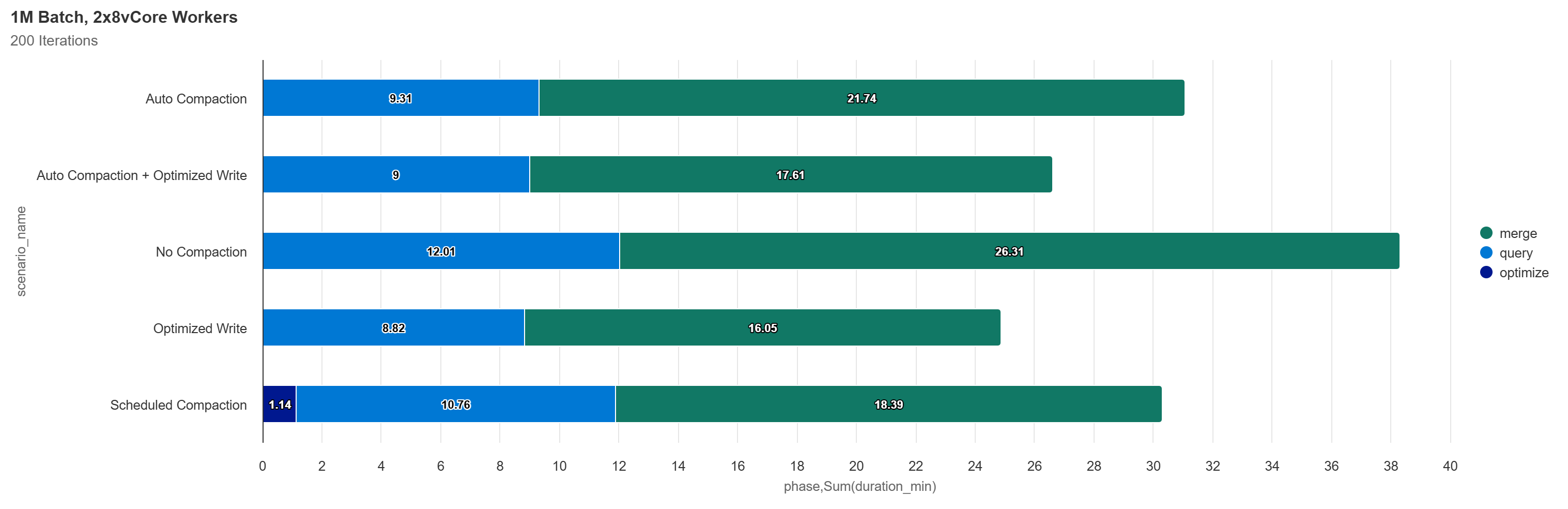
I performed testing at both 100K and 1M row batch sizes. At 100K row batches the results are nearly identical to the 1K row batches. At 1M rows, Auto Compaction appeared to be running too frequently which resulted in much less of a performance benefit.
With auto compaction we now see that as our data volume increases we start to accumulate files that are right sized (> 128Mb). The active file count no longer returns to 1 file every 4 batches, instead it increases linearly and ends with 42 total files. The frequency of mini-compactions that are runs adapts as the data volume changes, based on the count of small files below a max file count threshold (explained later).
Note: the below chart is on a zoomed-in Y-axis scale to better illustrate the bug.
