Last December (2024) I published a blog seeking to explore the question of whether data engineers in Microsoft Fabric should ditch Spark for DuckDb or Polars. Six months have passed and all engines have gotten more mature. Where do things stand? Is it finally time to ditch Spark? Let The Small Data Showdown ‘25 begin!
Goals of This Post
First, let’s revisit the purpose of the benchmark: The objective is to explore data engineering engines available in Fabric to understand whether Spark with vectorized execution (the Native Execution Engine) should be considered in small data architectures.
Beyond refreshing the benchmark to see if any core findings have changed, I do want to expand in a few areas where I got great feedback from the community:
-
Framework Transparency: While I didn’t publish the benchmark code last time, it is now available as part of the beta version of my LakeBench Python library. You can find it on GitHub and PyPi. This blog leverages the
ELTBenchbenchmark run inlightmode. Hopefully, this will help provide additional trust, enable reproducing benchmarks, or at least allow folks to give me tips for how to improve the methodology. If there’s anything you’d do differently for one of the engines, just raise an Issue, or better yet, submit a PR! -
Additional Engines: While I by no means plan to benchmark the gamut of OSS engines, I did get common asks to include Daft and Databricks Photon in the benchmark. I’ve elected to include Daft this time. I am not including Photon as it doesn’t fit the intent of this study: to explore engines available in Fabric for small data workloads.
Benchmark Methodology
If you haven’t already read my initial blog comparing these engines, I’d recommend reading it first. I’ve made a few minor adjustments to the benchmarking methodology this time:
-
To provide better clarity in terms of the scale of data where small engines become definitively faster than Spark, I’m now referencing the size of compressed data rather than the TPC-DS scale factor used. This is particularly important as my benchmark only uses a subset of the TPC-DS tables. The scale factor-to-size mapping (for my lightweight benchmark) is below:
TPC-DS Scale Factor Compressed Size (store_sales, customer, dim_date, item, store) Largest Table Row Count (store_sales) 1GB 140MB 2,879,789 10GB 1.2GB 28,800,501 100GB 12.7GB 288,006,388 As seen above, this differentiation is critical as the size of compressed data processed is about 8x smaller than the scale factor size.
- I switched the order of the
VACUUMandOPTIMIZEphases. Given the intent of runningVACUUMwas to measure the efficiency of vacuuming files, it made more sense to do so afterOPTIMIZEgenerates yet additional files that could be cleaned. - Maintenance jobs,
VACUUMandOPTIMIZE, are included in the detailed phase analysis but excluded from the cumulative execution time for each benchmark scale. There are two reasons for this change:- Spark is the only engine that implements its own native
VACUUMandOPTIMIZEcommand. All of the other single-node engines don’t, and therefore the Delta-rs Python library is used, which results in the difference of execution time between single-machine engines largely being noise. Delta-rs is significantly more efficient at runningVACUUM. If not using Deletion Vectors in Spark, you can also benefit from the same performance. - Maintenance jobs are typically not executed with proportional frequency as present in this 6-phased benchmark. In Spark, I recommend using Auto Compaction to programmatically have compaction run only when needed, synchronously as part of write operations.
VACUUMdoesn’t have a direct impact on performance, so engineers are able to choose a suitable cadence that aligns with their storage cost and data recovery expectations.
- Spark is the only engine that implements its own native
- I added a third benchmark scale to represent ultra-small workloads, this being the 1GB scale factor that translates to 140MB of compressed data.
- In my prior benchmark, I included a modified version of the Polars benchmark that would use DuckDB for the pre-merge sample operation. While Polars still doesn’t support a lazy evaluated sample, I rewrote the code to replicate the output of sampling while still keeping things lazy.
Why This Benchmark Is Relevant
Most benchmarks that are published are too query-heavy and miss the reality that data engineers build complex ELT pipelines to load, clean, and transform data into a shape that is consumable for analytics. TPC-DS and TPC-H particularly fall short in this regard. Yes, they are relevant for bulk data loading and complex queries, but they miss the broader data lifecycle.
My lightweight benchmark proposes that the entire end-to-end data lifecycle which data engineers manage or encounter is relevant: data loading, bulk transformations, incrementally applying transformations, maintenance jobs, and ad-hoc aggregative queries.
Engine Versions Used
| Engine | Version |
|---|---|
| Daft | 0.5.7 |
| Delta-rs | 1.0.2 (0.25.5 for Daft) |
| DuckDB | 1.3.1 |
| Polars | 1.31.0 |
| Spark | Fabric Runtime 1.3 (Spark 3.5, Delta 3.2) |
Spark Core -> Cluster Map
For the single-node engines, there’s nothing to be confused about. 16-vCores means a 16-vCore machine. For Spark, it gets nuanced. The below shows the mapping of cluster config to how many cores were used (including the driver node):
| Core Count | Cluster Config | Executor Cores |
|---|---|---|
| 4 | 4-vCore Single Node | 2 |
| 8 | 8-vCore Single Node | 4 |
| 16 | 3 x 4-vCore Worker Nodes | 12 |
| 32 | 3 x 8-vCore Worker Nodes | 24 |
What Has Changed Over the Last 6 Months?
