There’s been a lot of excitement lately about single-machine compute engines like DuckDB and Polars. With the recent release of pure Python Notebooks in Microsoft Fabric, the excitement about these lightweight native engines has risen to a new high. Out with Spark and in with the new and cool animal-themed engines— is it time to finally migrate your small and medium workloads off of Spark?
Before writing this blog post, honestly, I couldn’t have answered with anything besides a gut feeling largely based on having a confirmation bias towards Spark. With recent folks in the community posting their own benchmarks highlighting the power of these lightweight engines, I felt it was finally time to pull up my sleeves and explore whether or not I should abandon everything I know and become a DuckDB and/or Polars convert.
The Methodology
While performance can be the most important driver in selecting an engine, the reality is that performance alone does not make a technology worthy of a spot in your architecture landscape. In this analysis, I’ve chosen to build a benchmark suite that aims to evaluate the following based on real-world-type test cases:
- Performance
- Execution Cost
- Development Cost
- Engine Maturity and Compatibility
The Test Cases
If I can find any complaint with benchmarks that people post, it’s that they don’t always reflect real-world use cases. The recent blog by my colleague Sandeep Pawar is fantastic, as it highlights how optimizing row group sizes can allow single-machine engines to approach V-Order-like performance. In terms of the Spark comparison, as I shared with Sandeep, the use of the LIMIT operator in his benchmark resulted in Spark running a CollectLimit operation, which forces all data on worker nodes to be collected and then filtered at the driver level. This resulted in unnecessary data movement from workers to the driver as well as a single-threaded write operation, which constrained the possible parallelism and performance. While using LIMIT to interactively return a small result set to the console is a real-world use case, returning 50M rows to the console OR using the LIMIT operation in typical ELT processes (i.e., building a fact table) is not. Therefore, it doesn’t make sense to draw serious conclusions about Spark based on this test.
For my test cases, I aimed to comprehensively cover the basic ELT use cases in a Lakehouse architecture, evaluated at both the 10GB and 100GB levels based on a sampling of TPC-DS tables generated via the Databricks DS-DGEN-based library (the largest was the store_sales table):
-
Read Parquet, Write Delta (5x): I’ve selected five tables from the TPC-DS schema. This test simply measures the time to read the source Parquet data and write a Delta table for each of the five tables.
-
Create Fact Table: This test measures the time to create a fact table based on the aggregation of data from the five source TPC-DS tables. A simple
CREATE TABLE AS SELECToperation is run. -
Merge 0.1% into Fact Table (3x): This test measures the time to take a 0.1% sampling of records from the core transaction source table, join them with dimension tables, randomize values, and then merge them into the target fact table created in the prior step. This is run three times to simulate having multiple incremental loads.
-
VACUUM (0 Hours): This measures the time to clean up old Parquet files that are no longer in the latest Delta commit. I ran with 0 hours of history retained (not recommended for production workloads) so that it would clean up the maximum number of files.
-
OPTIMIZE: Nothing fancy about this, just the time to perform compaction.
-
Ad-hoc Query (Small Result Aggregation): The time to perform a simple aggregated
SELECTstatement that returns a small result set. This imitates the type of ad-hoc query that would be run interactively and displayed for analysis.
Based on my experience consulting where I built many Lakehouse architectures, these are the types of operations that would be generally representative of end-to-end data engineering work. No APIs or semi-structured data to make things too complex—just the typical operations that would result if you had Parquet files being delivered as a starting place and the goal was to build a dimensional model to support reporting and ad-hoc queries.
Compute Configurations
I elected to use the smallest possible compute size for each respective engine for both the 10GB and 100GB benchmarks. For DuckDB and Polars, using Python Notebooks, this was the default 2-vCore VM size. For Spark, the smallest possible compute size is a Single-Node 4-vCore Spark cluster (one single Small node VM). While the starting node size for Spark is 2x bigger, Fabric Single-Node clusters allocate 50% of cores to the driver, meaning the Spark job effectively only has 2 vCores available for typical Spark tasks.
- The 10GB benchmark was run on 2, 4, and 8-vCore machines (all single-node configurations for Spark and single-VMs running Python for DuckDB and Polars).
- The 100GB benchmark was run on 2, 4, 8, 16, and 32-vCore compute configurations:
- For Spark, I used single-node configurations for 4 and 8-vCores.
- For 16-vCores, I used a cluster with three 4-vCore worker nodes (4 driver vCores + 12 worker vCores).
- For 32-vCores, I used a cluster with three 8-vCore worker nodes (8 driver vCores + 24 worker vCores).
- For DuckDB and Polars, single-VMs running Python were used.
For Spark, I used the Native Execution Engine (NEE), as this is a native C++ vectorized engine that makes vanilla Spark faster. There’s no additional CU rate multiplier, so there’s no reason not to use it, particularly when trying to optimize for both cost and performance.
Engine Versions
| Engine | Version |
|---|---|
| Spark | Fabric Runtime 1.3 (Spark 3.5, Delta 3.2) |
| DuckDB | 1.1.3 |
| Polars | 1.6.0 |
Delta Lake Writer Configs
I used the best practice Delta Lake writer configs available in each engine.
- For the Spark tests, I enabled deletion vectors. See my blog on this topic to understand the value proposition.
- For both DuckDB and Polars, since they depend on the Rust-based DeltaLake Python library for writes, which does not support deletion vectors, this setting could not be enabled. However, at this small scale, deletion vectors would only have a marginal impact on performance, so this does not skew the results in any meaningful way.
The Native Execution Engine (NEE) doesn’t yet natively support deletion vectors. When DVs are included, it results in mixed execution query plans with fallback to Spark row-based execution. Depending on the workload, DVs can still improve performance where merge-on-read results in less data being written. In this benchmark, DVs resulted in NEE completing ~3% faster.
Polars Benchmark Sampling Mod
After running the benchmark with Polars and getting OOM errors below 16-vCores, I identified that Polars does not support lazy evaluation for data sampling. This meant that to run the Merge 0.1% into Fact Table (3x) test, Polars needed to read the entire source Delta table into memory and then take an in-memory sampling of data. Spark and DuckDB, on the other hand, are able to sample directly on top of the source data, eliminating the need to load the entire table into memory.
Since sampling a large table as the source for an incremental load is not something you’d typically see in production and was only used for data generation purposes, I decided to run a second version of the benchmark for Polars. This version, labeled as Polars (Mod), uses DuckDB to perform the more efficient sampling operation (sampled_table = duckdb.sql("SELECT * FROM delta_scan('abfss://...') USING SAMPLE 0.1%").record_batch()) before processing the data further with Polars.
