Spark is fantastic for distributed computing, but can it help with tasks that are not distributed in nature? Reading from a Delta table or similar is simple—Spark’s APIs natively parallelize these types of tasks. But what about user-defined tasks that aren’t inherently distributed?
In this post, I’ll show how you can take advantage of the distributed nature of Spark for tasks that aren’t natively handled by Spark.
Parallelizing Any Operation
Imagine you have a Python operation that takes too long to run simply because it’s executed serially across a large volume of tasks. A common example is making API calls. For instance, maybe you’re starting with a large array of IDs, and you need to make an API call for each ID, collect the responses, and save them in a Delta table. Or, maybe you need to make a bunch of POST API calls to update a service and while parallelism may be needed, writing any outcome to Delta is not.
Before we dig into different ways to distribute such a task, let’s frame up the example use case: cats! Honestly, I’m not a fan of cats, however my children love them and coincidentally there’s a pretty neat API service called TheCatAPI. Yes, an API for cats—well, not for cats, since cats can’t code—but the API returns information about cats. Fun!
My goal is to see how quickly I can make 1,000 API calls to TheCatAPI, then parse and save the JSON responses with completely useless information about cats to OneLake for further cat analysis.
Note: The free tier of TheCatAPI supports only 120 requests per minute, and since I quickly exceeded this limit and got throttled, I introduced a sleep function to simulate the approximate API call duration of 350 milliseconds. While TheCatAPI supports bulk operations, not all APIs do, so this serves as an example of how to interact with APIs that don’t support bulk requests.
Why Parallelize Non-Distributed Tasks?
Starting with the serial approach, running 1,000 API calls to TheCatAPI takes about 5.5 minutes, averaging around 330 milliseconds per call. As we scale the solution, the time grows linearly: 2,000 API calls would take roughly 12 minutes, 4,000 API calls would take about 24 minutes.
The base function (yes, you can run this yourself, just request a free API key from TheCatAPI):
import requests
import json
import time
api_key = 'xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx'
generate_n_rows = 1000
def get_cat_json(_):
start_time = time.time()
try:
response = requests.get(f"https://api.thecatapi.com/v1/images/search?limit=1&has_breeds=true&api_key={api_key}")
cat_json = json.loads(response.content)[0]
# Extract fields from the API response
breeds = cat_json.get("breeds", [])
return (breeds, cat_json.get("id", None), cat_json.get("url", None),
cat_json.get("width", None), cat_json.get("height", None))
except Exception as e:
# If the total time is less than 350 ms, sleep for the remaining time to mimic the duration of a successful API call
elapsed_time = time.time() - start_time
if elapsed_time < 0.350:
time.sleep(0.350 - elapsed_time)
return (None, None, None, None, None)
Here’s the code for serially executing the 1,000 API calls, creating a Spark DataFrame from the result, and then simulating writing the output.
results = []
for i in range(generate_n_rows):
data = get_cat_json(i)
results.append(data)
df_with_api_response = spark.createDataFrame(results)
df_with_api_response.write.mode("overwrite").format("noop").save()
The write format noop in Spark,
format("noop"), is used with the DataFrameWriter when you don’t actually want to write any data to an output sink but still want to trigger the computation. The “noop” format stands for “no operation,” and it essentially acts as a placeholder that does nothing but allows Spark to go through the motions of executing the job, triggering all the necessary actions (like parallelizing, transformations, etc.) without actually writing the data anywhere. This can be useful for benchmarking or testing performance without the overhead of writing data to storage, allowing you to focus solely on execution time or resource utilization.