Before we dig into the results, all engines have shipped various changes since December ‘24. I’ll focus on a few key performance-related features or notable updates of each:
- Fabric Spark:
- The Native Execution Engine was GA’d at Build ‘25. This included a number of optimizations and provides greater coverage for native operators being used (i.e., Deletion Vectors).
- Snapshot Acceleration: Phase 1 of efforts to reduce the cold query overhead of interacting with Delta tables has shipped. This can be enabled via
spark.conf.set("spark.microsoft.delta.snapshot.driverMode.enabled", True). This cuts the overhead of Delta table snapshot generation (the process of identifying and caching the list of files that are active in the version of the table being queried) by ~50%. Note: this feature is currently disabled by default. I recommend enabling this config for all workloads. - Automated Table Statistics: These table-level statistics are collected synchronously as part of write operations to better inform the Catalyst cost-based optimizer in Spark about optimal join strategies. I’ve elected to disable auto stats collection for this benchmark since this is not a “write less, query often” workload that would have clear benefit from table statistics (if running a battery of
SELECTstatements or complex DML, I would certainly enable it).
- DuckDB:
- External File Cache: Shipped as part of 1.3.0, this allows files to be cached on disk to avoid needing to make the more expensive hop to read data from cloud object stores for repeat queries to the same files. This is fundamentally the same feature as the Intelligent Cache in Fabric Spark.
- The DuckDB extension for Delta shipped a number of perf improvements around file skipping and pushdown.
- Still no native ability to write to Delta tables, but we can continue to use the Delta-rs Python library.
- Polars:
- Polars shipped a new streaming engine: https://github.com/pola-rs/polars/issues/20947
- Since v1.14, the Polars Delta reader now leverages the Polars Parquet reader and is thus no longer dependent on Delta-rs for reading Delta tables.
- Polars still doesn’t support reading and writing to tables with Deletion Vectors.
- Daft:
- Daft’s new streaming engine, codename “Swordfish,” is default in v0.4: https://blog.getdaft.io/p/swordfish-for-local-tracing-daft-distributed
- Delta-rs:
- Still no Deletion Vector support :(. Make noise here: https://github.com/delta-io/delta-rs/issues/1094
Where Do Things Stand?
On 7/2/25 I reran the benchmark with a few changes:
- Delta-rs 1.0.2 was used instead of 0.18.2.
- ELTBench was updated to use the same exact sudo sampling logic as the input to the merge statement. Since Polars doesn’t support a Lazy sample function it used its own custom sampling logic. All of the engines now use the same exact DIY sampling logic.
- Polars was upgraded to 1.3.1
With the above changes, particularly the upgrade to Delta-rs v1, the results generally had the non-distributed engines improve the most (the Delta-rs rust engine in v1 is now mature enough to not see performance regressions whereas in 0.18.2 the pyarrow engine was typically faster or at least prevented OOM).
140MB Scale
At the 140MB scale (not tested in my benchmark from December ‘24), all single-machine engines are quite close in performance and handily beat Spark.
- Polras is ~ 2x faster than DuckDB and Daft at 2 and 4-vCores. At 8-vCores all non-distributed engines are decently close.
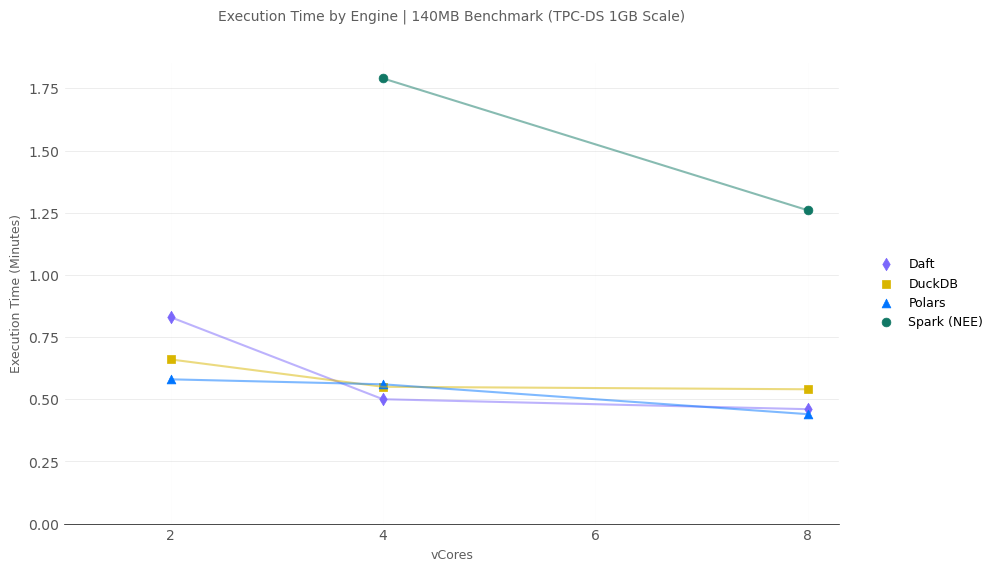
140MB Scale @ 4-vCores - Phase Detail
- Spark is significantly (2-5x) slower at all write operations.