Benchmark Analysis
ℹ️ After reading this blog, see my refresh of this benchmark updated on 6/30/2025 which covers new insights, includes Daft in the mix, and an intro to LakeBench, the benchmark behind this blog post.
Performance
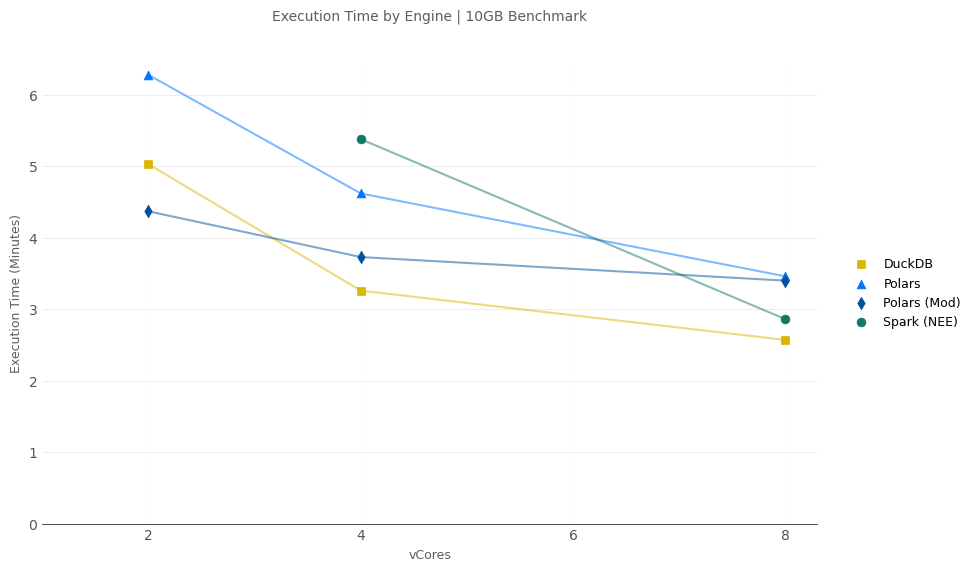
10GB Scale
- At 2-vCores, Polars (Mod) was the fastest engine, followed by DuckDB, and then Polars without the benchmark modification.
- At 4-vCores, DuckDB takes the win followed by Polars and lastly Spark. DuckDB was ~1.6x faster than Spark w/ NEE.
- At 8-vCores, DuckDB finishes only slightly faster than Spark w/ NEE. Both Polars scenarios come last.
100GB Scale
- No engine completed the benchmark with only 2-vCores (Fabric doesn’t offer a 2-vCore node size for Spark so this wasn’t tested).
- DuckDB was the fastest engine when using 4-vCores, taking a slight edge over Spark w/ NEE.
- Spark w/ NEE was fastest at 8, 16, and 32-vCores.
- Polars ran into out-of-memory (OOM) and wasn’t able to finish tests at 4 or 8 vCores. Polars was much slower than DuckDB and Spark at 16 and 32-vCores.
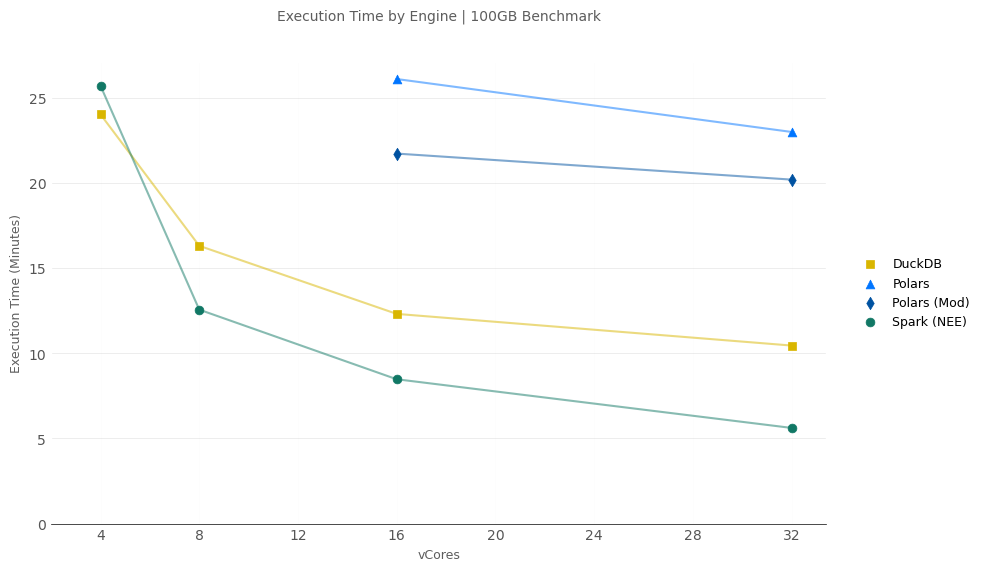
Note: In all of these tests, Spark has access to fewer total vCores for data processing work yet was able to keep up and even exceed the others.
Which Phases Did Different Engines Excel At?
- Read Parquet, Write Delta (5x)
- 10GB: While Polars took the win at 2-vCores, DuckDB had an edge at 4-vCores.
- 100GB: Spark was over 2x faster than both DuckDB and Polars.
- Create Fact Table
- 10GB: DuckDB was ~2x faster than every other engine, with the other engines performing very similarly.
- 100GB: DuckDB and Spark w/ NEE tied, with both Polars variants running almost 6x longer.
- Merge 0.1% into Fact Table (3x)
- 10GB: Polars (Mod) was the fastest at 4-vCores, with the other engines closely clustered.
- 100GB: Spark w/ NEE was ~2x faster than DuckDB and significantly faster than both Polars variants.