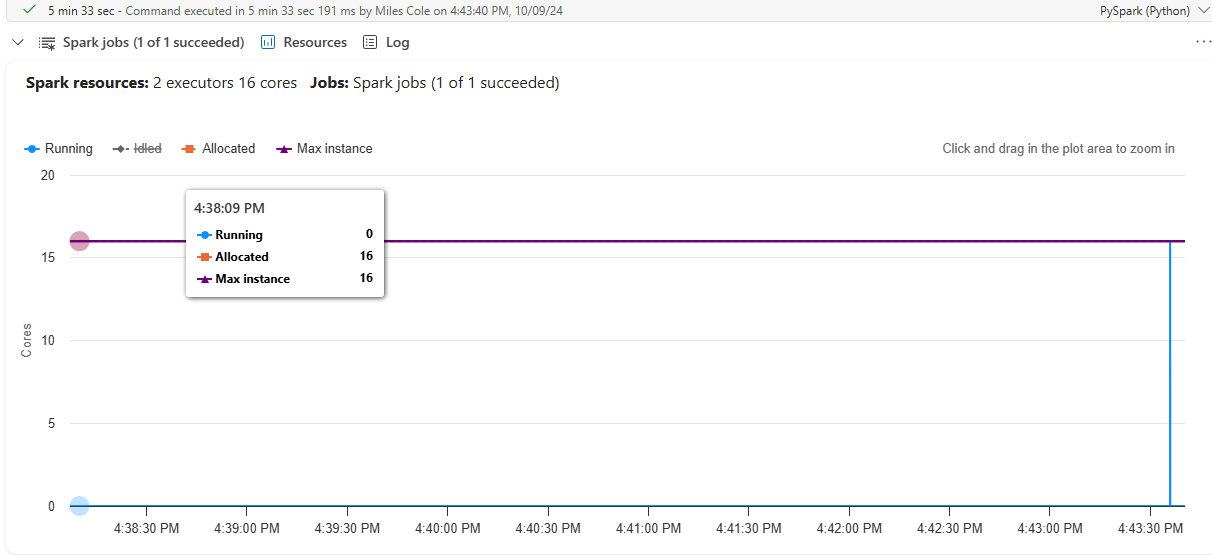
Since everything up to creating the Spark DataFrame is just Python, it is exclusively executed on the driver. While we are running this on a Spark cluster with 2 executors, all of the processing takes place on the driver node. We can see that 0 executor cores are being leveraged on the Resources tab of the Notebook cell up until the point that the Spark DataFrame is created:
To distribute and parallelize an operation in Spark, like an API call, there’s two funcamental starting points that we can choose from: RDDs and DataFrames. For a recap of the differences between the two, see my most recent post on RDDs vs. DataFrames. In comparison to DataFrames, RDDs would allow us to parallelize work that doesn’t have a DataFrame as a starting point or end result.
Parallelize (RDD)
Parallelize takes two arguments, a collection to distribute and operate on, and the number of partitions or slices that the data should be split into. If the second argument is blank it will typically default to the number of executor cores allocated to the cluster.
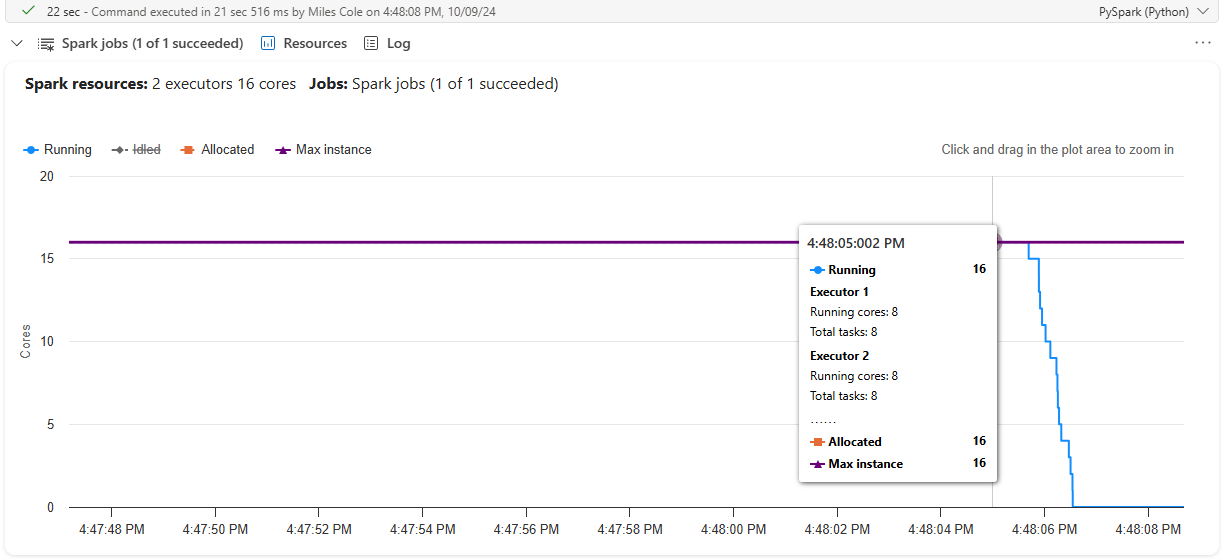
By parallelizing the task, we can reduce the execution time to 22 seconds. Although each API call still took ~350 milliseconds, distributing the work across 16 cores sped up the process roughly 16x. When looking to further optimize a workload like this, there’s a near-linear relationship between total cores, parallelism, and the total processing time.