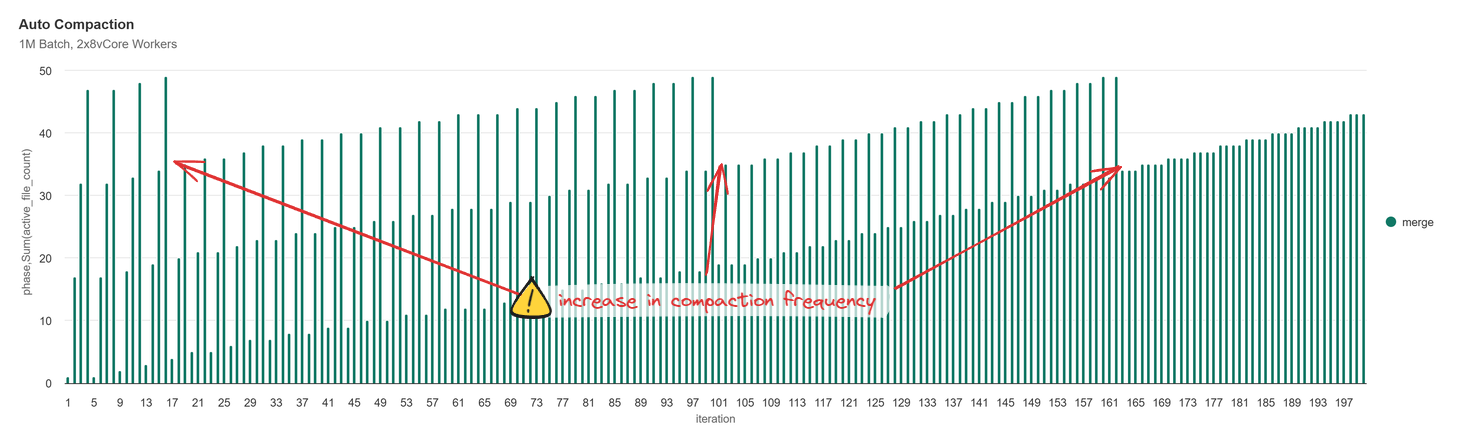
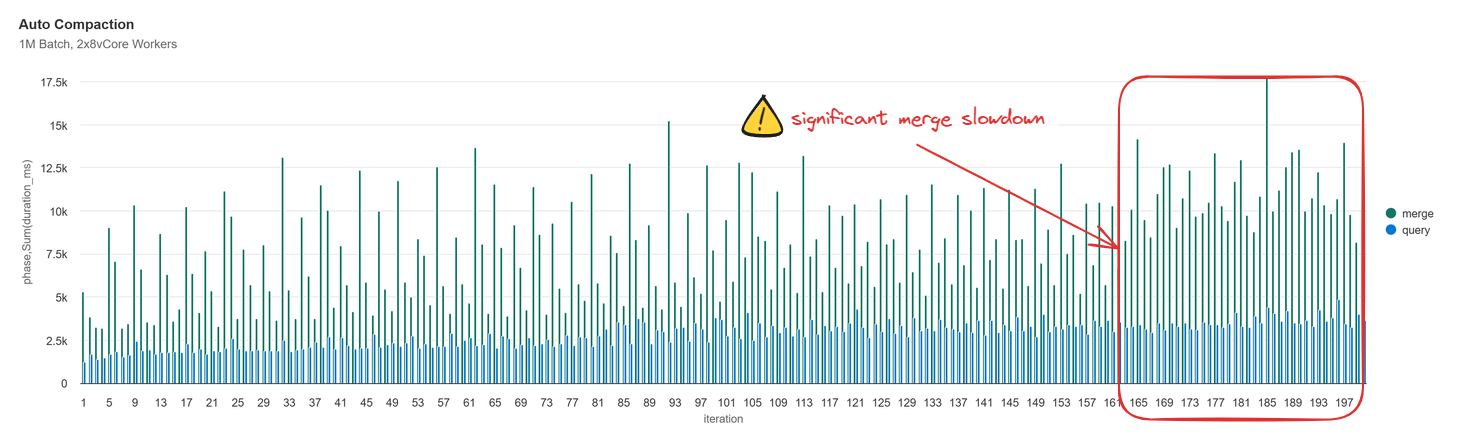 As the iterations and number of compacted files increases, the frequency of compaction increases even give the same number of additive small files each iteration (~16). This is technically not per the documented functionality of the feature and after a interrogating the OSS Delta-Spark source code, I found that there’s a bug where compacted files are also counted towards the minNumFiles threshold. This means that anytime the total number of active files exceeds 50 (or whatever you set minNumFiles to), compaction will be triggered, even if you have less than 50 files that meet the “small file” criteria.
As the iterations and number of compacted files increases, the frequency of compaction increases even give the same number of additive small files each iteration (~16). This is technically not per the documented functionality of the feature and after a interrogating the OSS Delta-Spark source code, I found that there’s a bug where compacted files are also counted towards the minNumFiles threshold. This means that anytime the total number of active files exceeds 50 (or whatever you set minNumFiles to), compaction will be triggered, even if you have less than 50 files that meet the “small file” criteria.