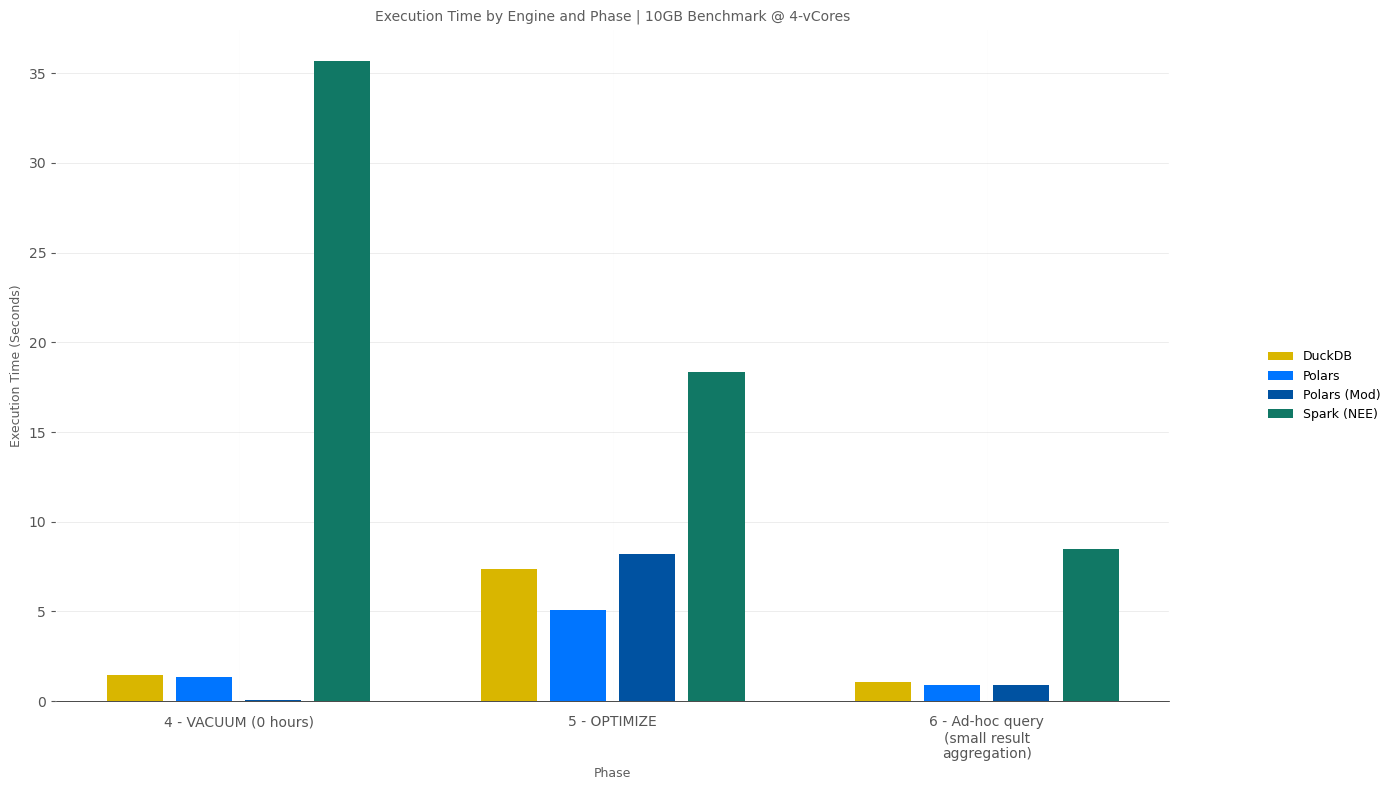
- VACUUM (0 Hours)
- Neither DuckDB nor Polars have a native
VACUUMcommand; however, the DeltaLake Python library based on Delta-rs was significantly faster than the nativeVACUUMcommand in Spark.
- Neither DuckDB nor Polars have a native
- OPTIMIZE
- Same as
VACUUM, neither DuckDB nor Polars have a nativeOPTIMIZEcommand, but the Delta-rs-based library again was significantly faster than the nativeOPTIMIZEcommand in Spark.
- Same as
- Ad-hoc Query (Small Result Aggregation)
- As expected, this is where engines like DuckDB and Polars provide mind-blowing, super-low-latency performance. Depending on the scale, DuckDB and Polars were between 2-6x faster than Spark w/ NEE.
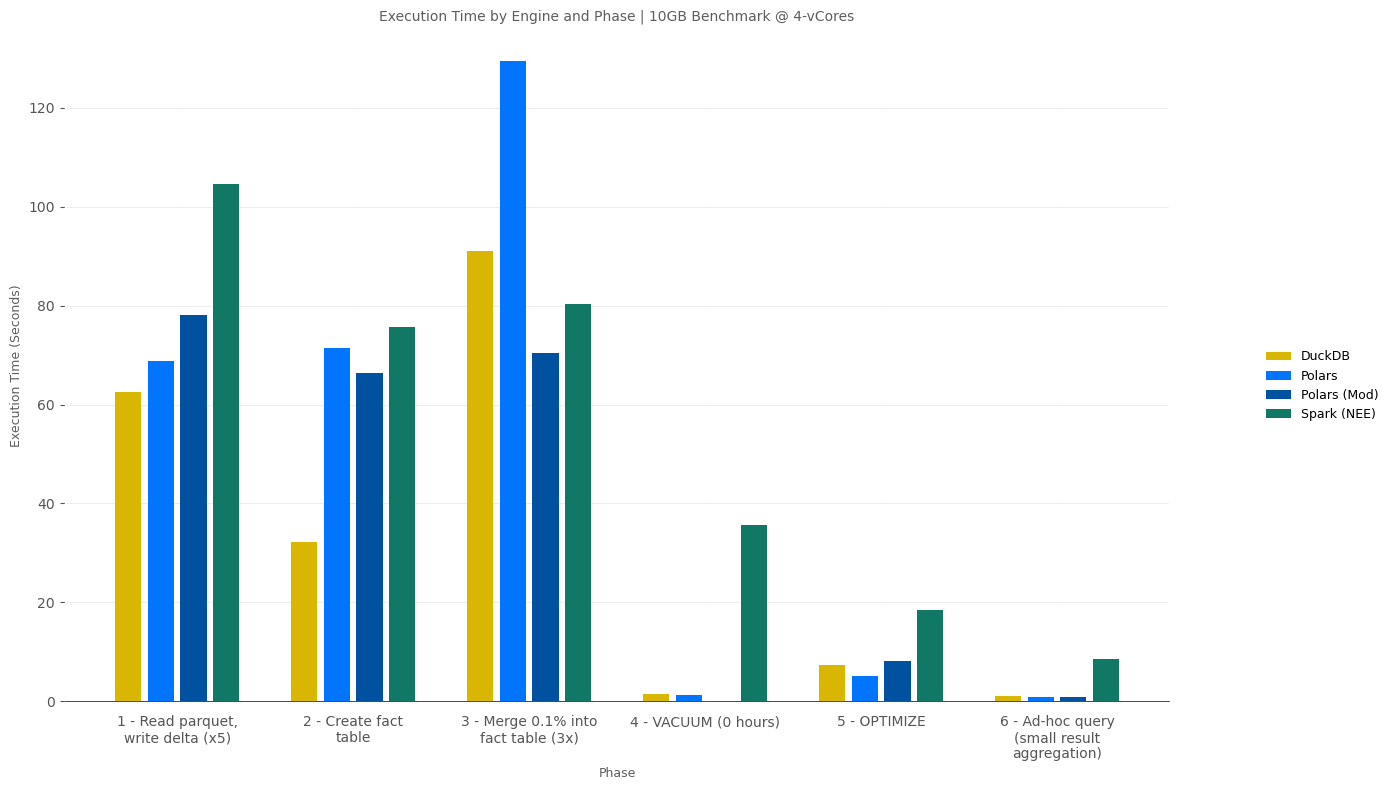
10GB Results @ 4-vCores
100GB Results @ 16-vCores