- Polars somehow ran the ad-hoc query in 146 ms. It barely shows up on the chart, this is absolately mind blowing!
- Spark took the bronze at completing the ad-hoc query, beating DuckDB. Somewhat suprising given how much faster the single-machine engines were at the write operations.
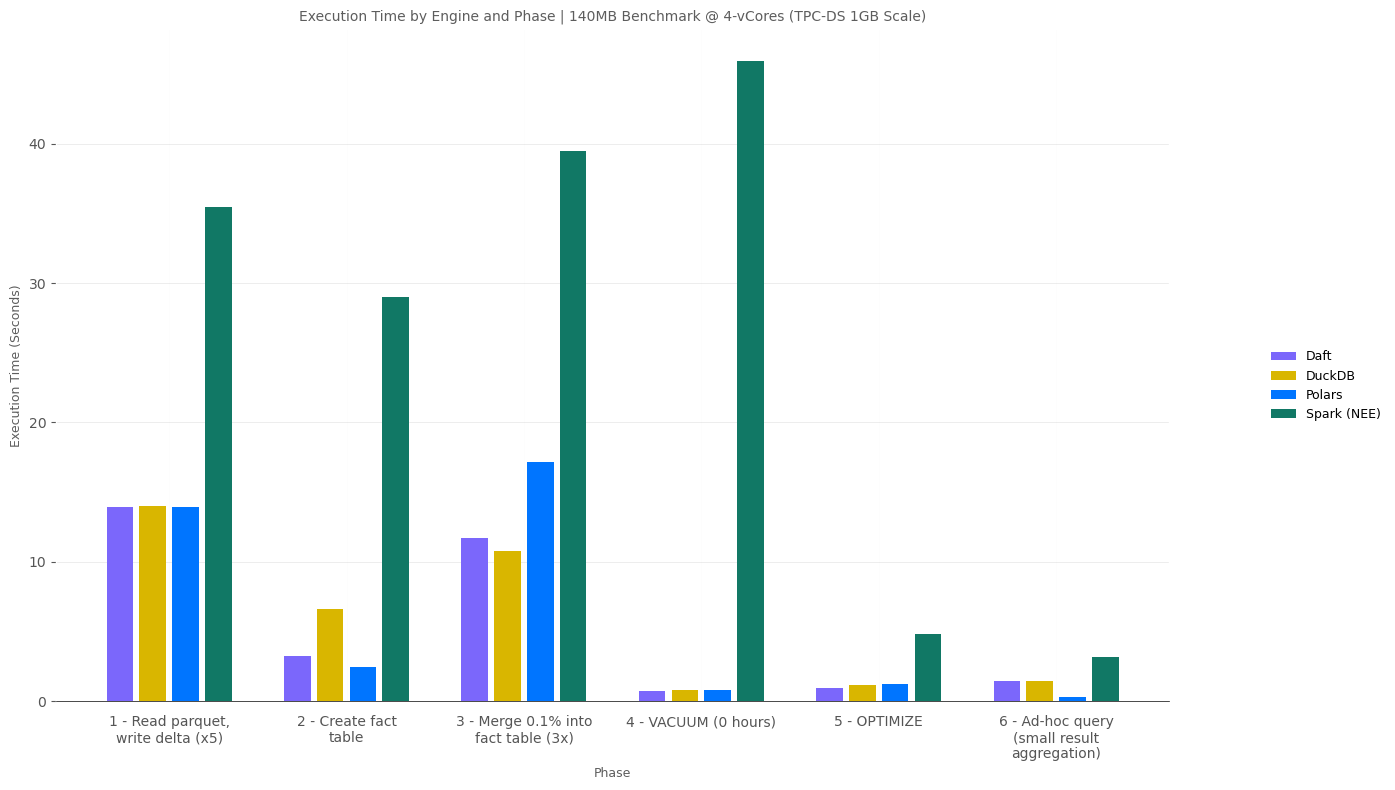
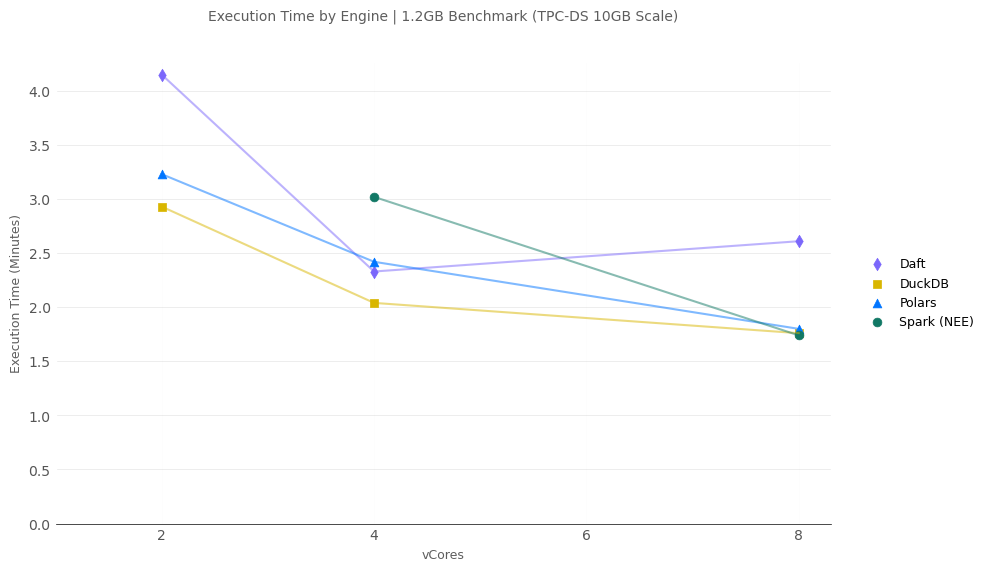
1.2GB Scale
We are beginning to see that Spark is starting to catch up in aggregate but still has a ways to go.
- Fabric Spark beats Daft, the “Spark killer”, at 8cores but DuckDB and particularly Polars still have a massive advantage.
- While Fabric Spark doesn’t give the option to run Spark on 2-vCores, at 4-vCores Spark is the slowest but its worth noting that only 1/2 of the nodes cores are allocated as executor cores in Single node mode, meaning that Spark is operation at 1/2 the compute power.
1.2GB Scale @ 8-vCores - Phase Detail
Looking at the detail by phase, a couple observations:
- Again we see that Spark is not the fastest at any of the phases, however it’s also not the slowest. Fabric Spark beat DuckDB at the ad-hoc query, and beat Daft at 2 of 3 write phases.
- I’m again stunned by Polars…
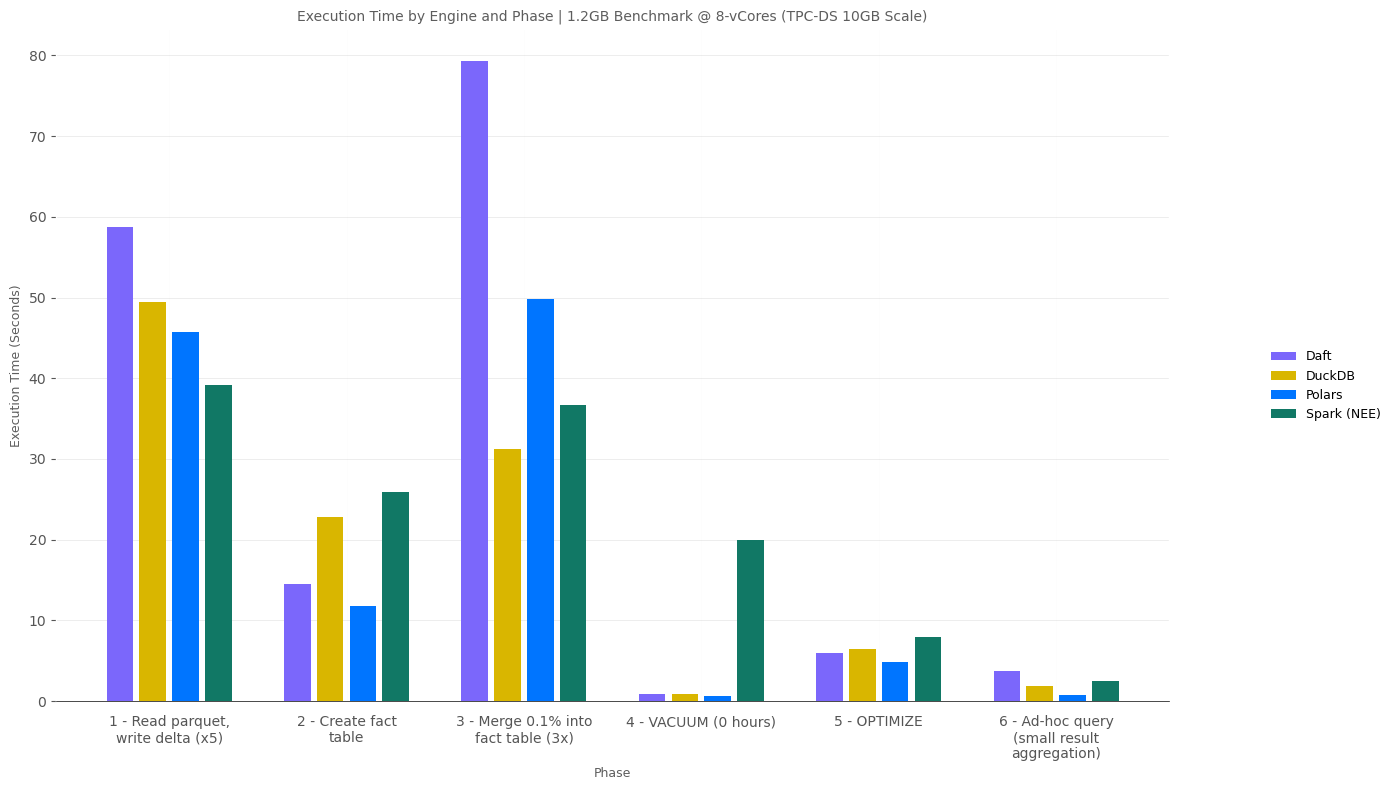
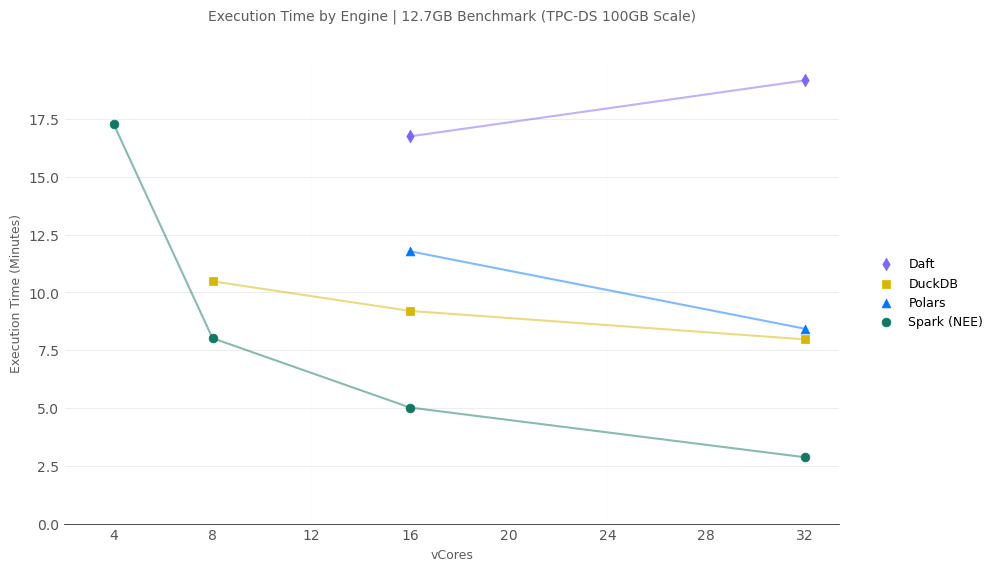
12.7GB Scale
Now at 12.7GB scale, we see Fabric Spark with the Native Execution Engine start to flex its muscles as the data scale grows to what I’d consider the peark of the “small data” range:
- Spark was the fastest engine, with DuckDB close behind, to complete all compute scales without running into out-of-memory (OOM).
- Polars leaves me perplexed. It somehow beat Spark at the 16 and 32-vCore compute scale, yet it also ran into OOM below 16-vCores.
- DuckDB was the only non-distributed engine to complete the benchmark at 2-vCores.
- I will again highlight that Spark at 4 and 8-vCores is running in single-node mode and only 1/2 of the machines cores and RAM are allocated to executors. The reason I point this out again is that this is a platform configuration (which conceptually could change) and at only 50% of the available compute being used, it is on-par or beating non-distributed engines. If all cores were allocated to executors I’d expect Spark to decisively win this scale and compute size.
- Lastly, a note on the importance of upgrading your composible data stack (the reality that Delta-rs is used to write DuckDB in-memory data to Delta format): before upgrading to Delta-rs v1, DuckDB ran into OOM at the 2 and 4-vCore scale. After upgrading, with DuckDB being able to leverage the more efficient Rust based engine in Delta-rs it had no problem running the tests at 2 and 4-vCore compute scales.
- Daft trails the competition by a wide margin. I absolvely love Daft’s vision, but I’m just not seeing it in the perf department.