⚠️ Due to [this bug](https://github.com/delta-io/delta/issues/4045) in OSS Delta (and therefore Fabric), for now I would recommend only using auto compaction for tables that are 1GB in size or smaller. Anything larger than this and auto compaction will run too frequently and therefore result in unnessesary write overhead. Until then, I recommend continuing to schedule compaction jobs for tables > 1GB in size. BUT **good news**, I submitted a PR to fix the issue in [OSS Delta](https://github.com/delta-io/delta/pull/4178) and the fix is also soon to be shipping in Fabric Spark.This bug is FIXED in the Fabric Spark Runtime, the OSS Delta fix is still pending.
Below is the behavior that we see with the bugfix in place: as the number of compacted files increases, the frequency of compaction wouldn’t increase, instead you would see that the maximum active file count would slowly increase over time. Once a write operation puts the number of uncompacted files over the minNumFiles threshold (50 files by default), auto compaction is triggered.
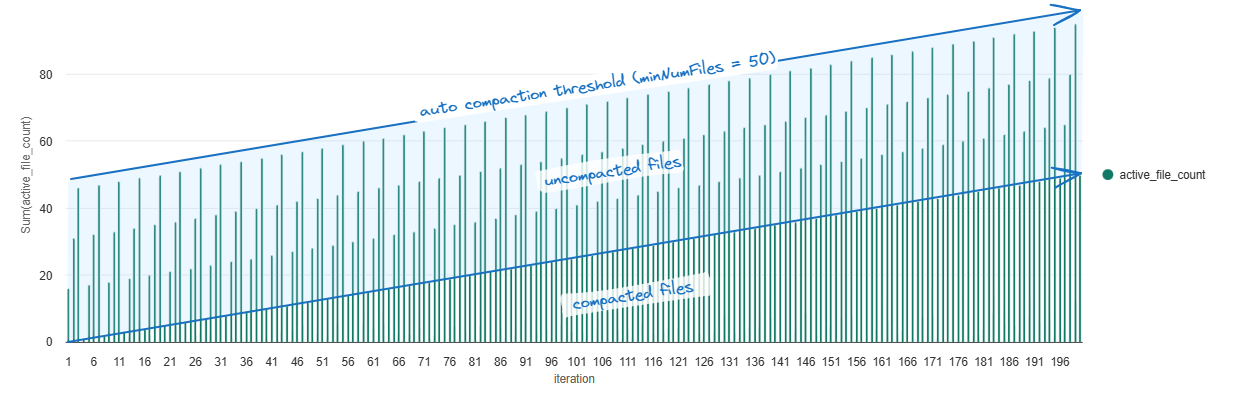
Below are the results with the bugfix in Fabric, again we see that Auto Compaction does wonders to maintain the performance of both writes and reads, even as the amount of data we process scales. Two observations:
- As we scale to merge more data the benefit of avoiding needing to later compact small files is evident, Optimized Write provided the best results with the combination of Auto Compaction + Optimized Write coming close behind.
- At this scale, since each write operation gets us relaively close to our ideal file size (with Optimized Write enabled), Auto Compaction doesn’t yet provide much performance benefit in comparison to Optimized Write alone, however it does act as insurance to prevent the accumulation of too many small files which would surely occur and start to impact performance if this process was run for another few hundred or even a thousand iterations.
- Scheduled Compaction slightly outperformed Automatic Compaction. This is purely a factor of Automatic Compaction evaluating to run at a more frequent interval compared the Scheduled Compaction based on the default configs, the result of which is more consistent and better read performance, but at the cost of slower writes due to more compaction operations being triggered.