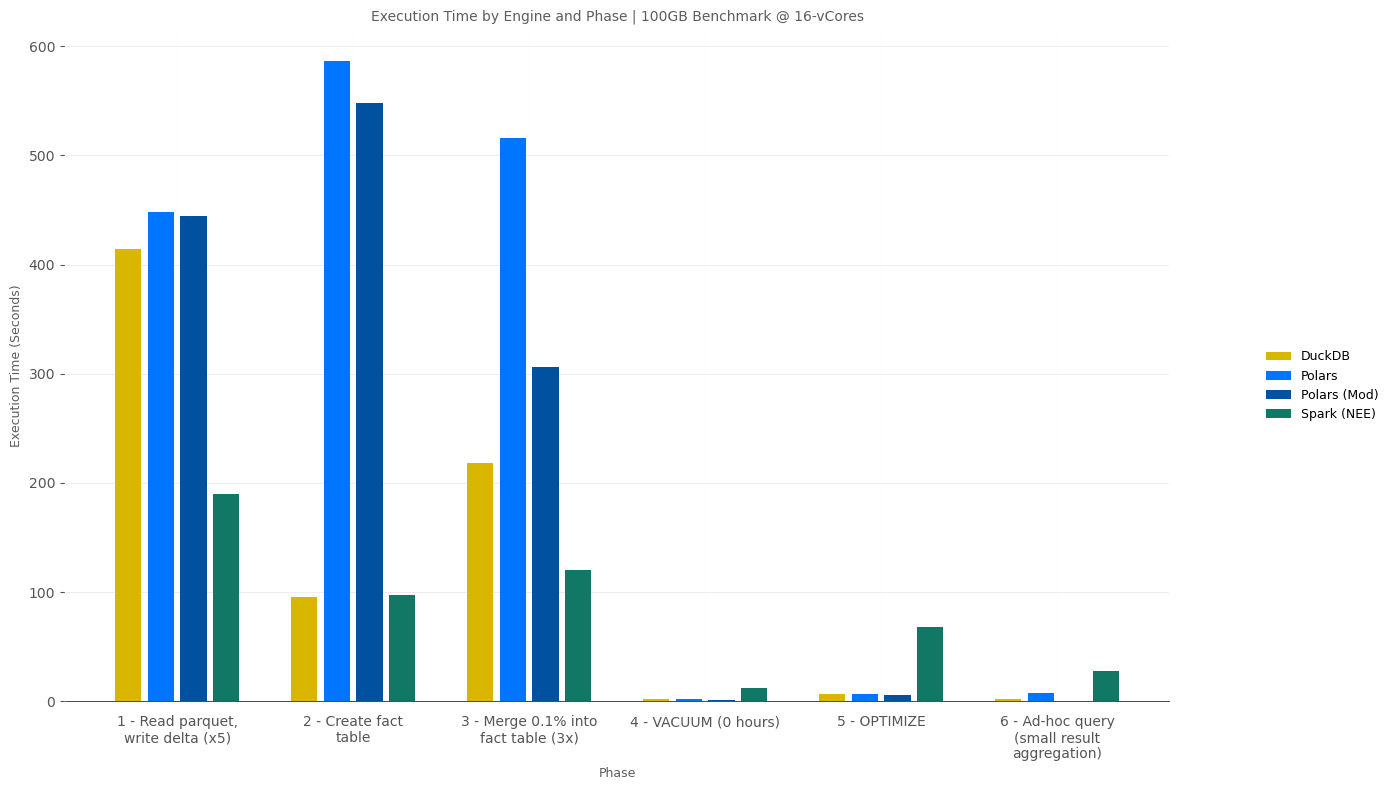
Since the performance difference for VACUUM, OPTIMIZE, and Ad-hoc/Interactive Queries tends to be overshadowed by longer-running ELT processes, here’s an isolated view of the 10GB 4-vCore benchmark highlighting how much faster DuckDB and Polars (with Delta-rs) are for these workloads.
Execution Cost
Since I logged the vCores used for each run, translating to CU seconds and then the approximate dollar cost for the job was straightforward. Now that I’ve established that vanilla Spark can compete, going forward I will highlight results comparing Spark w/ NEE and deletion vectors enabled compared to DuckDB and Polars.
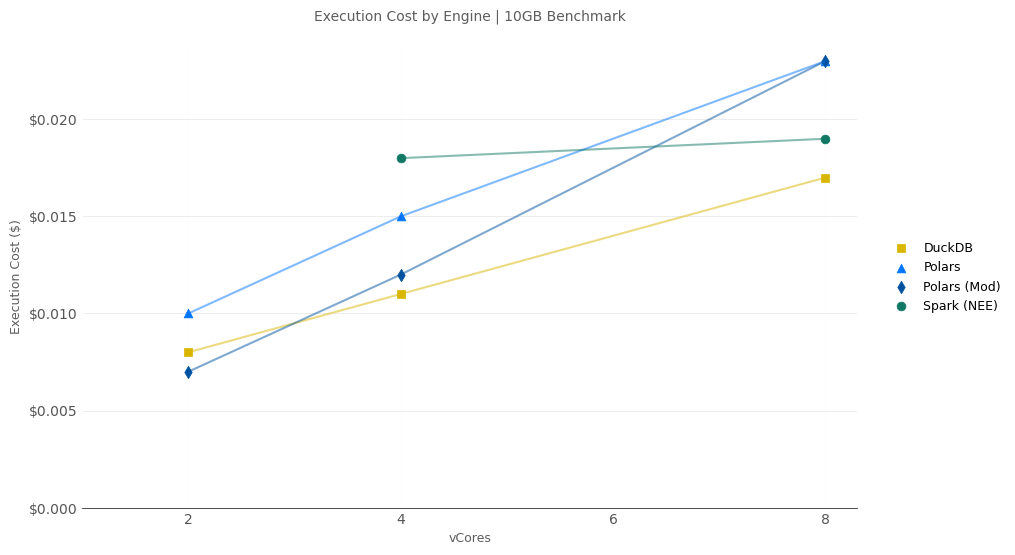
10GB Cost
- Both DuckDB and Polars (Mod) were about 50% cheaper compared to Spark.