Note: the 'PyArrow' Delta-rs engine was used instead of the newer 'Rust' engine for engines that don't directly support writing to Delta (in version 0.18.2). The Rust engine had nearly the same performance but resulted in OOM at 8-vCores, whereas PyArrow didn't have any issues at this compute size.In Delta-rs V1 the Rust engine is the only engine option.
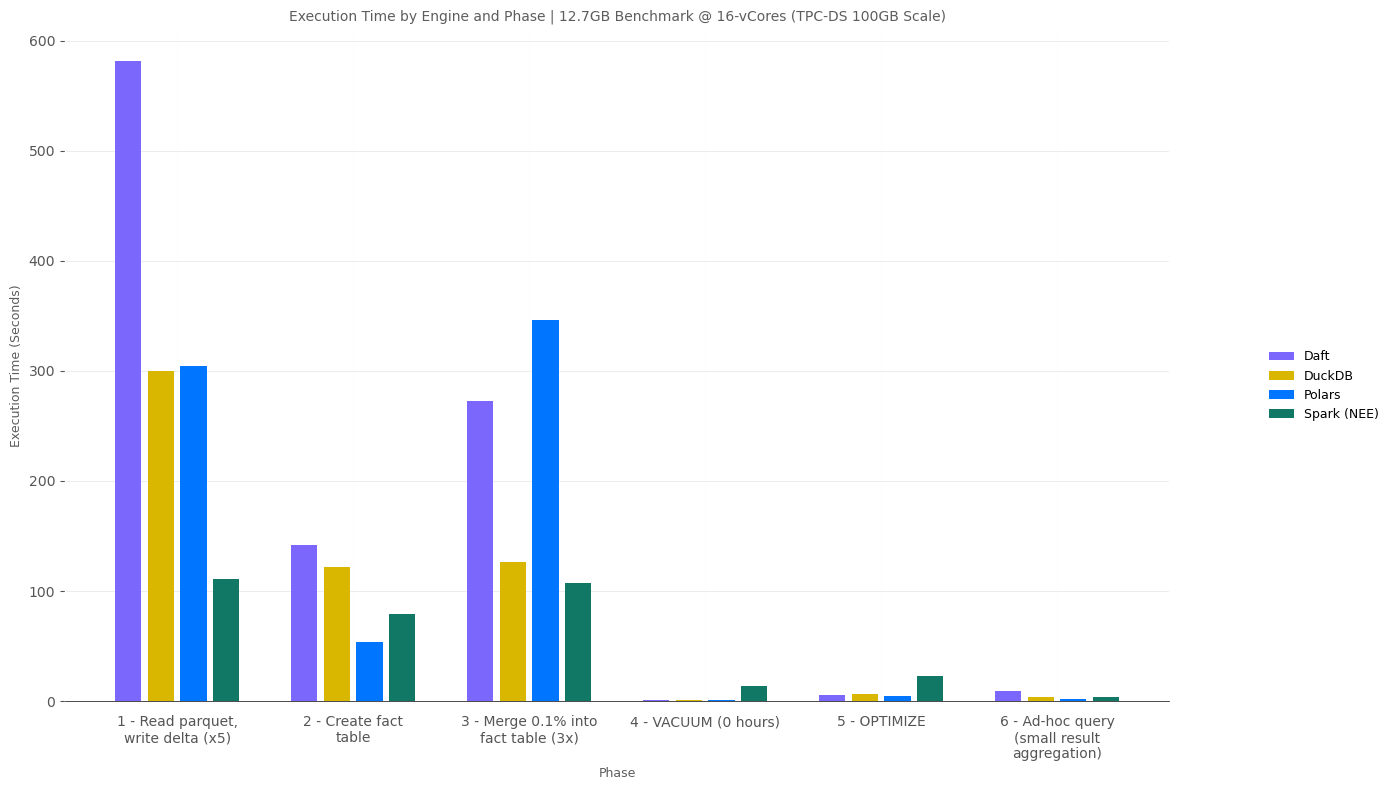
12.7GB Scale @ 16-vCores - Phase Detail
Looking at the detail from the 16-vCore tests:
- Polars and Daft tie at completing the ad-hoc query.
- Fabric Spark comes in 2nd place at 2 of 3 write phases.
- Polars was either the fastest or tied at every phase.
- Daft took significantly longer to load the 5 Delta tables.
General Observations
- As noted, the last time I ran this benchmark,
VACUUMis significantly slower in Spark. On the odd chance that you aren’t using Deletion Vectors in Fabric, you could use the Delta-rs library to vacuum your tables. OPTIMIZEis generally faster via Delta-rs. The reason for this is primarily that the Native Execution Engine doesn’t support the entire compaction code path and results in two fallbacks to execution on the JVM. I anticipate this will get much faster once we ship support for this code path.- In all benchmarks where Polars didn’t run into OOM, it was consistently the fastest engine.