# Generate an RDD from a collection of
results_rdd = spark.sparkContext.parallelize(range(generate_n_rows)).map(get_cat_json)
# Convert the RDD to a DataFrame using the schema
df_with_api_response = spark.createDataFrame(results_rdd)
# Trigger evaluation by writing the DataFrame
df_with_api_response.write.mode("overwrite").format("noop").save()
Looking at the Resources tab of the Notebook cell we now see that all 16 cores across the 2 executors were leveraged:
Spark UDF (DataFrame)
Processing the API calls as a scalar Spark UDF also took 22 seconds. This is not surprising, as this approach functionally performs the same operation as parallelize(), albeit with a more intuitive syntax.
from pyspark.sql.functions import udf
# Register the UDF with Spark
get_cat_json_udf = udf(get_cat_json, cat_api_schema)
# Apply the UDF to a DataFrame with N rows
df = spark.range(generate_n_rows)
df_with_api_response = df.withColumn("response", get_cat_json_udf(df["id"]))
df_with_api_response.write.mode("overwrite").format("noop").save()
When to Use Parallelize vs. Spark UDFs?
Use parallelize() when you need more control over how tasks are distributed across your Spark cluster, especially when working with RDDs directly. Spark UDFs are generally easier to implement for column-based transformations on DataFrames, but both approaches can parallelize tasks similarly when working with scalar or vectorized operations. See RDDs vs. DataFrames for more details.
Can Multithreading Beat Spark?
Multithreading is a powerful tool for concurrency, and I’ve written about it in the past (here and here), but can it outperform Spark for this use case?
Using the same get_cat_json() function, I mapped it across a thread pool with 16 threads, matching the number of cores in my Spark cluster. This process took 46 seconds, which is about 2x slower than Spark but still 7x faster than the serial method. While slower than the Spark parallelization approaches, this method could run on a single-node Spark cluster, using only 1/3 the compute resources compared to my other tests which ran on a cluster with 2 8vCore executors. So while Multithreading doesn’t win on speed here, it’s a strong contender if optimizing for job cost.
from concurrent.futures import ThreadPoolExecutor, as_completed
results = []
with ThreadPoolExecutor(max_workers=16) as executor:
# Submit all tasks to the thread pool
futures = {executor.submit(get_cat_json, i): i for i in range(generate_n_rows)}
# Collect the results as they complete
for future in as_completed(futures):
result = future.result()
results.append(result)
df_with_api = spark.createDataFrame(results)
df_with_api.write.mode("overwrite").format("noop").save()
xychart-beta
title "Time to Execute 1,000 Cat API Calls"
x-axis ["Serial", "Parallelize", "Spark UDF", "Thread Pool"]
y-axis "Minutes" 0 --> 6
bar [5.5, 0.36, 0.36, 0.76]
💡 Why was Spark faster than Multithreading? Spark truly parallelized the operation across multiple cores and executors. In contrast, multithreading primarily introduced concurrency, meaning the threads were taking turns executing on the same resources. This limits the performance compared to Spark’s distributed execution model which allows for true parallelization of work on individual cores.
How to Handle Throttling in Real-World Use Cases
Stay tuned. My next blog is on the topic of PySpark process resiliency.
Closing Thoughts
Spark allowed us to parallelize a non-distributed task, achieving results 16x faster than the serial approach. If we wanted to go faster, we could simply add more executors or increase our executor node size. For tasks like API calls that can’t natively leverage Spark’s distributed data processing, using parallelize or Spark UDFs provides an easy path to acceleration. If you’re constrained on compute or cost, multithreading offers a reasonable alternative, but Spark remains the go-to for scalable performance in a distributed environment.