- With 8-vCores, Spark w/ NEE and DuckDB have very close job costs ($0.019 vs $0.017).
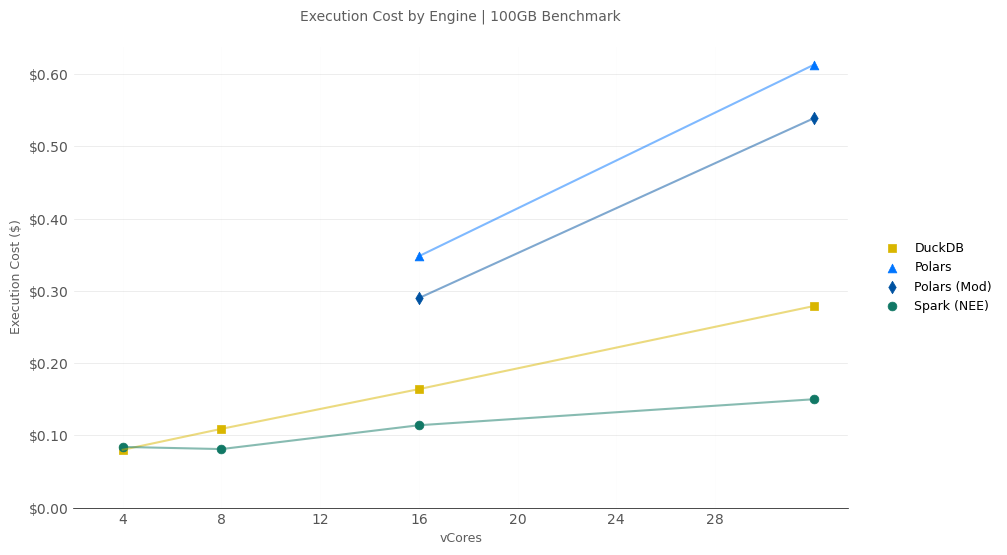
100GB Cost
- With 4-vCores, the DuckDB and Spark jobs cost the same at ~ $0.08.
- With 8-vCores, the cost of the Spark job is unchanged ($0.08) but we were able to cut ~10 minutes off the processing time. Spark was the cheapest.
- As the allocated cores increase, the relative performance gain for Spark is much higher compared to DuckDB and Polars:
- Spark: Compared to the 4-vCore run, Spark w/ 32-vCores was 4.5x faster while the job only costs 2x more.
- DuckDB: Compared to the 4-vCore run, DuckDB w/ 32-vCores was only 2.4x faster while the job costs 3.5x more.
- Polars: Compared to the 16-vCore run, Polars w/ 32-vCores was only ~1.1x faster while costing ~1.9x more.
Development Cost
Selecting a compute engine isn’t just about raw performance—it’s also about how easily and quickly developers can implement solutions. In this evaluation, I focused on two key aspects of development agility: features that impact implementation time and the real-world experience of implementing this benchmark. While the feature evaluation is relatively objective, the implementation evaluation is based on my experience and prior background, making it subjective.
Key Features Impacting Development Cost
| Engine | SQL Interface | DataFrame API | Native Delta Reader | Native Delta Writer | Local Development | Live Monitoring Capabilities | OneLake Auth Setup |
|---|---|---|---|---|---|---|---|
| Spark | Yes | Yes | Yes | Yes | Great | Good but w/ a steep learning curve | Excellent |
| DuckDB | Yes | Yes†† | Yes (via Delta Kernel) | No | Great | Poor | Ok |
| Polars | Yes† | Yes | Yes | Yes (via Delta-rs) | Great | Very Poor | Partial |
† Corrected 12/16/24, Polars does support a SQL interface. This has been decently mature since 0.17.0 (June 2023).
†† Corrected 12/16/24: DuckDB supports a DataFrame-like API through its Relational API and Expression API, introduced in version 0.7.0 (August 2022). Additionally, DuckDB is developing an experimental Spark API, enabling Spark users to run workloads using the DuckDB engine while leveraging the familiar Spark DataFrame API. This feature facilitates seamless migration of lightweight Spark jobs to DuckDB with near-zero code changes, while also allowing users to start with the DuckDB Spark API and transition to the Spark engine as data scales beyond DuckDB’s optimal range.
† Updated 7/17/25, I’d rate local development with Spark as beeing ‘great’ with caveats. After recently working on a contribution to OSS Delta-Spark, I really didn’t know how powerful IntelliJ made developing in Spark. Rich debugging, fantastic linting, dependency tracking, code navigation, etc., it’s quite amazing. The only caveat is that it’s not relevant for PySpark development. I love VS Code, but it’s not quite as rich and out-of-the-box for developing in Spark.
My Analysis
-
SQL and DataFrame API:
While you can use a DataFrame abstraction library like Ibis or SQLFrame, Spark is the only engine I benchmarked that natively supports both SQL and a DataFrame API. Having both presents tremendous flexibility in building data engineering pipelines. Most Spark developers I know heavily use both the SparkSQL and the DataFrame API.Corrected 12/16/24: All engines support both a SQL interface and a DataFrame API, enabling programmatic chaining of transformations that can be executed via lazy evaluation. Spark offers the most robust capabilities through SparkSQL and its DataFrame API. However, Polars (DataFrame-first) and DuckDB (SQL-first) are both making significant progress in enhancing their secondary query construction models. Notably, DuckDB is actively developing a Spark API, allowing Spark users to leverage DuckDB with familiar syntax while providing a seamless path (_fingers crossed, this is still experimental) to switch to Spark’s distributed compute engine as data volumes scale._ - Native Delta Writer:
- DuckDB only supports writing to Delta tables by converting DuckDB DataFrames to another memory format and then using the DeltaLake Python library to perform the write operation. This should be natively supported in time, but today this experience of needing to convert DataFrames and use another writer was quite surprising and took some time to figure out the most optimal way to do it. I first started by converting DuckDB DataFrames to Arrow Tables via
arrow()and ran into OOM issues below 16-vCore. Mim then jumped in and helped me understand that I should be usingrecord_batch()to make this a streaming Arrow DataFrame so that the data gets processed in batches and doesn’t require the full dataset to fit into memory. - Polars supports a native Delta Lake writer via Delta-rs bindings.