- Both Spark and DuckDB where the only engines to complete the entire battery of benchmark scenarios with not a single out-of-memory exception. Maybe unsuprising for DuckDB which isn’t JVM based, but for Spark this is the result of the Native Execution Engine’s highly efficient use of columnar memory, outside the JVM. Where JVM memory is needed for any fallbacks (i.e., when running
OPTIMIZE), memory is dynamically allocated between on-heap and off-heap as needed. - Spark consistently sees greater relative improvement in execution time via adding more compute as compared to the other engines.
Which Engine Gained the Most Ground Since December ‘24?
While all engines got much faster, Polars followed by Fabric Spark with the Native Execution Engine saw the greatest performance gains relative to December ‘24. Polars got so much faster that I honestly questioned whether or not there was a bug in my code resulting in less data being written or LazyFrames that were never triggered.
So Is It Time to Ditch Spark?
While the non-distributed engines, particularly Polars and DuckDB are very competitive or even faster than Spark at most small data benchmarks, there’s a few reasons why I would still use Spark with the Native Execution Engine in most small data scenarios:
- Maturity: What the perf numbers don’t highlight is the amount of work involved to get the benchmark to run successfully. Daft, DuckDB, and Polars all required significantly more time than Fabric Spark to get the same code from December ’24 running on the latest engine versions. I didn’t have to change a single thing in Spark — it just ran. And with zero effort (thanks to the engineering investment from Microsoft), my code ran ~2x faster.
- Daft had all sorts of issues with authenticating to storage (GitHub Issue: 4692). After a few hours I gave up and reverted to using ADLS Gen2. Daft also broke after upgrading to Delta-rs v1, as it references a method that no longer exists in v1 (GitHub Issue: 4677). On the code front, the only feature support issue I had with this benchmark was that it doesn’t have a random value function. On adding support for TPC-DS and TPC-H benchmarks in LakeBench, I’ve found that Daft SQL is very immature — it gets tripped up easily (no support for
CROSS JOINs and frequent data type casting issues that other engines don’t have). - Polars code required some light refactoring to use the new streaming engine. Polars also required me to refactor the existing benchmark as it doesn’t support
LazyFrame.sampleand doesn’t have a random value function. My only other issue was navigating the OOM errors. - DuckDB also had periodic issues authenticating to storage. At the larger data scale, tasks seemed to get stuck — almost like the auto-generated token was no longer valid — but would just keep running until I manually canceled the job. Upgrading to Delta-rs v1 required removing the
engineparameter and possibly introduced this error:InvalidInputException: Invalid Input Error: Attempting to execute an unsuccessful or closed pending query result. Refactoring the code to explicitly establish a DuckDB connection and create my own storage secret fixed this, but it’s extremely hard to tell what the exact root cause was — DuckDB, Delta-rs, or ultimately a Fabric token issue.
- Daft had all sorts of issues with authenticating to storage (GitHub Issue: 4692). After a few hours I gave up and reverted to using ADLS Gen2. Daft also broke after upgrading to Delta-rs v1, as it references a method that no longer exists in v1 (GitHub Issue: 4677). On the code front, the only feature support issue I had with this benchmark was that it doesn’t have a random value function. On adding support for TPC-DS and TPC-H benchmarks in LakeBench, I’ve found that Daft SQL is very immature — it gets tripped up easily (no support for
-
Triaging Support: Imagine that you have a query that has been running for a while and you just want to know what’s going on or what’s actually running at that moment. In Spark, you can simply look at the in-cell task metrics to see that things are happening or open the Spark UI to get full details on what’s currently running and what has run. For the non-distributed engines, I had multiple cases of wanting to know what it was actively doing — and there’s zero visibility. Fine for any operation that runs in <1 minute, but for anything longer, the lack of visibility is just like rolling dice, hoping you wrote the code well and that your compute size will work out. Want to look at logs to see what’s already happened or the details of a prior session? Good luck.
-
DIY Composable Data Systems == More Management Overhead: First of all, I love the idea of the composable data stack — if you aren’t familiar with it, give Wes McKinney’s blog a read. Having pluggable components in your stack makes it more flexible and allows you to leverage the best of open source. Fabric takes advantage of this by using Velox and Apache Gluten as foundational components of the Native Execution Engine to accelerate Spark. But this is all managed for users — no need to test and choose versions, perform upgrades, roll out changes, etc. I’m beginning to love DuckDB (and Polars — I’m blown away by its recent perf gains), but what I don’t love is the necessity to stitch together different technologies just to get something simple to work. DuckDB is the most robust non-distributed engine at reading Delta format, but it doesn’t natively write to Delta. You can cast DuckDB relations to Arrow format so that Delta-rs can take over and do the write, but there are at least four different ways to do it (
arrow,fetch_record_batch,fetch_arrow_reader,record_batch) and the documentation is poor at explaining the differences and best practices. What DuckDB natively supports is fantastic, but when you need to complete the whole E2E data lifecycle, things start to get fragmented. As your stack gets fragmented with different technologies, you then need to manage compatibility — e.g., LakeBench installs Delta-rs v1.0.N for Polars and DuckDB but v0.25.5 for Daft. -
Delta Feature Support: I look forward to the day when all these engines fully support features like Deletion Vectors for both reads and writes. Currently, DuckDB supports reading Deletion Vectors, but Delta-rs lacks support for writing them. Polars and Daft, as far as I know, do not support either read or write paths. In LakeBench, the telemetry logging table is configured with Deletion Vectors disabled to ensure compatibility across all engines for writing logs. Relying on the lowest common denominator of features can be quite limiting and frustrating.