How to Enable Auto Compaction
At the session level:
spark.conf.set('spark.databricks.delta.autoCompact.enabled', 'true')
At the table level:
CREATE TABLE dbo.ac_enabled_table
TBLPROPERTIES ('delta.autoOptimize.autoCompact' = 'true')
It can also be enabled on existing tables with:
ALTER TABLE dbo.ac_enabled_table
SET TBLPROPERTIES ('delta.autoOptimize.autoCompact' = 'true')
Tuning Auto Compaction
The behavior of auto compaction can be adjusted via changing the two properties:
| Property | Description | Default Value | Session Config | Table Property |
|---|---|---|---|---|
| maxFileSize | The target maximum file size in bytes for compacted files. | 134217728b (128Mb) | spark.databricks.delta.autoCompact.maxFileSize | Not available |
| minFileSize | The minimum file size in bytes for a file to be considered compacted. Anything below this threshold will be considered for compaction and counted towards the minNumFiles threshold. |
Unset by default, it is calculated as 1/2 of the maxFileSize unless you explicitly set a value. |
spark.databricks.delta.autoCompact.minFileSize | Not available |
| minNumFiles | The minimum number that must exist under the max file size threshold for a mini-compaction operation to be triggered. | 50 | spark.databricks.delta.autoCompact.minNumFiles | Not available |
Here are the use cases for when I would tweak these properties:
- minNumFiles: assuming you can tollerate higher standard deviation in query execution times, make this value larger if I want auto compaction to be triggered less frequently.
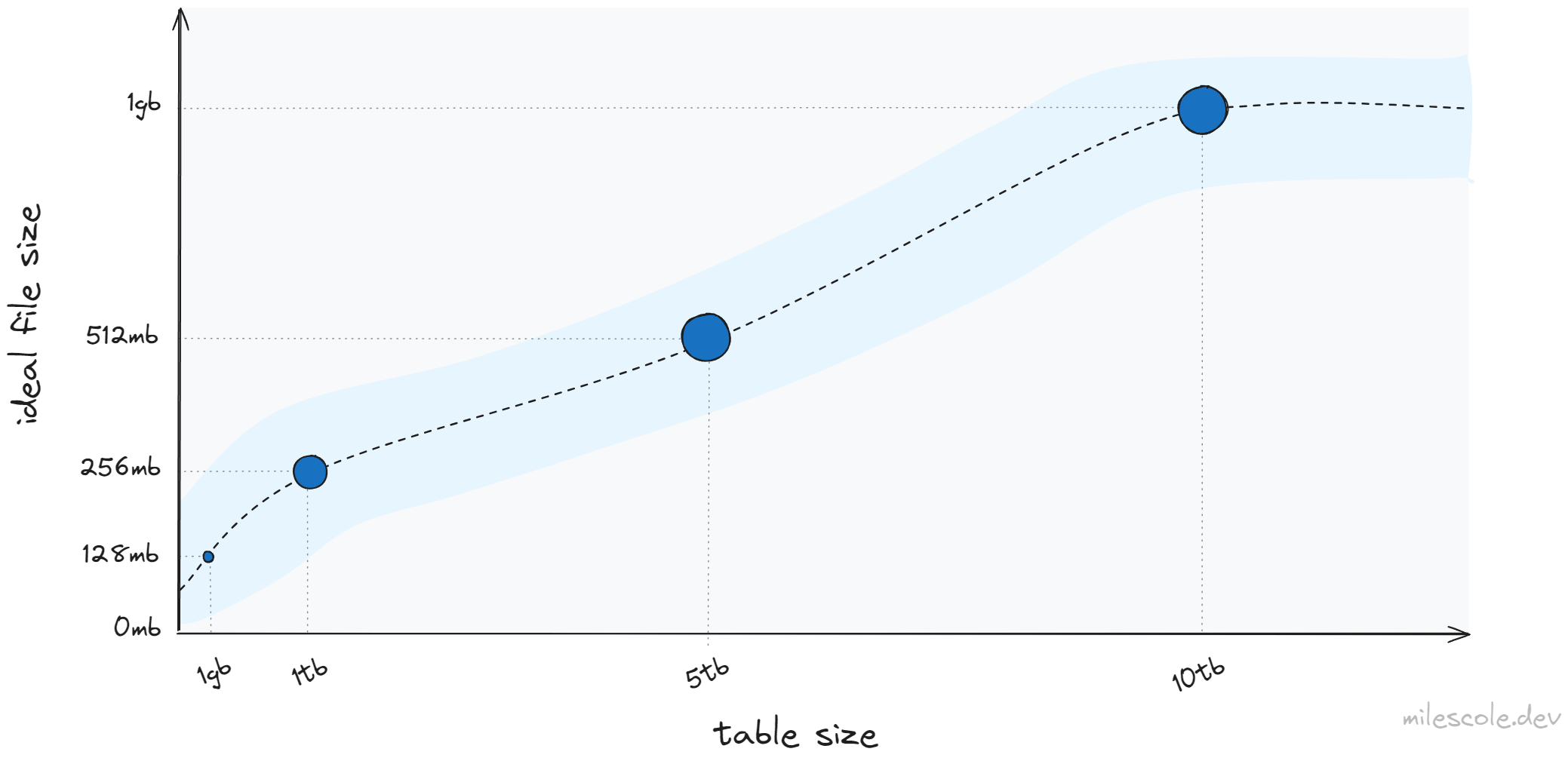
- maxFileSize: adjust this value to align with the ideal file size for your tables. In the below chart you can see the relationship between the size of a table and the ideal size of each file. This helps to minimize I/O cycles to read data into memory as well as optimizes file skipping opportunities (too few files means suboptimal file skipping).
Key Takeaways
- Auto compaction removes complexity: the “how often should I run
OPTIMIZE” question was completely eliminated. In my benchmark, after having analyzed the results, I realized that I ran the scheduled compaction too often. While runningOPTIMIZEevery 20 iterations was beneficial for the 1K row batch size, as my data volumes increased, less small files were written and a full compaction being run that often was somewhat inefficient. Also, I could’ve better designed the process to only compact files added since the last compaction operation was run. - Scheduled or Ad-Hoc Compaction Might Still Be Necessary: While auto compaction seems to win at all data volumes that I tested, would this continue after 1,000 or even 10,000 iterations? While a 128Mb file size target for auto compaction seems to work well, at some point you may need to compact these into 500Mb or even up to 1Gb files. While I would typically rely on auto compaction for short-term maintenance, in the long term you may need to selectively run an ad-hoc