- Since both DuckDB and Polars are dependent on the Delta-rs-based DeltaLake Python library for full-featured writes, both are limited by features that have yet to be implemented in Delta-rs, namely deletion vectors. This feature request was reported almost two years ago and is still open. Since deletion vectors are not supported, this means that while DuckDB can read from DV-enabled tables, since both DuckDB and Polars are dependent on Delta-rs, neither can write to such tables. See my post on deletion vectors to understand the importance of merge-on-read.
- DuckDB only supports writing to Delta tables by converting DuckDB DataFrames to another memory format and then using the DeltaLake Python library to perform the write operation. This should be natively supported in time, but today this experience of needing to convert DataFrames and use another writer was quite surprising and took some time to figure out the most optimal way to do it. I first started by converting DuckDB DataFrames to Arrow Tables via
-
Local Development: DuckDB and Polars both win in the ‘local development’ category as the engines are super lightweight and can be run on a local computer with a simple PIP command. Spark is more complex, as it’s not possible to run the Fabric Spark Runtime locally. Therefore, you must connect remotely to a Fabric Spark cluster in VS Code (local or web) to get Fabric Spark-specific features. This experience is getting better every day but is not nearly as simple as running the actual engine locally.
-
Live Monitoring Capabilities: When doing development and you run something, you often might need to check to see what is actually happening. With Spark, you can look in the Spark UI or Fabric UI surfaced telemetry. It’s not perfect by any means, and the learning curve is steep, but once you have the basics figured out, it’s easy enough to check what is running, triage where something might be stuck, or evaluate live running query plans. With DuckDB, there’s a nice tqdm-style progress bar, while with Polars, you’re left to guess what might be going on and when your job might be done.
- OneLake Auth Setup: Note, this is not a critique of the engine itself; this is an evaluation of how natively the engine is integrated to authenticate to OneLake (or ADLS) in Fabric.
- Spark: Easy—you don’t do anything; it just works.
- DuckDB: In hopes of avoiding more complex auth methods, I tried to get token authentication to work. I was blocked on this for a few hours until my colleague Mim Djouallah (he has some great blogs on DuckDB) saved the day and noted that I needed to upgrade to DuckDB version 1.1.3 to use this newer auth method. Once I got this one line of code, everything seamlessly works.
- Polars: At first, I couldn’t get any Polars authentication to work, then Sandeep Pawar showed me that
scan_delta()works with ABFSS paths without needing to specify auth (since it gets a token from env vars). ABFSS does not currently work withscan_parquet(),read_parquet(), and other similar methods. David Browne, however, pointed out that while ABFSS does not work for all methods, relative file paths do work:/lakehouse/default/Filessince it interacts with the OneLake directory via a mount point instead of directly making ABFSS endpoint calls. I got everything working eventually, but this was frustrating to say the least.
Implementation Cost Comparison
| Engine | Learning Curve | Implementation Speed / Workflow Integration |
|---|---|---|
| Spark | Medium | Excellent |
| DuckDB | Medium | Ok |
| Polars | High | Ok |
My Analysis
-
Learning Curve
-
Spark: For myself, and I think for most people as well, learning distributed computing concepts that are critical to being successful with Spark is not a simple task. But once you get the basics, Spark is so mature that it can be hard to get too stuck. Plus, Spark supports SparkSQL, which is one of the best SQL dialects there is.
- DuckDB: I was quite surprised how long it took me to get going with DuckDB. I couldn’t figure out how to authenticate to OneLake until Mim told me I had to update DuckDB to the latest version (1.1.3). Once I was authenticated, I was challenged by how far from straightforward it was to take my PySpark code and refactor it as DuckDB. Beyond the below challenges I stumbled through, DuckDB is almost all SQL, and thus very easy to navigate once you get going:
- No support for natively writing to Delta tables. This includes inserts, running optimize or vacuum. You can only write to Delta tables by converting your DuckDB DataFrame to an Arrow DataFrame and then using the Delta-rs Python library to do the actual write to Delta.
- No support for natively reading from Hive Meta Store. You can use
delta_scan()or register Delta tables as views. Not hard once you understand this. - I originally used the
arrow()method to convert DuckDB DataFrames to Arrow Tables prior to writing to Delta and experienced OOM issues. Mim thankfully showed me that therecord_batch()method should be used instead so that the data is streamed into Arrow format in batches. Quite a cool feature as this allows you to run on very constrained compute and prevent OOM. That said, this was not intuitive and I have yet to find the documentation on this specific method. Is there a reason why you’d usearrow()overrecord_batch()? I have no idea at this point, but it seems likerecord_batch()makes more sense to prevent OOM.
- Polars: Polars is a DataFrame API-centric engine, which is good news for those already comfortable with the Spark DataFrame API. That said, Polars adds additional (and possibly unnecessary?) complexity through the nuance of being able to control the evaluation model based on what methods you use. For example,
read_parquet()is an eager evaluation method, whilescan_parquet()is lazily evaluated. Calling the nativewrite_delta()method to save data to a Delta table will throw an error if you chain it on top of a lazy-evaluated step, so you need to runcollect()first before runningwrite_delta()(but why can’t it just automatically do that???). Oh, and if you want to have the data be streamed for batch processing so that you can process data that is larger than your VM memory, you need to specifycollect(streaming=True). I can see this level of control being fantastic if you live and breathe Polars, but this makes the learning curve pretty steep.
-
-
Workflow Integration / Implementation Speed: I’d define this category as how well the engine works to fit into a typical data engineering workflow. How well is it integrated into the platform? How do features of the engine impact how fast you can get work done, and do the features work with typical data engineering patterns? How complete is the engine itself, or does it feel more like a bolt-on capability?