- Future Data Growth: In most cases, small data will grow into big data — or at least into data of a scale where distributed engines are necessary for decent perf. If you have small data today, consider the rate of possible growth and whether it makes sense to start with distributed-capable compute like Spark. You can start on single-node configs to keep costs low and seamlessly scale out to multiple nodes as your data volumes grow.
Just to add some data growth sanity to this benchmark, let’s consider if our largest scale tested grew 10x from 12.7GB to ~ 127GB (2.8B row transaction table).
Which engine wins at the 127GB scale?
All engines were tested on 16, 32, and 64 total cores (Spark w/ 7x8-vCore Workers + 1 8vCore driver).
- DuckDB was the only non-distributed engine to complete the benchmark but did results in OOM at 16-vCores. Polars ran into OOM just minutes into the job. Daft ran for over and hour and then failed.
- Spark was the only engine to complete the 127GB scale on all compute sizes.
- Spark was ~ 3.5x faster than DuckDB at 32-vCores
- Spark was ~ 6x faster than DuckDB at 64-vCores
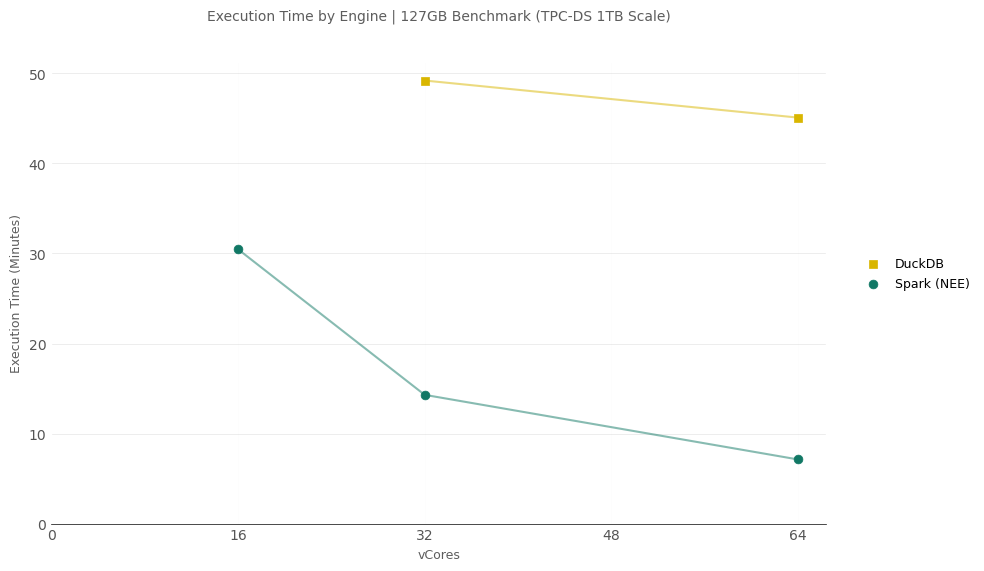
There we go, now we have out dose of “medium data” reality, Spark is still king. I was starting to sweat a bit there as the small data tests completed 😅.
So what’s my guidance here?
If you have uber-small data (i.e. up to 1GB compressed), you can be quite successful reducing costs and improving performance by using a non-distributed engine like Polars, DuckDB, or Daft. If your data is between 1GB and 10GB compressed, Spark with vectorization via the Native Execution Engine is super competitive perf-wise, much more fault- and constrained-memory-tolerant, and thus entirely worth leveraging. While DuckDB, Polars, and Daft all leverage columnar memory and vectorized execution via either C++ or Rust implementations, Fabric Spark with the Native Execution Engine (via Velox and Apache Gluten) does as well. And guess what? There are plenty of additional optimizations still planned for Fabric Spark and the Native Execution Engine that will continue to improve performance in the coming year. I look forward to seeing where things stand in 2026 😁.
Regardless of your current data scale, consider potential data growth, maturity, and feature support so you aren’t setting yourself up for a required engine replatform as your data grows beyond the bounds of being small or you require a more mature set of capabilities.