OPTIMIZEoperation since the two different methods have different maxFileSize thresholds.
Closing Thoughts
Given the results of the three options that I tested, I would enable auto compaction in almost all use cases. It’s just too easy to enable and produces consistent results at various workload sizes. Sure, you might be able to schedule an incremental compaction job based on workload metadata that might match auto compaction results, but why overcomplicate things? It’s one (or more) less job to support, tune, and execute. With additional settings to control thresholds which impact the frequency of run and file size considered, for many workloads, it’s a no-brainer.
I was just recently in the scenario where I had a scheduled process that would frequently insert a smallish number of rows into a table (similar to my 1K row test) and noticed considerable slowness when querying the log table where queries would take 30+ seconds to return. Rather than scheduling a maintenance job or ad-hoc running OPTIMIZE for agile dev/test work I was doing, I just enabled auto compaction on the table. The next run of the process cleaned up the small files and I was back to 1-2 second latency when querying the table to analyze results.
Bonus Bits!
I’ve presented on this topic a few times and received some interesting questions that I’ll share answers to below:
- How can I tell what files are part of the active Delta version being queried?: you can use the
inputFiles()DataFrame method to evaluate the parquet files that would be read to return the query result.spark.sql("SELECT * FROM dbo.table").inputFiles() - How can I tell when Auto Compaction is actually run?: use the below PySpark. Auto Compaction operations show up as regular
OPTIMIZEjobs in the transaction log but have an additional auto flag which is logged in operationParameters.history_df = spark.sql("DESCRIBE HISTORY dbo.table_with_ac_enabled") filtered_history = history_df \ .filter(history_df.operation == "OPTIMIZE") \ .filter(history_df.operationParameters.auto == "true") display(filtered_history) - How can I estimate the appropriate target file size for my Delta tables?: You can use
DESCRIBE DETAILto get the size of the latest version of your Delta table in bytes and then use this number to estimate the ideal target file size based on my prior referenced sizing chart.spark.sql("DESCRIBE DETAIL dbo.table_with_ac_enabled")