- Spark: I live and breathe Spark, so the actual implementation was fast for me. For the average user, I’d still suggest it can be pretty fast since things like auth, evaluation, and both reader and writer capabilities are extremely robust. Spark is a standalone, full-featured data processing engine. AL/ML, Graph, structured, semi-structured—Spark can do it all at any data size.
- DuckDB: Ok. Could I swap some DuckDB into normal workflows? Certainly. Would I take additional time to refactor things since DuckDB doesn’t natively support Hive Meta Store and in-memory database concepts are fundamentally different? Yes. The necessity to pass DataFrames from DuckDB to the DeltaLake Writer and so forth is not hard when you get used to it, but the user experience of having to do this isn’t great and does impact the time to implement solutions.
- Polars: Ok. The positive here is that Polars offers a native Delta Lake writer method built on Delta-rs, which provides full-featured writes (including a merge operator), and authentication for OneLake was out-of-the-box—for Delta tables. The downside is that users need to learn the nuances of having tasks evaluated with potentially both eager and lazy evaluation in the same DataFrame. This adds additional work to figure out the most optimal way to code things. That said, like DuckDB, Polars is blazing fast for querying Delta tables, and this is a big positive. I was about to give Polars an OK+ rating but will leave off the plus since I could never get Polars to complete the tests below 16-vCores, even after successfully swapping in DuckDB for the data sampling and unsuccessfully trying to improve write performance for the large table by messing with write batch sizes.
I’d easily give Spark the win in this category.
Engine Maturity and OSS Table Format Compatibility
With Polars, there’s no support for deletion vectors as it’s native Delta reader doesn’t yet support it and it’s writer uses Delta-rs bindings which don’t yet support it as well. While DuckDB does support reading from tables with deletion vectors enabled, via using Delta Kernel bindings, it’s dependency on Delta-rs for writing (after converting the DuckDB DataFrame to Arrow format) also blocks the ability to write to tables with deletion vectors enabled. Deletion vectors are a general best practice setting for Delta tables. If you want to use Polars or DuckDB to read or write to Delta tables, you need to weigh the impact of potential Delta compatibility issues which may block the ability to use newer/optimal Delta features. If your data is super small, not being able to use deletion vectors will have very minimal impact, but as your data volume increases, the potential impact can be significant.
In terms of engine maturity, Polars and DuckDB are both relatively new. In contrast, Spark has been around for over a decade, and we are now approaching GA of the 4th major release. Spark performance continues to improve, Spark capabilities are continuing to expand, and Spark is going nowhere. Just consider some of the upcoming Spark 4.0 features:
- Stored Procedures
- SQL scripting constructs
- Data Source APIs (create your own spark.read class extension)
- Improved error logging
- Variant data types
- Collation support
- Structured logging
…and so much more. All I’m trying to point out is that the Spark community is taking real action on pretty much everything that Spark doesn’t excel at or doesn’t support. In terms of performance, both Fabric and Databricks provide native C++ engines within Spark that allow Spark jobs to run much faster than natively possible with vanilla OSS Spark. Spark is here to stay and continues to improve, so get used to it. :)
New doesn’t mean bad, just that you should be cautious about APIs or syntax changes and that the engine is not going to be as full-featured as an engine like Spark that has been around for over a decade.
Considerations when choosing data processing engines
-
Future data growth: Avoid needing to refactor all code because your data went from small to medium and now you need to rewrite your code as PySpark. If you have small data today and a non-Spark engine only runs 2x faster, I would still use Spark simply so that I don’t have to migrate once my data gets large, as well as to take advantage of the more robust engine capabilities.
-
Skillset of team: Spark is synonymous with data processing. Tons of people know Python, more know basic SQL, but Spark supports both and since it’s been around longer, more people will have this experience. That said, I highly encourage people to learn additional languages, frameworks, and engines, so don’t rule out using DuckDB or Polars because of a potential skillset gap—just be aware there might be some time needed for cross-skilling.
-
Performance: To summarize my performance analysis, Spark can be just as fast, and even faster, for typical data engineering tasks. DuckDB and Polars can be much faster than Spark for lightweight exploration tasks and maintenance operations.
-
Cost: In my benchmark, Spark was as cheap as DuckDB and cheaper than all engines as the allocated vCores scaled. The only two tests where Spark was not the cheapest was the 10GB 2 and 4-vCore benchmarks. Remember that the cost of an engine goes beyond the direct invoice you get from your cloud provider—you should consider the cost of time to learn, the cost for your team to upskill and refactor code, and the cost of longer development cycles through the engine not being as tightly integrated as you’d like.
Where would I use each engine?
Ok, I’ve done the benchmark, but where would I actually use each engine now that I’ve done some basic testing and can confidently say that I’m less ignorant when it comes to single-machine engines?
If I were to optimize for performance, cost, and engine maturity/compatibility, I would do the following (with exceptions):
Primary Spark Use Cases
Any and all “data processing.” Think E.L.T., the steps to extract, load, and transform your data in the Lakehouse architecture.
Primary DuckDB Use Cases
- Interactive and ad-hoc queries
- Data exploration
- Data processing microservices
Primary Polars Use Cases
Honestly, with DuckDB generally outperforming Polars, with zero tuning effort, and less OneLake authentication issues, I’d probably start with DuckDB but certainly wouldn’t rule Polars out, particularly if the use case doesn’t require robust SQL capabilities (one area where DuckDB excels). Polars did win the 10GB 2-vCore test, I’d still give it a fair shot at the same use cases as DuckDB:
- Interactive and ad-hoc queries
- Data exploration
- Data processing microservices
Primary DeltaLake Python Library Use Cases
I added this category since all of the VACUUM and OPTIMIZE operations in my benchmark for Polars and DuckDB technically were just using the DeltaLake Python library. Using a pure Python Notebook, I would use the DeltaLake library for:
- Maintenance operations: Maintenance operations on this library were significantly faster compared to Spark. While you could use this library on a Spark cluster, there’s no need to have your worker nodes sit idle while you run lightweight jobs that only run on the driver node. Rather than running
VACUUMandOPTIMIZE(where the table can fit into VM memory), I would split these maintenance jobs into a Python notebook (2-vCore forVACUUM) and have these jobs complete much faster, all while consuming much less compute.
Here’s a quick visual to summarize where I think each engine makes sense for most Lakehouse architecture use cases.
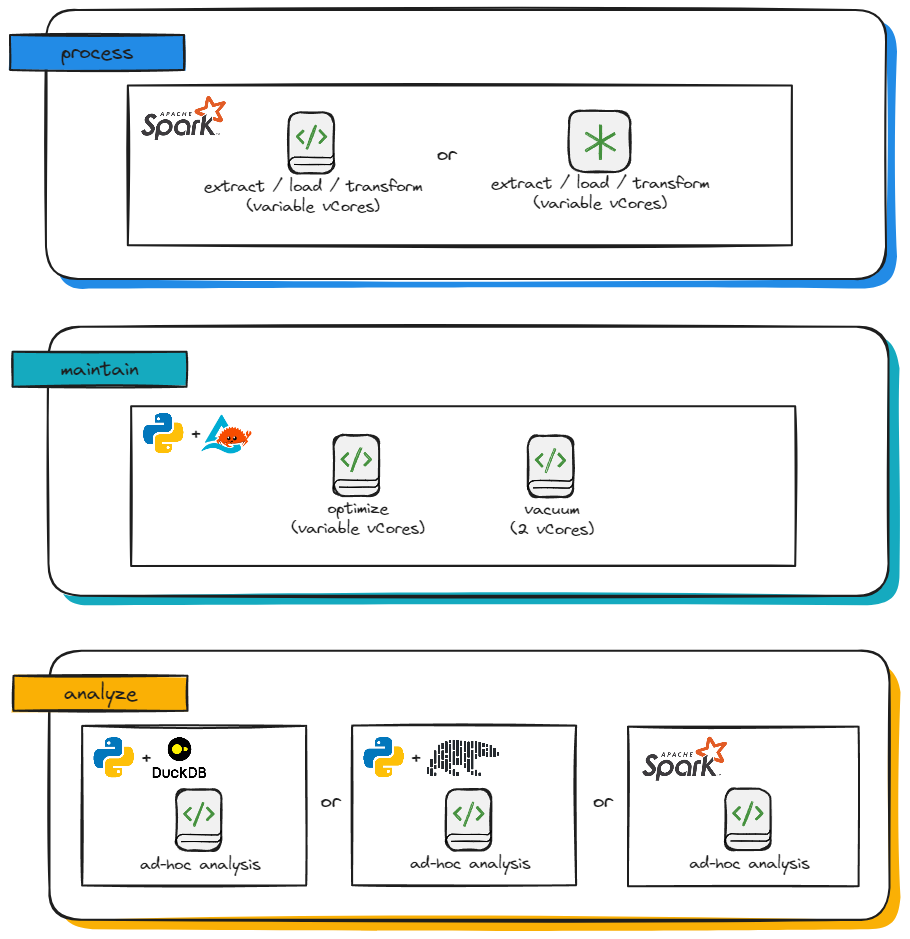
Updated 12/16/24, I added Polars to the image above since it does support a basic SQL interface, thus making it a good candidate for ad-hoc analysis.
My Key Takeaways
- Migrating off of Spark is all hype: I think the whole narrative that you should consider replacing your Spark workloads with DuckDB or Polars if your data is small is all hype. Yes, the engines have certainly earned their place at the table, however Spark is still reigns king for data processing any way you look at it. Sure, DuckDB and Polars can marginally outperform Spark at data processing at the 10GB scale on a 4-vCore (or smaller machine). I think the real story here is this:
- Each engine does something really well, so why not strategically mix and match them to take advantage of where each truly shines. Use Spark for ELT work, use the Rust-based DeltaLake Library on Python for maintenance operations, and use DuckDB or Polars for interactive queries on your small datasets.
-
I now have tremendous respect for Polars and DuckDB: While I prefer developing with Spark because I can seemlessly move between the extremely robust SparkSQL and the DataFrame API as needed, all while being able to scale to process massive amounts of data, DuckDB’s implementation of an in-memory SQL engine is remarkably powerful and supports many use cases—especially when access to a Spark cluster is not readily available. Polars, the newestkid on the block, is rapidly maturing. If its current capabilities are any indication, Polars will undoubtedly make the “which engine should I use” question even more challenging. DuckDB’s investment in developing a Spark API shows that they take Spark seriously and suggests they believe they can capture some of Spark’s market share by simplifying migration to DuckDB and making Spark devs feel at home. While this is likely to happen, I believe native vectorized engines that integrate with Spark and eliminate JVM inefficiencies—such as the Native Execution Engine (Velox & Gluten) in Microsoft Fabric and Photon in Databricks—will continue to make staying within the Spark ecosystem compelling, even for small-data use cases.
-
Performance with Spark more consistently scales as compute scales: I was extremely surprised to find that the performance of DuckDB and Polars was barely impacted by throwing more cores and memory at the benchmark. I’m sure there’s some magic that could be worked to tune things and get more efficient compute utilization as cores are increased, but this just isn’t something you often need to consider with Spark.
-
Memory spill matters!: While you want to avoid it, by default, Spark can spill memory to disk if needed, making it resilient to out-of-memory (OOM) issues. With DuckDB and Polars, I ran into OOM issues (100GB @ 2-vCore for DuckDB and 2, 4, and 8-vCore for Polars)
, and neither engine supports memory spilling to disk to prevent the memory exhaustion causing the VM to crash.Corrected 12/16/24: Both Polars and DuckDB support memory spill to disc, that said, with both having OOM issues I’m guessing that something here is not as efficient (or out-of-the-box) as Spark. I need to do some more triaging here. While memory spill causes Spark to run slower when it happens, it at least greatly reduces the risk of job failures and allows flexibility in compute sizing. -
Distributed computing has compute overhead for task orchestration, but this adds fault tolerance: When DuckDB and Polars VMs crashed due to OOM, that was it—no automatic restart or ability to resume from where it left off. The same would happen with single-node Spark clusters. However, with multi-node Spark clusters (which most production workloads use), fault tolerance is built in. If a worker node crashes for any reason, the driver node maintains the task lineage and processing state so another VM can replace the worker and resume from where the crashed VM left off, without data loss. This may lead to some in-process transformations being reprocessed, but the engine guarantees that data writes are only performed once. See my blog on RDDs vs. DataFrames for more details.
- Consider your specific workload: I designed my benchmark to reflect the typical lakehouse architecture that I see. Given that Spark has the biggest advantage for ELT-type data processing, if your use case involves infrequent small data loads (e.g., monthly), primarily interactive querying, or the necessity for an embedded in-memory database engine, DuckDB could be a great fit—especially for small data volumes.
Lastly, this is just another benchmark—do your own testing.